 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabular LLMs for Interpretable Few-Shot Alzheimer's Disease Prediction with Multimodal Biomedical Data
Mar 17, 2026Accurate diagnosis of Alzheimer's disease (AD) requires handling tabular biomarker data, yet such data are often small and incomplete, where deep learning models frequently fail to outperform classical methods. Pretrained large language models (LLMs) offer few-shot generalization, structured reasoning, and interpretable outputs, providing a powerful paradigm shift for clinical prediction. We propose TAP-GPT Tabular Alzheimer's Prediction GPT, a domain-adapted tabular LLM framework built on TableGPT2 and fine-tuned for few-shot AD classification using tabular prompts rather than plain texts. We evaluate TAP-GPT across four ADNI-derived datasets, including QT-PAD biomarkers and region-level structural MRI, amyloid PET, and tau PET for binary AD classification. Across multimodal and unimodal settings, TAP-GPT improves upon its backbone models and outperforms traditional machine learning baselines in the few-shot setting while remaining competitive with state-of-the-art general-purpose LLMs. We show that feature selection mitigates degradation in high-dimensional inputs and that TAP-GPT maintains stable performance under simulated and real-world missingness without imputation. Additionally, TAP-GPT produces structured, modality-aware reasoning aligned with established AD biology and shows greater stability under self-reflection, supporting its use in iterative multi-agent systems. To our knowledge, this is the first systematic application of a tabular-specialized LLM to multimodal biomarker-based AD prediction, demonstrating that such pretrained models can effectively address structured clinical prediction tasks and laying the foundation for tabular LLM-driven multi-agent clinical decision-support systems. The source code is publicly available on GitHub: https://github.com/sophie-kearney/TAP-GPT.
Topo-R1: Detecting Topological Anomalies via Vision-Language Models
Mar 13, 2026Topological correctness is crucial for tubular structures such as blood vessels, nerve fibers, and road networks. Existing topology-preserving methods rely on domain-specific ground truth, which is costly and rarely transfers across domains. When deployed to a new domain without annotations, a key question arises: how can we detect topological anomalies without ground-truth supervision? We reframe this as topological anomaly detection, a structured visual reasoning task requiring a model to locate and classify topological errors in predicted segmentation masks. Vision-Language Models (VLMs) are natural candidates; however, we find that state-of-the-art VLMs perform nearly at random, lacking the fine-grained, topology-aware perception needed to identify sparse connectivity errors in dense structures. To bridge this gap, we develop an automated data-curation pipeline that synthesizes diverse topological anomalies with verifiable annotations across progressively difficult levels, thereby constructing the first large-scale, multi-domain benchmark for this task. We then introduce Topo-R1, a framework that endows VLMs with topology-aware perception via two-stage training: supervised fine-tuning followed by reinforcement learning with Group Relative Policy Optimization (GRPO). Central to our approach is a topology-aware composite reward that integrates type-aware Hungarian matching for structured error classification, spatial localization scoring, and a centerline Dice (clDice) reward that directly penalizes connectivity disruptions, thereby jointly incentivizing semantic precision and structural fidelity. Extensive experiments demonstrate that Topo-R1 establishes a new paradigm for annotation-free topological quality assessment, consistently outperforming general-purpose VLMs and supervised baselines across all evaluation protocols.
Act Like a Pathologist: Tissue-Aware Whole Slide Image Reasoning
Feb 28, 2026Computational pathology has advanced rapidly in recent years, driven by domain-specific image encoders and growing interest in using vision-language models to answer natural-language questions about diseases. Yet, the core problem behind pathology question-answering remains unsolved, considering that a gigapixel slide contains far more information than necessary for a given question. Pathologists naturally navigate tissue and morphology complexity by scanning broadly, and zooming in selectively according to the clinical questions. Current models, in contrast, rely on uniform patch sampling or broad attention maps, often attending equally to irrelevant regions while overlooking key visual evidence. In this work, we try to bring models closer to how humans actually examine slides. We propose a question-guided, tissue-aware, and coarse-to-fine retrieval framework, HistoSelect, that consists of two key components: a group sampler that identifies question-relevant tissue regions, followed by a patch selector that retrieves the most informative patches within those regions. By selecting only the most informative patches, our method becomes significantly more efficient: reducing visual token usage by 70% on average, while improving accuracy across three pathology QA tasks. Evaluated on 356,000 question-answer pairs, our approach outperforms existing methods and produces answers grounded in interpretable, pathologist-consistent regions. Our results suggest that bringing human-like search and attention patterns into WSI reasoning is a promising direction for building practical and reliable pathology VLMs.
