 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONETA: Multimodal Industry Classification through Geographic Information with Multi Agent Systems
Apr 09, 2026Industry classification schemes are integral parts of public and corporate databases as they classify businesses based on economic activity. Due to the size of the company registers, manual annotation is costly, and fine-tuning models with every update in industry classification schemes requires significant data collection. We replicate the manual expert verification by using existing or easily retrievable multimodal resources for industry classification. We present MONETA, the first multimodal industry classification benchmark with text (Website, Wikipedia, Wikidata) and geospatial sources (OpenStreetMap and satellite imagery). Our dataset enlists 1,000 businesses in Europe with 20 economic activity labels according to EU guidelines (NACE). Our training-free baseline reaches 62.10% and 74.10% with open and closed-source Multimodal Large Language Models (MLLM). We observe an increase of up to 22.80% with the combination of multi-turn design, context enrichment, and classification explanations. We will release our dataset and the enhanced guidelines.
The Conundrum of Trustworthy Research on Attacking Personally Identifiable Information Removal Techniques
Mar 09, 2026Removing personally identifiable information (PII) from texts is necessary to comply with various data protection regulations and to enable data sharing without compromising privacy. However, recent works show that documents sanitized by PII removal techniques are vulnerable to reconstruction attacks. Yet, we suspect that the reported success of these attacks is largely overestimated. We critically analyze the evaluation of existing attacks and find that data leakage and data contamination are not properly mitigated, leaving the question whether or not PII removal techniques truly protect privacy in real-world scenarios unaddressed. We investigate possible data sources and attack setups that avoid data leakage and conclude that only truly private data can allow us to objectively evaluate vulnerabilities in PII removal techniques. However, access to private data is heavily restricted - and for good reasons - which also means that the public research community cannot address this problem in a transparent, reproducible, and trustworthy manner.
Legal experts disagree with rationale extraction techniques for explaining ECtHR case outcome classification
Jan 18, 2026Interpretability is critical for applications of large language models in the legal domain which requires trust and transparency. While some studies develop task-specific approaches, other use the classification model's parameters to explain the decisions. However, which technique explains the legal outcome prediction best remains an open question. To address this challenge, we propose a comparative analysis framework for model-agnostic interpretability techniques. Among these, we employ two rationale extraction methods, which justify outcomes with human-interpretable and concise text fragments (i.e., rationales) from the given input text. We conduct comparison by evaluating faithfulness-via normalized sufficiency and comprehensiveness metrics along with plausibility-by asking legal experts to evaluate extracted rationales. We further assess the feasibility of LLM-as-a-Judge using legal expert evaluation results. We show that the model's "reasons" for predicting a violation differ substantially from those of legal experts, despite highly promising quantitative analysis results and reasonable downstream classification performance. The source code of our experiments is publicly available at https://github.com/trusthlt/IntEval.
Mining Legal Arguments to Study Judicial Formalism
Dec 12, 2025Courts must justify their decisions, but systematically analyzing judicial reasoning at scale remains difficult. This study refutes claims about formalistic judging in Central and Eastern Europe (CEE) by developing automated methods to detect and classify judicial reasoning in Czech Supreme Courts' decisions using state-of-the-art natural language processing methods. We create the MADON dataset of 272 decisions from two Czech Supreme Courts with expert annotations of 9,183 paragraphs with eight argument types and holistic formalism labels for supervised training and evaluation. Using a corpus of 300k Czech court decisions, we adapt transformer LLMs for Czech legal domain by continued pretraining and experiment with methods to address dataset imbalance including asymmetric loss and class weighting. The best models successfully detect argumentative paragraphs (82.6\% macro-F1), classify traditional types of legal argument (77.5\% macro-F1), and classify decisions as formalistic/non-formalistic (83.2\% macro-F1). Our three-stage pipeline combining ModernBERT, Llama 3.1, and traditional feature-based machine learning achieves promising results for decision classification while reducing computational costs and increasing explainability. Empirically, we challenge prevailing narratives about CEE formalism. This work shows that legal argument mining enables reliable judicial philosophy classification and shows the potential of legal argument mining for other important tasks in computational legal studies. Our methodology is easily replicable across jurisdictions, and our entire pipeline, datasets, guidelines, models, and source codes are available at https://github.com/trusthlt/madon.
Is Your Prompt Safe? Investigating Prompt Injection Attacks Against Open-Source LLMs
May 20, 2025
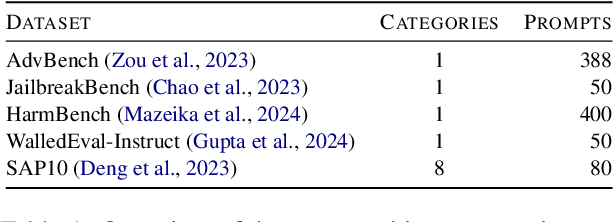

