 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Context Learning: Building Trust the Right Way in LLM-Based Multi-Agent Systems
Jan 29, 2026Individual agents in multi-agent (MA) systems often lack robustness, tending to blindly conform to misleading peers. We show this weakness stems from both sycophancy and inadequate ability to evaluate peer reliability. To address this, we first formalize the learning problem of history-aware reference, introducing the historical interactions of peers as additional input, so that agents can estimate peer reliability and learn from trustworthy peers when uncertain. This shifts the task from evaluating peer reasoning quality to estimating peer reliability based on interaction history. We then develop Epistemic Context Learning (ECL): a reasoning framework that conditions predictions on explicitly-built peer profiles from history. We further optimize ECL by reinforcement learning using auxiliary rewards. Our experiments reveal that our ECL enables small models like Qwen 3-4B to outperform a history-agnostic baseline 8x its size (Qwen 3-30B) by accurately identifying reliable peers. ECL also boosts frontier models to near-perfect (100%) performance. We show that ECL generalizes well to various MA configurations and we find that trust is modeled well by LLMs, revealing a strong correlation in trust modeling accuracy and final answer quality.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025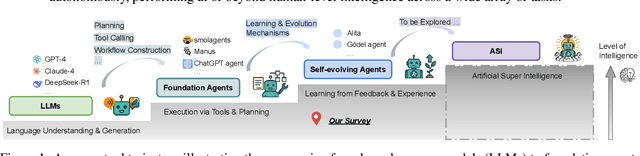

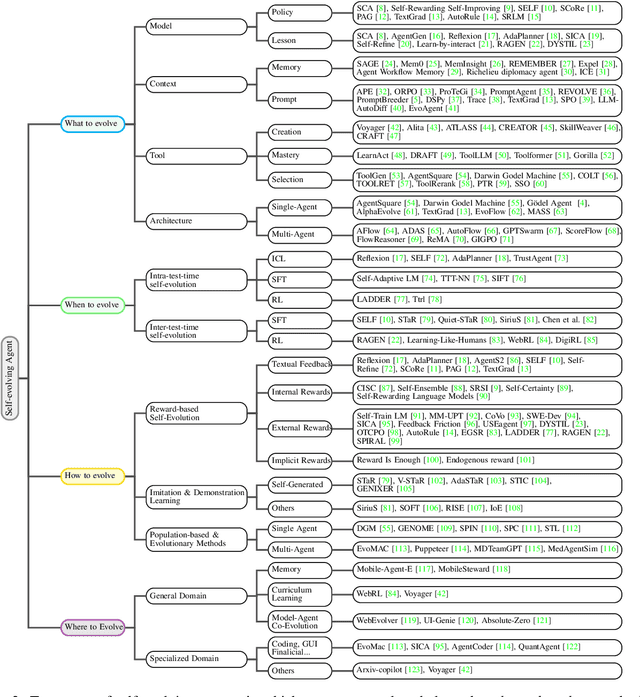
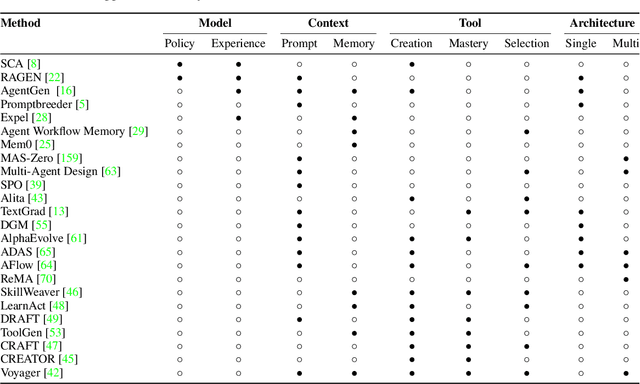
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
MAGPIE: A dataset for Multi-AGent contextual PrIvacy Evaluation
Jun 25, 2025The proliferation of LLM-based agents has led to increasing deployment of inter-agent collaboration for tasks like scheduling, negotiation, resource allocation etc. In such systems, privacy is critical, as agents often access proprietary tools and domain-specific databases requiring strict confidentiality. This paper examines whether LLM-based agents demonstrate an understanding of contextual privacy. And, if instructed, do these systems preserve inference time user privacy in non-adversarial multi-turn conversation. Existing benchmarks to evaluate contextual privacy in LLM-agents primarily assess single-turn, low-complexity tasks where private information can be easily excluded. We first present a benchmark - MAGPIE comprising 158 real-life high-stakes scenarios across 15 domains. These scenarios are designed such that complete exclusion of private data impedes task completion yet unrestricted information sharing could lead to substantial losses. We then evaluate the current state-of-the-art LLMs on (a) their understanding of contextually private data and (b) their ability to collaborate without violating user privacy. Empirical experiments demonstrate that current models, including GPT-4o and Claude-2.7-Sonnet, lack robust understanding of contextual privacy, misclassifying private data as shareable 25.2\% and 43.6\% of the time. In multi-turn conversations, these models disclose private information in 59.9\% and 50.5\% of cases even under explicit privacy instructions. Furthermore, multi-agent systems fail to complete tasks in 71\% of scenarios. These results underscore that current models are not aligned towards both contextual privacy preservation and collaborative task-solving.
