 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Latent Communication Patterns in Brain Networks via Adaptive Flow Routing
Jan 31, 2026Unraveling how macroscopic cognitive phenotypes emerge from microscopic neuronal connectivity remains one of the core pursuits of neuroscience. To this end, researchers typically leverage multi-modal information from structural connectivity (SC) and functional connectivity (FC) to complete downstream tasks. Recent methodologies explore the intricate coupling mechanisms between SC and FC, attempting to fuse their representations at the regional level. However, lacking fundamental neuroscientific insight, these approaches fail to uncover the latent interactions between neural regions underlying these connectomes, and thus cannot explain why SC and FC exhibit dynamic states of both coupling and heterogeneity. In this paper, we formulate multi-modal fusion through the lens of neural communication dynamics and propose the Adaptive Flow Routing Network (AFR-Net), a physics-informed framework that models how structural constraints (SC) give rise to functional communication patterns (FC), enabling interpretable discovery of critical neural pathways. Extensive experiments demonstrate that AFR-Net significantly outperforms state-of-the-art baselines. The code is available at https://anonymous.4open.science/r/DIAL-F0D1.
Visual Generation Unlocks Human-Like Reasoning through Multimodal World Models
Jan 27, 2026Humans construct internal world models and reason by manipulating the concepts within these models. Recent advances in AI, particularly chain-of-thought (CoT) reasoning, approximate such human cognitive abilities, where world models are believed to be embedded within large language models. Expert-level performance in formal and abstract domains such as mathematics and programming has been achieved in current systems by relying predominantly on verbal reasoning. However, they still lag far behind humans in domains like physical and spatial intelligence, which require richer representations and prior knowledge. The emergence of unified multimodal models (UMMs) capable of both verbal and visual generation has therefore sparked interest in more human-like reasoning grounded in complementary multimodal pathways, though their benefits remain unclear. From a world-model perspective, this paper presents the first principled study of when and how visual generation benefits reasoning. Our key position is the visual superiority hypothesis: for certain tasks--particularly those grounded in the physical world--visual generation more naturally serves as world models, whereas purely verbal world models encounter bottlenecks arising from representational limitations or insufficient prior knowledge. Theoretically, we formalize internal world modeling as a core component of CoT reasoning and analyze distinctions among different forms of world models. Empirically, we identify tasks that necessitate interleaved visual-verbal CoT reasoning, constructing a new evaluation suite, VisWorld-Eval. Controlled experiments on a state-of-the-art UMM show that interleaved CoT significantly outperforms purely verbal CoT on tasks that favor visual world modeling, but offers no clear advantage otherwise. Together, this work clarifies the potential of multimodal world modeling for more powerful, human-like multimodal AI.
AdversaRiskQA: An Adversarial Factuality Benchmark for High-Risk Domains
Jan 21, 2026Hallucination in large language models (LLMs) remains an acute concern, contributing to the spread of misinformation and diminished public trust, particularly in high-risk domains. Among hallucination types, factuality is crucial, as it concerns a model's alignment with established world knowledge. Adversarial factuality, defined as the deliberate insertion of misinformation into prompts with varying levels of expressed confidence, tests a model's ability to detect and resist confidently framed falsehoods. Existing work lacks high-quality, domain-specific resources for assessing model robustness under such adversarial conditions, and no prior research has examined the impact of injected misinformation on long-form text factuality. To address this gap, we introduce AdversaRiskQA, the first verified and reliable benchmark systematically evaluating adversarial factuality across Health, Finance, and Law. The benchmark includes two difficulty levels to test LLMs' defensive capabilities across varying knowledge depths. We propose two automated methods for evaluating the adversarial attack success and long-form factuality. We evaluate six open- and closed-source LLMs from the Qwen, GPT-OSS, and GPT families, measuring misinformation detection rates. Long-form factuality is assessed on Qwen3 (30B) under both baseline and adversarial conditions. Results show that after excluding meaningless responses, Qwen3 (80B) achieves the highest average accuracy, while GPT-5 maintains consistently high accuracy. Performance scales non-linearly with model size, varies by domains, and gaps between difficulty levels narrow as models grow. Long-form evaluation reveals no significant correlation between injected misinformation and the model's factual output. AdversaRiskQA provides a valuable benchmark for pinpointing LLM weaknesses and developing more reliable models for high-stakes applications.
