 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Language Models via Truncated Laplacian Mechanism
Paper and Code

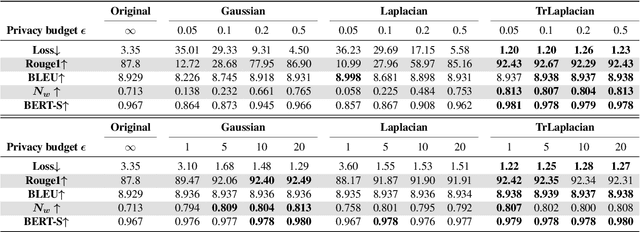
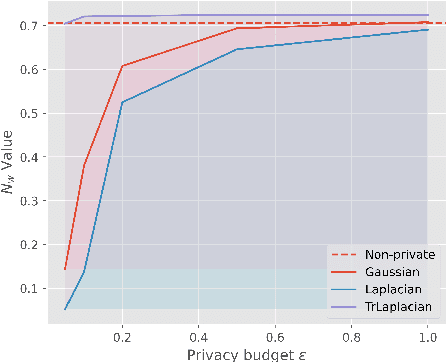
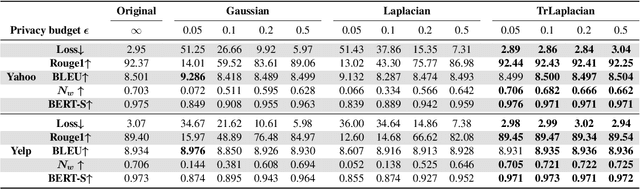
Deep learning models for NLP tasks are prone to variants of privacy attacks. To prevent privacy leakage, researchers have investigated word-level perturbations, relying on the formal guarantees of differential privacy (DP) in the embedding space. However, many existing approaches either achieve unsatisfactory performance in the high privacy regime when using the Laplacian or Gaussian mechanism, or resort to weaker relaxations of DP that are inferior to the canonical DP in terms of privacy strength. This raises the question of whether a new method for private word embedding can be designed to overcome these limitations. In this paper, we propose a novel private embedding method called the high dimensional truncated Laplacian mechanism. Specifically, we introduce a non-trivial extension of the truncated Laplacian mechanism, which was previously only investigated in one-dimensional space cases. Theoretically, we show that our method has a lower variance compared to the previous private word embedding methods. To further validate its effectiveness, we conduct comprehensive experiments on private embedding and downstream tasks using three datasets. Remarkably, even in the high privacy regime, our approach only incurs a slight decrease in utility compared to the non-private scenario.