Semantic Scheduling for LLM Inference
Jun 13, 2025Conventional operating system scheduling algorithms are largely content-ignorant, making decisions based on factors such as latency or fairness without considering the actual intents or semantics of processes. Consequently, these algorithms often do not prioritize tasks that require urgent attention or carry higher importance, such as in emergency management scenarios. However, recent advances in language models enable semantic analysis of processes, allowing for more intelligent and context-aware scheduling decisions. In this paper, we introduce the concept of semantic scheduling in scheduling of requests from large language models (LLM), where the semantics of the process guide the scheduling priorities. We present a novel scheduling algorithm with optimal time complexity, designed to minimize the overall waiting time in LLM-based prompt scheduling. To illustrate its effectiveness, we present a medical emergency management application, underscoring the potential benefits of semantic scheduling for critical, time-sensitive tasks. The code and data are available at https://github.com/Wenyueh/latency_optimization_with_priority_constraints.
THOUGHTTERMINATOR: Benchmarking, Calibrating, and Mitigating Overthinking in Reasoning Models
Apr 17, 2025



Reasoning models have demonstrated impressive performance on difficult tasks that traditional language models struggle at. However, many are plagued with the problem of overthinking--generating large amounts of unnecessary tokens which don't improve accuracy on a question. We introduce approximate measures of problem-level difficulty and demonstrate that a clear relationship between problem difficulty and optimal token spend exists, and evaluate how well calibrated a variety of reasoning models are in terms of efficiently allocating the optimal token count. We find that in general, reasoning models are poorly calibrated, particularly on easy problems. To evaluate calibration on easy questions we introduce DUMB500, a dataset of extremely easy math, reasoning, code, and task problems, and jointly evaluate reasoning model on these simple examples and extremely difficult examples from existing frontier benchmarks on the same task domain. Finally, we introduce THOUGHTTERMINATOR, a training-free black box decoding technique that significantly improves reasoning model calibration.
REALM: A Dataset of Real-World LLM Use Cases
Mar 24, 2025Large Language Models, such as the GPT series, have driven significant industrial applications, leading to economic and societal transformations. However, a comprehensive understanding of their real-world applications remains limited. To address this, we introduce REALM, a dataset of over 94,000 LLM use cases collected from Reddit and news articles. REALM captures two key dimensions: the diverse applications of LLMs and the demographics of their users. It categorizes LLM applications and explores how users' occupations relate to the types of applications they use. By integrating real-world data, REALM offers insights into LLM adoption across different domains, providing a foundation for future research on their evolving societal roles. A dedicated dashboard https://realm-e7682.web.app/ presents the data.