Efficient Text-Attributed Graph Learning through Selective Annotation and Graph Alignment
Jun 08, 2025In the realm of Text-attributed Graphs (TAGs), traditional graph neural networks (GNNs) often fall short due to the complex textual information associated with each node. Recent methods have improved node representations by leveraging large language models (LLMs) to enhance node text features, but these approaches typically require extensive annotations or fine-tuning across all nodes, which is both time-consuming and costly. To overcome these challenges, we introduce GAGA, an efficient framework for TAG representation learning. GAGA reduces annotation time and cost by focusing on annotating only representative nodes and edges. It constructs an annotation graph that captures the topological relationships among these annotations. Furthermore, GAGA employs a two-level alignment module to effectively integrate the annotation graph with the TAG, aligning their underlying structures. Experiments show that GAGA achieves classification accuracies on par with or surpassing state-of-the-art methods while requiring only 1% of the data to be annotated, demonstrating its high efficiency.
C^2 ATTACK: Towards Representation Backdoor on CLIP via Concept Confusion
Mar 12, 2025Backdoor attacks pose a significant threat to deep learning models, enabling adversaries to embed hidden triggers that manipulate the behavior of the model during inference. Traditional backdoor attacks typically rely on inserting explicit triggers (e.g., external patches, or perturbations) into input data, but they often struggle to evade existing defense mechanisms. To address this limitation, we investigate backdoor attacks through the lens of the reasoning process in deep learning systems, drawing insights from interpretable AI. We conceptualize backdoor activation as the manipulation of learned concepts within the model's latent representations. Thus, existing attacks can be seen as implicit manipulations of these activated concepts during inference. This raises interesting questions: why not manipulate the concepts explicitly? This idea leads to our novel backdoor attack framework, Concept