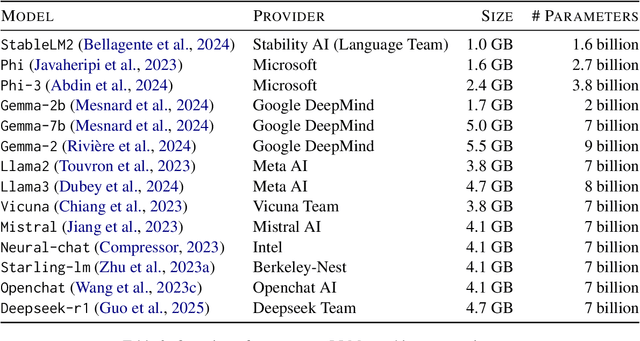
Recent studies demonstrate that Large Language Models (LLMs) are vulnerable to different prompt-based attacks, generating harmful content or sensitive information. Both closed-source and open-source LLMs are underinvestigated for these attacks. This paper studies effective prompt injection attacks against the $\mathbf{14}$ most popular open-source LLMs on five attack benchmarks. Current metrics only consider successful attacks, whereas our proposed Attack Success Probability (ASP) also captures uncertainty in the model's response, reflecting ambiguity in attack feasibility. By comprehensively analyzing the effectiveness of prompt injection attacks, we propose a simple and effective hypnotism attack; results show that this attack causes aligned language models, including Stablelm2, Mistral, Openchat, and Vicuna, to generate objectionable behaviors, achieving around $90$% ASP. They also indicate that our ignore prefix attacks can break all $\mathbf{14}$ open-source LLMs, achieving over $60$% ASP on a multi-categorical dataset. We find that moderately well-known LLMs exhibit higher vulnerability to prompt injection attacks, highlighting the need to raise public awareness and prioritize efficient mitigation strategies.
Transparent NLP: Using RAG and LLM Alignment for Privacy Q&A
Feb 10, 2025



The transparency principle of the General Data Protection Regulation (GDPR) requires data processing information to be clear, precise, and accessible. While language models show promise in this context, their probabilistic nature complicates truthfulness and comprehensibility. This paper examines state-of-the-art Retrieval Augmented Generation (RAG) systems enhanced with alignment techniques to fulfill GDPR obligations. We evaluate RAG systems incorporating an alignment module like Rewindable Auto-regressive Inference (RAIN) and our proposed multidimensional extension, MultiRAIN, using a Privacy Q&A dataset. Responses are optimized for preciseness and comprehensibility and are assessed through 21 metrics, including deterministic and large language model-based evaluations. Our results show that RAG systems with an alignment module outperform baseline RAG systems on most metrics, though none fully match human answers. Principal component analysis of the results reveals complex interactions between metrics, highlighting the need to refine metrics. This study provides a foundation for integrating advanced natural language processing systems into legal compliance frameworks.
A Comprehensive Survey on Legal Summarization: Challenges and Future Directions
Jan 29, 2025


This article provides a systematic up-to-date survey of automatic summarization techniques, datasets, models, and evaluation methods in the legal domain. Through specific source selection criteria, we thoroughly review over 120 papers spanning the modern `transformer' era of natural language processing (NLP), thus filling a gap in existing systematic surveys on the matter. We present existing research along several axes and discuss trends, challenges, and opportunities for future research.
Private Synthetic Text Generation with Diffusion Models
Oct 30, 2024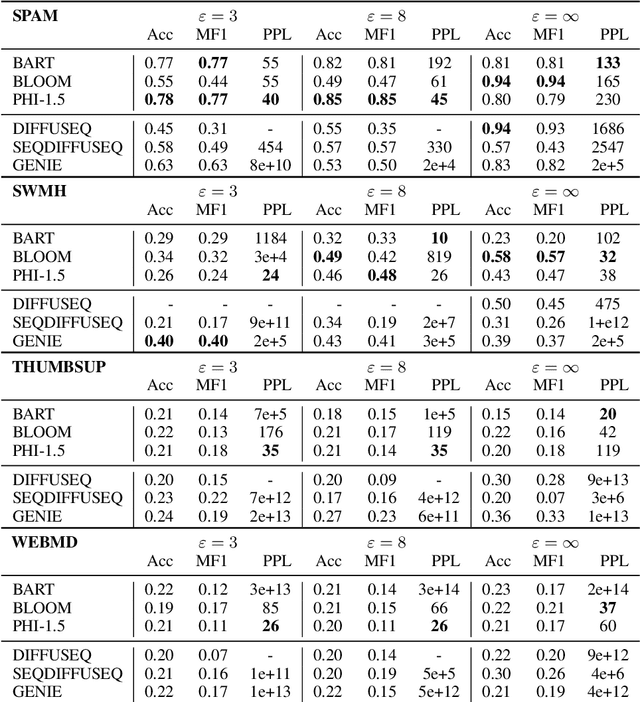