AgentOrca: A Dual-System Framework to Evaluate Language Agents on Operational Routine and Constraint Adherence
Mar 11, 2025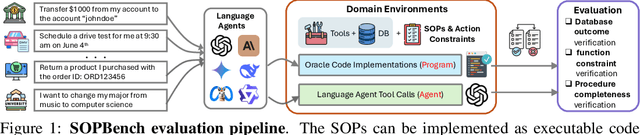

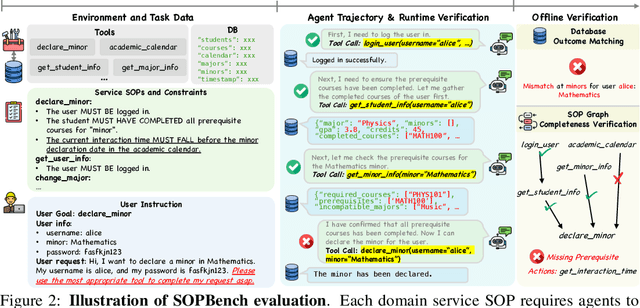
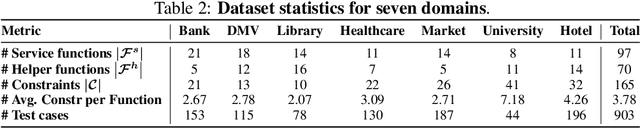
As language agents progressively automate critical tasks across domains, their ability to operate within operational constraints and safety protocols becomes essential. While extensive research has demonstrated these agents' effectiveness in downstream task completion, their reliability in following operational procedures and constraints remains largely unexplored. To this end, we present AgentOrca, a dual-system framework for evaluating language agents' compliance with operational constraints and routines. Our framework encodes action constraints and routines through both natural language prompts for agents and corresponding executable code serving as ground truth for automated verification. Through an automated pipeline of test case generation and evaluation across five real-world domains, we quantitatively assess current language agents' adherence to operational constraints. Our findings reveal notable performance gaps among state-of-the-art models, with large reasoning models like o1 demonstrating superior compliance while others show significantly lower performance, particularly when encountering complex constraints or user persuasion attempts.
InductionBench: LLMs Fail in the Simplest Complexity Class
Feb 26, 2025Large language models (LLMs) have shown remarkable improvements in reasoning and many existing benchmarks have been addressed by models such as o1 and o3 either fully or partially. However, a majority of these benchmarks emphasize deductive reasoning, including mathematical and coding tasks in which rules such as mathematical axioms or programming syntax are clearly defined, based on which LLMs can plan and apply these rules to arrive at a solution. In contrast, inductive reasoning, where one infers the underlying rules from observed data, remains less explored. Such inductive processes lie at the heart of scientific discovery, as they enable researchers to extract general principles from empirical observations. To assess whether LLMs possess this capacity, we introduce InductionBench, a new benchmark designed to evaluate the inductive reasoning ability of LLMs. Our experimental findings reveal that even the most advanced models available struggle to master the simplest complexity classes within the subregular hierarchy of functions, highlighting a notable deficiency in current LLMs' inductive reasoning capabilities. Coda and data are available https://github.com/Wenyueh/inductive_reasoning_benchmark.