Confusion Attack (C^2 ATTACK), which leverages internal concepts in the model's reasoning as "triggers" without introducing explicit external modifications. By avoiding the use of real triggers and directly activating or deactivating specific concepts in latent spaces, our approach enhances stealth, making detection by existing defenses significantly harder. Using CLIP as a case study, experimental results demonstrate the effectiveness of C^2 ATTACK, achieving high attack success rates while maintaining robustness against advanced defenses.
Leveraging ASIC AI Chips for Homomorphic Encryption
Jan 13, 2025
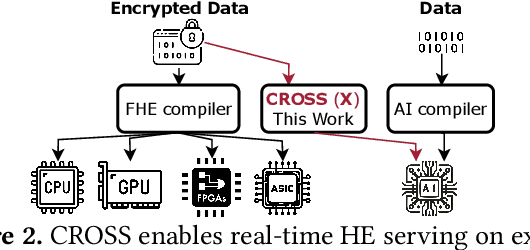
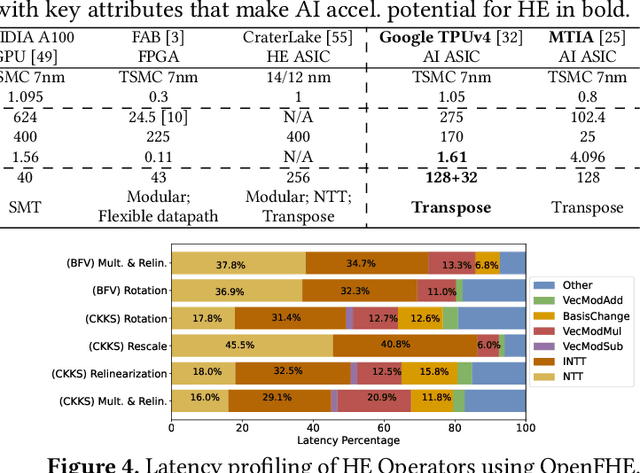
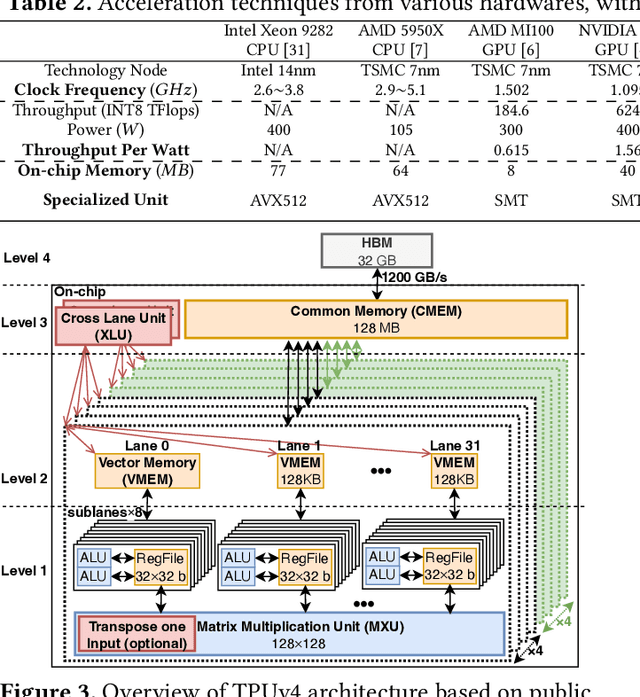
Cloud-based services are making the outsourcing of sensitive client data increasingly common. Although homomorphic encryption (HE) offers strong privacy guarantee, it requires substantially more resources than computing on plaintext, often leading to unacceptably large latencies in getting the results. HE accelerators have emerged to mitigate this latency issue, but with the high cost of ASICs. In this paper we show that HE primitives can be converted to AI operators and accelerated on existing ASIC AI accelerators, like TPUs, which are already widely deployed in the cloud. Adapting such accelerators for HE requires (1) supporting modular multiplication, (2) high-precision arithmetic in software, and (3) efficient mapping on matrix engines. We introduce the CROSS compiler (1) to adopt Barrett reduction to provide modular reduction support using multiplier and adder, (2) Basis Aligned Transformation (BAT) to convert high-precision multiplication as low-precision matrix-vector multiplication, (3) Matrix Aligned Transformation (MAT) to covert vectorized modular operation with reduction into matrix multiplication that can be efficiently processed on 2D spatial matrix engine. Our evaluation of CROSS on a Google TPUv4 demonstrates significant performance improvements, with up to 161x and 5x speedup compared to the previous work on many-core CPUs and V100. The kernel-level codes are open-sourced at https://github.com/google/jaxite.git.