Bézier Meets Diffusion: Robust Generation Across Domains for Medical Image Segmentation
Sep 26, 2025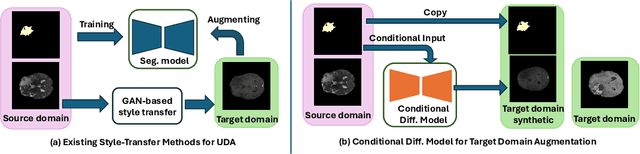
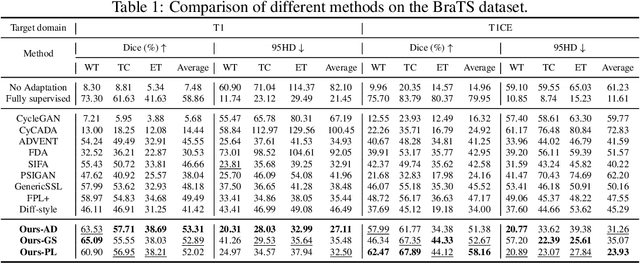
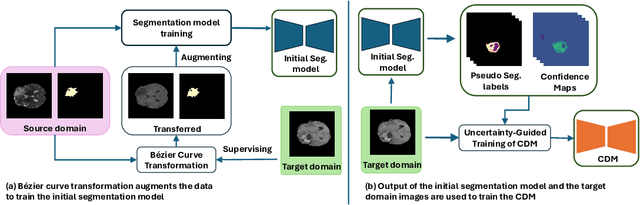
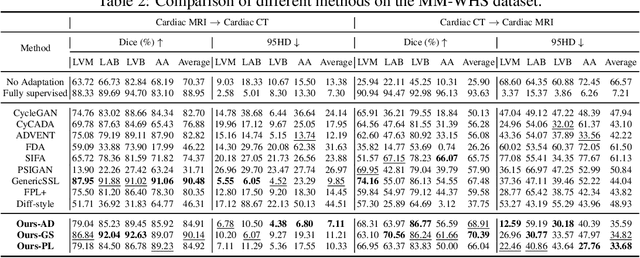
Training robust learning algorithms across different medical imaging modalities is challenging due to the large domain gap. Unsupervised domain adaptation (UDA) mitigates this problem by using annotated images from the source domain and unlabeled images from the target domain to train the deep models. Existing approaches often rely on GAN-based style transfer, but these methods struggle to capture cross-domain mappings in regions with high variability. In this paper, we propose a unified framework, B\'ezier Meets Diffusion, for cross-domain image generation. First, we introduce a B\'ezier-curve-based style transfer strategy that effectively reduces the domain gap between source and target domains. The transferred source images enable the training of a more robust segmentation model across domains. Thereafter, using pseudo-labels generated by this segmentation model on the target domain, we train a conditional diffusion model (CDM) to synthesize high-quality, labeled target-domain images. To mitigate the impact of noisy pseudo-labels, we further develop an uncertainty-guided score matching method that improves the robustness of CDM training. Extensive experiments on public datasets demonstrate that our approach generates realistic labeled images, significantly augmenting the target domain and improving segmentation performance.