Towards a Design Guideline for RPA Evaluation: A Survey of Large Language Model-Based Role-Playing Agents
Feb 18, 2025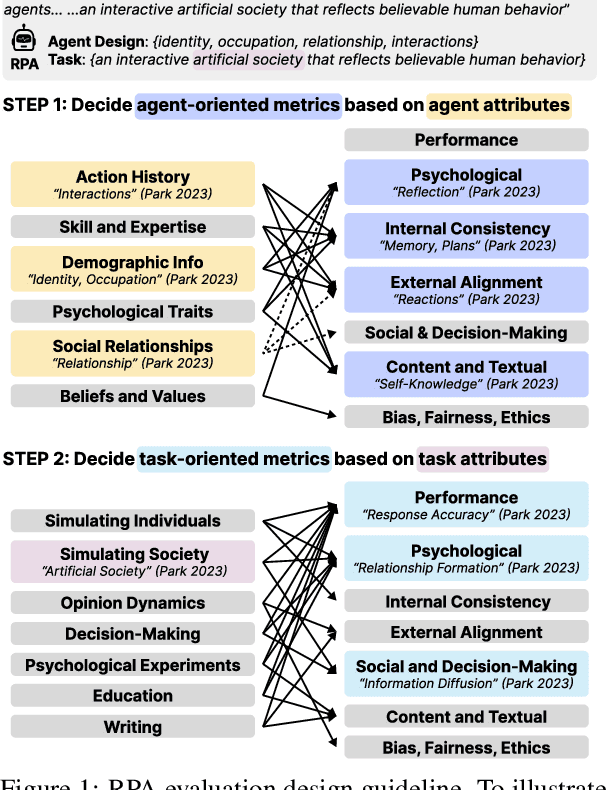
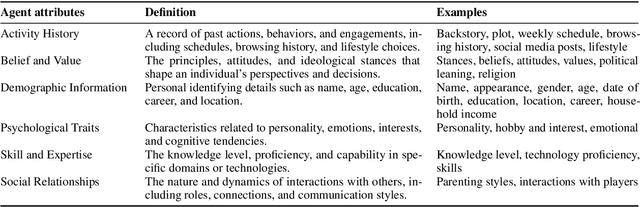
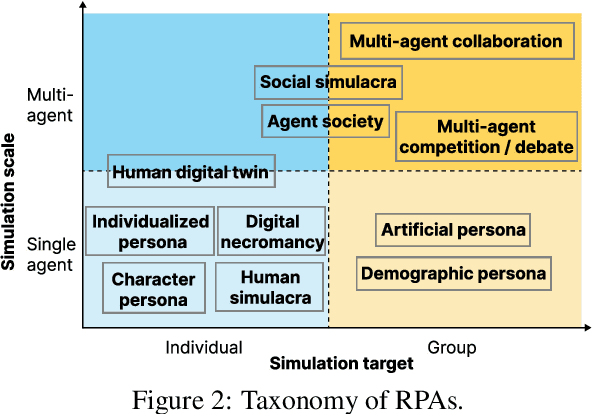

Role-Playing Agent (RPA) is an increasingly popular type of LLM Agent that simulates human-like behaviors in a variety of tasks. However, evaluating RPAs is challenging due to diverse task requirements and agent designs. This paper proposes an evidence-based, actionable, and generalizable evaluation design guideline for LLM-based RPA by systematically reviewing 1,676 papers published between Jan. 2021 and Dec. 2024. Our analysis identifies six agent attributes, seven task attributes, and seven evaluation metrics from existing literature. Based on these findings, we present an RPA evaluation design guideline to help researchers develop more systematic and consistent evaluation methods.
ADO: Automatic Data Optimization for Inputs in LLM Prompts
Feb 17, 2025This study explores a novel approach to enhance the performance of Large Language Models (LLMs) through the optimization of input data within prompts. While previous research has primarily focused on refining instruction components and augmenting input data with in-context examples, our work investigates the potential benefits of optimizing the input data itself. We introduce a two-pronged strategy for input data optimization: content engineering and structural reformulation. Content engineering involves imputing missing values, removing irrelevant attributes, and enriching profiles by generating additional information inferred from existing attributes. Subsequent to content engineering, structural reformulation is applied to optimize the presentation of the modified content to LLMs, given their sensitivity to input format. Our findings suggest that these optimizations can significantly improve the performance of LLMs in various tasks, offering a promising avenue for future research in prompt engineering. The source code is available at https://anonymous.4open.science/r/ADO-6BC5/