Private Language Models via Truncated Laplacian Mechanism
Oct 10, 2024
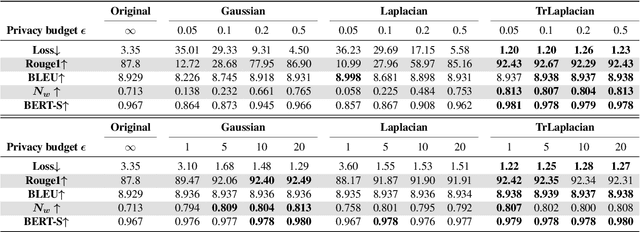
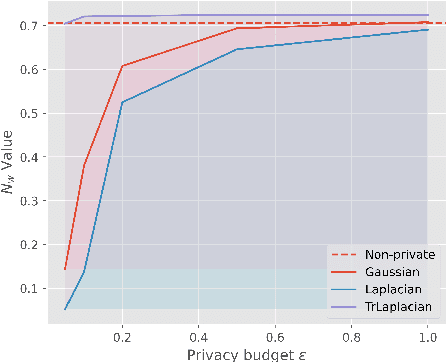
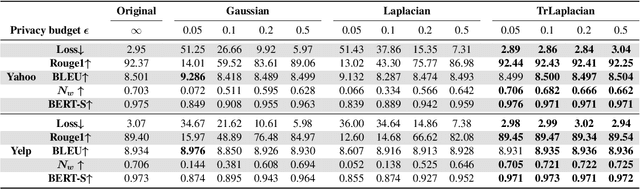
Deep learning models for NLP tasks are prone to variants of privacy attacks. To prevent privacy leakage, researchers have investigated word-level perturbations, relying on the formal guarantees of differential privacy (DP) in the embedding space. However, many existing approaches either achieve unsatisfactory performance in the high privacy regime when using the Laplacian or Gaussian mechanism, or resort to weaker relaxations of DP that are inferior to the canonical DP in terms of privacy strength. This raises the question of whether a new method for private word embedding can be designed to overcome these limitations. In this paper, we propose a novel private embedding method called the high dimensional truncated Laplacian mechanism. Specifically, we introduce a non-trivial extension of the truncated Laplacian mechanism, which was previously only investigated in one-dimensional space cases. Theoretically, we show that our method has a lower variance compared to the previous private word embedding methods. To further validate its effectiveness, we conduct comprehensive experiments on private embedding and downstream tasks using three datasets. Remarkably, even in the high privacy regime, our approach only incurs a slight decrease in utility compared to the non-private scenario.
Faithful Interpretation for Graph Neural Networks
Oct 09, 2024Currently, attention mechanisms have garnered increasing attention in Graph Neural Networks (GNNs), such as Graph Attention Networks (GATs) and Graph Transformers (GTs). It is not only due to the commendable boost in performance they offer but also its capacity to provide a more lucid rationale for model behaviors, which are often viewed as inscrutable. However, Attention-based GNNs have demonstrated instability in interpretability when subjected to various sources of perturbations during both training and testing phases, including factors like additional edges or nodes. In this paper, we propose a solution to this problem by introducing a novel notion called Faithful Graph Attention-based Interpretation (FGAI). In particular, FGAI has four crucial properties regarding stability and sensitivity to interpretation and final output distribution. Built upon this notion, we propose an efficient methodology for obtaining FGAI, which can be viewed as an ad hoc modification to the canonical Attention-based GNNs. To validate our proposed solution, we introduce two novel metrics tailored for graph interpretation assessment. Experimental results demonstrate that FGAI exhibits superior stability and preserves the interpretability of attention under various forms of perturbations and randomness, which makes FGAI a more faithful and reliable explanation tool.
Semi-supervised Concept Bottleneck Models
Jun 27, 2024Concept Bottleneck Models (CBMs) have garnered increasing attention due to their ability to provide concept-based explanations for black-box deep learning models while achieving high final prediction accuracy using human-like concepts. However, the training of current CBMs heavily relies on the accuracy and richness of annotated concepts in the dataset. These concept labels are typically provided by experts, which can be costly and require significant resources and effort. Additionally, concept saliency maps frequently misalign with input saliency maps, causing concept predictions to correspond to irrelevant input features - an issue related to annotation alignment. To address these limitations, we propose a new framework called SSCBM (Semi-supervised Concept Bottleneck Model). Our SSCBM is suitable for practical situations where annotated data is scarce. By leveraging joint training on both labeled and unlabeled data and aligning the unlabeled data at the concept level, we effectively solve these issues. We proposed a strategy to generate pseudo labels and an alignment loss. Experiments demonstrate that our SSCBM is both effective and efficient. With only 20% labeled data, we achieved 93.19% (96.39% in a fully supervised setting) concept accuracy and 75.51% (79.82% in a fully supervised setting) prediction accuracy.