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025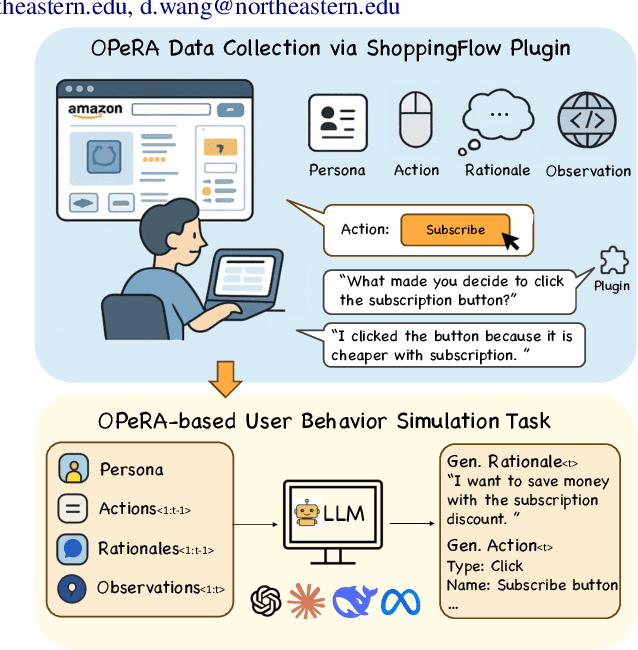
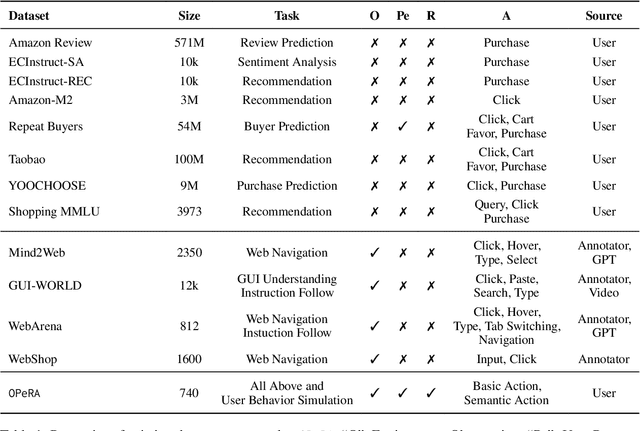
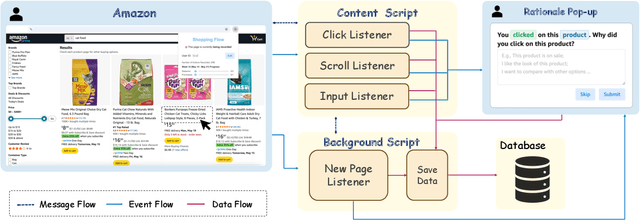
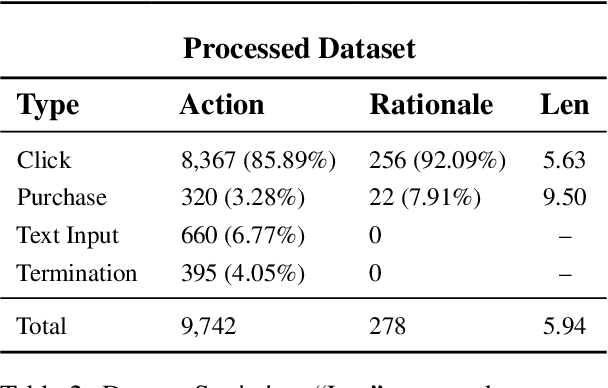
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.