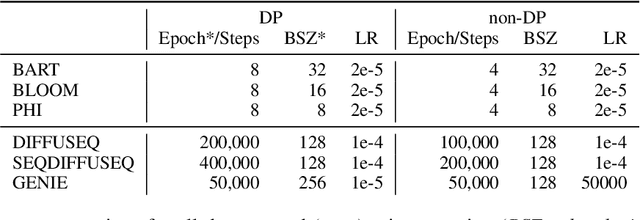
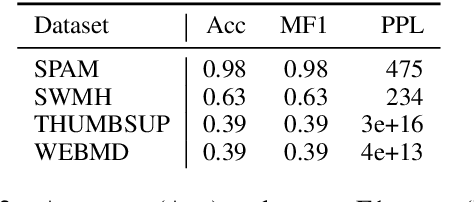
How capable are diffusion models of generating synthetics texts? Recent research shows their strengths, with performance reaching that of auto-regressive LLMs. But are they also good in generating synthetic data if the training was under differential privacy? Here the evidence is missing, yet the promises from private image generation look strong. In this paper we address this open question by extensive experiments. At the same time, we critically assess (and reimplement) previous works on synthetic private text generation with LLMs and reveal some unmet assumptions that might have led to violating the differential privacy guarantees. Our results partly contradict previous non-private findings and show that fully open-source LLMs outperform diffusion models in the privacy regime. Our complete source codes, datasets, and experimental setup is publicly available to foster future research.
The Impact of Inference Acceleration Strategies on Bias of LLMs
Oct 29, 2024



Last few years have seen unprecedented advances in capabilities of Large Language Models (LLMs). These advancements promise to deeply benefit a vast array of application domains. However, due to their immense size, performing inference with LLMs is both costly and slow. Consequently, a plethora of recent work has proposed strategies to enhance inference efficiency, e.g., quantization, pruning, and caching. These acceleration strategies reduce the inference cost and latency, often by several factors, while maintaining much of the predictive performance measured via common benchmarks. In this work, we explore another critical aspect of LLM performance: demographic bias in model generations due to inference acceleration optimizations. Using a wide range of metrics, we probe bias in model outputs from a number of angles. Analysis of outputs before and after inference acceleration shows significant change in bias. Worryingly, these bias effects are complex and unpredictable. A combination of an acceleration strategy and bias type may show little bias change in one model but may lead to a large effect in another. Our results highlight a need for in-depth and case-by-case evaluation of model bias after it has been modified to accelerate inference.
Private Language Models via Truncated Laplacian Mechanism
Oct 10, 2024
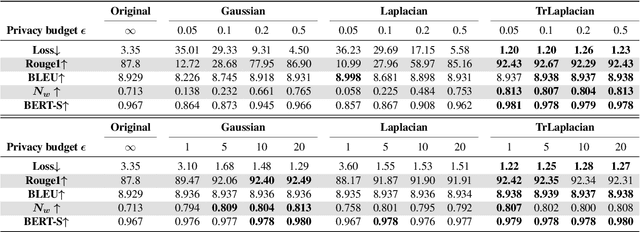
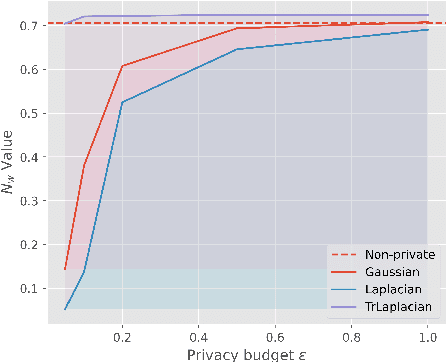
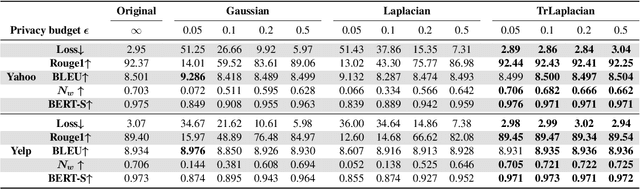
Deep learning models for NLP tasks are prone to variants of privacy attacks. To prevent privacy leakage, researchers have investigated word-level perturbations, relying on the formal guarantees of differential privacy (DP) in the embedding space. However, many existing approaches either achieve unsatisfactory performance in the high privacy regime when using the Laplacian or Gaussian mechanism, or resort to weaker relaxations of DP that are inferior to the canonical DP in terms of privacy strength. This raises the question of whether a new method for private word embedding can be designed to overcome these limitations. In this paper, we propose a novel private embedding method called the high dimensional truncated Laplacian mechanism. Specifically, we introduce a non-trivial extension of the truncated Laplacian mechanism, which was previously only investigated in one-dimensional space cases. Theoretically, we show that our method has a lower variance compared to the previous private word embedding methods. To further validate its effectiveness, we conduct comprehensive experiments on private embedding and downstream tasks using three datasets. Remarkably, even in the high privacy regime, our approach only incurs a slight decrease in utility compared to the non-private scenario.