PROMPT-SAW: Leveraging Relation-Aware Graphs for Textual Prompt Compression
Mar 30, 2024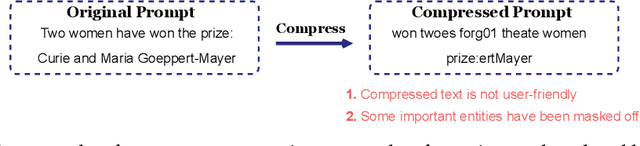
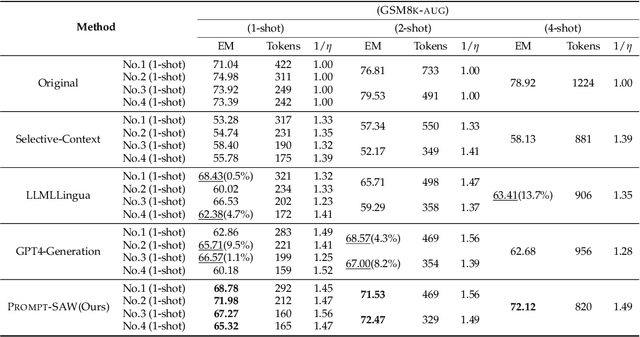
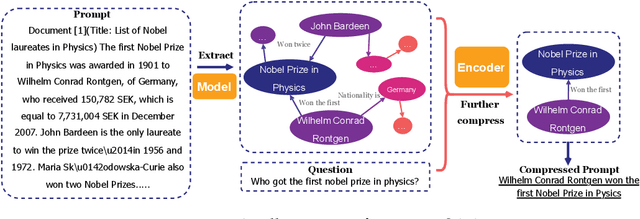
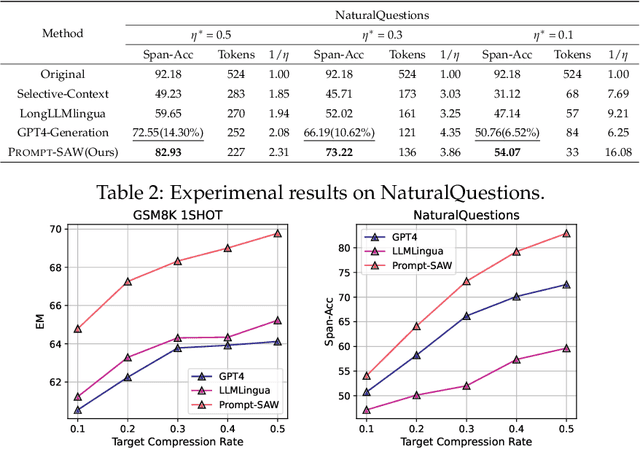
Large language models (LLMs) have shown exceptional abilities for multiple different natural language processing tasks. While prompting is a crucial tool for LLM inference, we observe that there is a significant cost associated with exceedingly lengthy prompts. Existing attempts to compress lengthy prompts lead to sub-standard results in terms of readability and interpretability of the compressed prompt, with a detrimental impact on prompt utility. To address this, we propose PROMPT-SAW: Prompt compresSion via Relation AWare graphs, an effective strategy for prompt compression over task-agnostic and task-aware prompts. PROMPT-SAW uses the prompt's textual information to build a graph, later extracts key information elements in the graph to come up with the compressed prompt. We also propose GSM8K-AUG, i.e., an extended version of the existing GSM8k benchmark for task-agnostic prompts in order to provide a comprehensive evaluation platform. Experimental evaluation using benchmark datasets shows that prompts compressed by PROMPT-SAW are not only better in terms of readability, but they also outperform the best-performing baseline models by up to 14.3 and 13.7 respectively for task-aware and task-agnostic settings while compressing the original prompt text by 33.0 and 56.7.