Class Distillation with Mahalanobis Contrast: An Efficient Training Paradigm for Pragmatic Language Understanding Tasks
May 17, 2025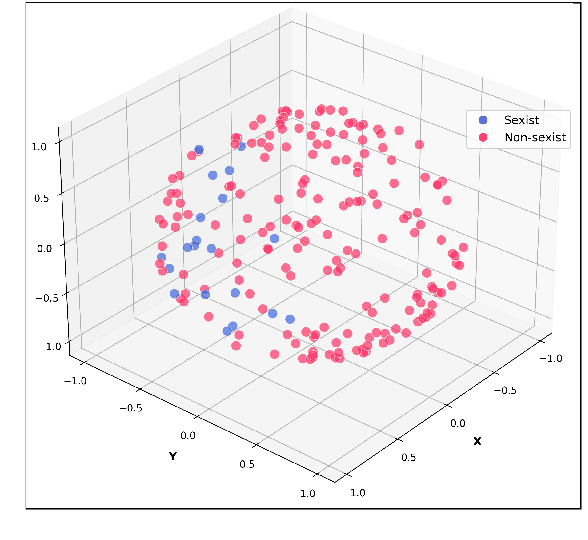

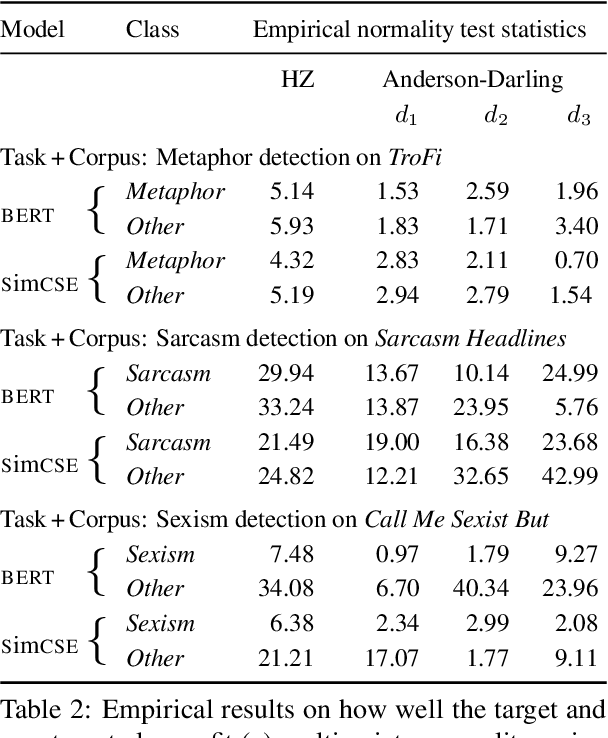
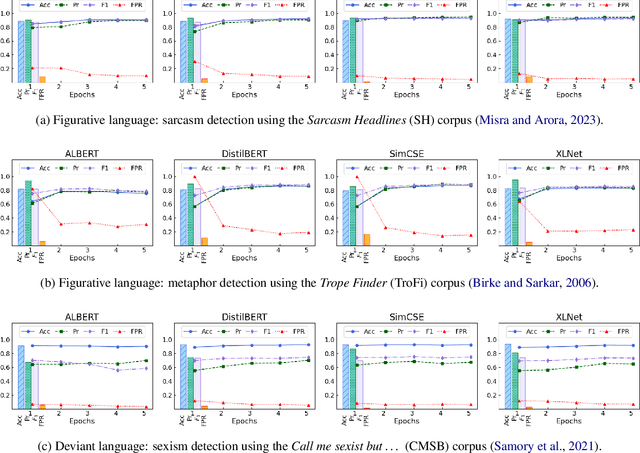
Detecting deviant language such as sexism, or nuanced language such as metaphors or sarcasm, is crucial for enhancing the safety, clarity, and interpretation of online social discourse. While existing classifiers deliver strong results on these tasks, they often come with significant computational cost and high data demands. In this work, we propose \textbf{Cla}ss \textbf{D}istillation (ClaD), a novel training paradigm that targets the core challenge: distilling a small, well-defined target class from a highly diverse and heterogeneous background. ClaD integrates two key innovations: (i) a loss function informed by the structural properties of class distributions, based on Mahalanobis distance, and (ii) an interpretable decision algorithm optimized for class separation. Across three benchmark detection tasks -- sexism, metaphor, and sarcasm -- ClaD outperforms competitive baselines, and even with smaller language models and orders of magnitude fewer parameters, achieves performance comparable to several large language models (LLMs). These results demonstrate ClaD as an efficient tool for pragmatic language understanding tasks that require gleaning a small target class from a larger heterogeneous background.
C^2 ATTACK: Towards Representation Backdoor on CLIP via Concept Confusion
Mar 12, 2025Backdoor attacks pose a significant threat to deep learning models, enabling adversaries to embed hidden triggers that manipulate the behavior of the model during inference. Traditional backdoor attacks typically rely on inserting explicit triggers (e.g., external patches, or perturbations) into input data, but they often struggle to evade existing defense mechanisms. To address this limitation, we investigate backdoor attacks through the lens of the reasoning process in deep learning systems, drawing insights from interpretable AI. We conceptualize backdoor activation as the manipulation of learned concepts within the model's latent representations. Thus, existing attacks can be seen as implicit manipulations of these activated concepts during inference. This raises interesting questions: why not manipulate the concepts explicitly? This idea leads to our novel backdoor attack framework, Concept Confusion Attack (C^2 ATTACK), which leverages internal concepts in the model's reasoning as "triggers" without introducing explicit external modifications. By avoiding the use of real triggers and directly activating or deactivating specific concepts in latent spaces, our approach enhances stealth, making detection by existing defenses significantly harder. Using CLIP as a case study, experimental results demonstrate the effectiveness of C^2 ATTACK, achieving high attack success rates while maintaining robustness against advanced defenses.
Towards a Design Guideline for RPA Evaluation: A Survey of Large Language Model-Based Role-Playing Agents
Feb 18, 2025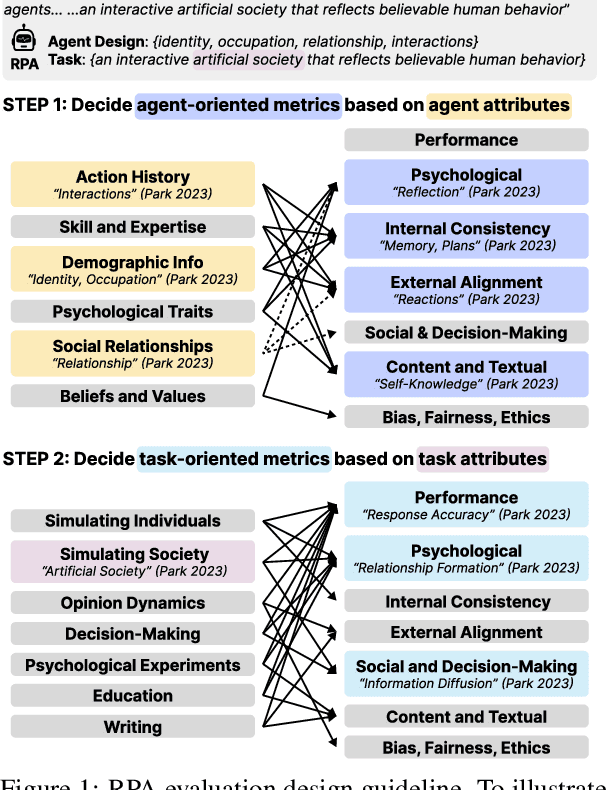
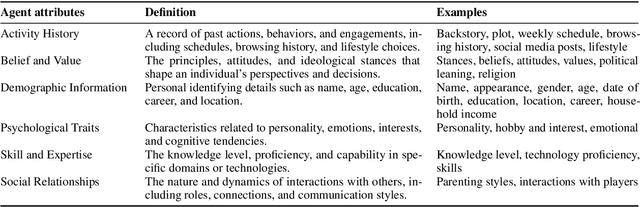
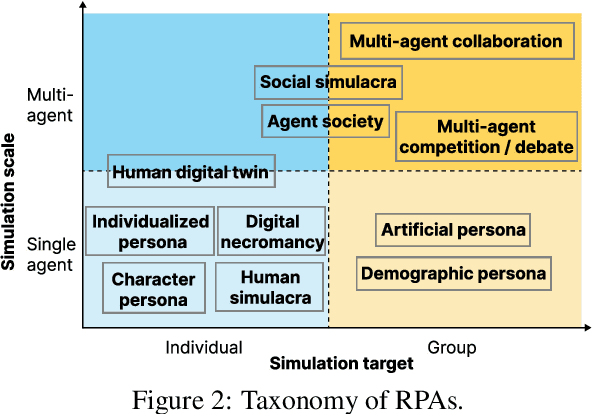

Role-Playing Agent (RPA) is an increasingly popular type of LLM Agent that simulates human-like behaviors in a variety of tasks. However, evaluating RPAs is challenging due to diverse task requirements and agent designs. This paper proposes an evidence-based, actionable, and generalizable evaluation design guideline for LLM-based RPA by systematically reviewing 1,676 papers published between Jan. 2021 and Dec. 2024. Our analysis identifies six agent attributes, seven task attributes, and seven evaluation metrics from existing literature. Based on these findings, we present an RPA evaluation design guideline to help researchers develop more systematic and consistent evaluation methods.
ImpScore: A Learnable Metric For Quantifying The Implicitness Level of Language
Nov 07, 2024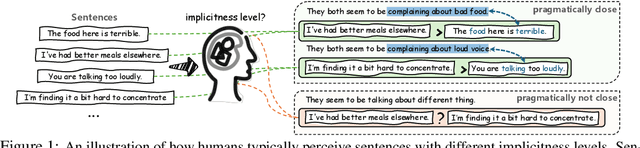
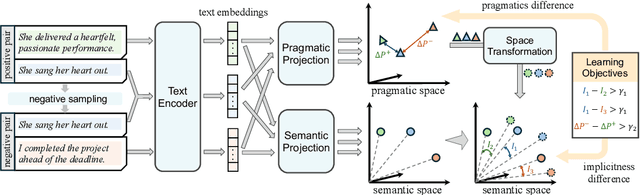

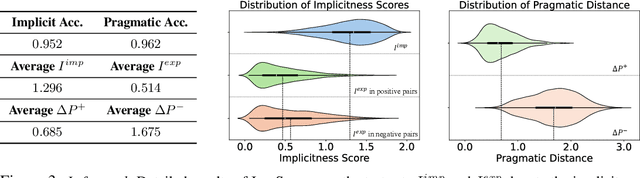
Handling implicit language is essential for natural language processing systems to achieve precise text understanding and facilitate natural interactions with users. Despite its importance, the absence of a robust metric for accurately measuring the implicitness of language significantly constrains the depth of analysis possible in evaluating models' comprehension capabilities. This paper addresses this gap by developing a scalar metric that quantifies the implicitness level of language without relying on external references. Drawing on principles from traditional linguistics, we define ''implicitness'' as the divergence between semantic meaning and pragmatic interpretation. To operationalize this definition, we introduce ImpScore, a novel, reference-free metric formulated through an interpretable regression model. This model is trained using pairwise contrastive learning on a specially curated dataset comprising $112,580$ (implicit sentence, explicit sentence) pairs. We validate ImpScore through a user study that compares its assessments with human evaluations on out-of-distribution data, demonstrating its accuracy and strong correlation with human judgments. Additionally, we apply ImpScore to hate speech detection datasets, illustrating its utility and highlighting significant limitations in current large language models' ability to understand highly implicit content. The metric model and its training data are available at https://github.com/audreycs/ImpScore.
Long-Tailed Backdoor Attack Using Dynamic Data Augmentation Operations
Oct 16, 2024



Recently, backdoor attack has become an increasing security threat to deep neural networks and drawn the attention of researchers. Backdoor attacks exploit vulnerabilities in third-party pretrained models during the training phase, enabling them to behave normally for clean samples and mispredict for samples with specific triggers. Existing backdoor attacks mainly focus on balanced datasets. However, real-world datasets often follow long-tailed distributions. In this paper, for the first time, we explore backdoor attack on such datasets. Specifically, we first analyze the influence of data imbalance on backdoor attack. Based on our analysis, we propose an effective backdoor attack named Dynamic Data Augmentation Operation (D$^2$AO). We design D$^2$AO selectors to select operations depending jointly on the class, sample type (clean vs. backdoored) and sample features. Meanwhile, we develop a trigger generator to generate sample-specific triggers. Through simultaneous optimization of the backdoored model and trigger generator, guided by dynamic data augmentation operation selectors, we achieve significant advancements. Extensive experiments demonstrate that our method can achieve the state-of-the-art attack performance while preserving the clean accuracy.