 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranularity is crucial when applying differential privacy to text: An investigation for neural machine translation
Jul 26, 2024Applying differential privacy (DP) by means of the DP-SGD algorithm to protect individual data points during training is becoming increasingly popular in NLP. However, the choice of granularity at which DP is applied is often neglected. For example, neural machine translation (NMT) typically operates on the sentence-level granularity. From the perspective of DP, this setup assumes that each sentence belongs to a single person and any two sentences in the training dataset are independent. This assumption is however violated in many real-world NMT datasets, e.g. those including dialogues. For proper application of DP we thus must shift from sentences to entire documents. In this paper, we investigate NMT at both the sentence and document levels, analyzing the privacy/utility trade-off for both scenarios, and evaluating the risks of not using the appropriate privacy granularity in terms of leaking personally identifiable information (PII). Our findings indicate that the document-level NMT system is more resistant to membership inference attacks, emphasizing the significance of using the appropriate granularity when working with DP.
DP-NMT: Scalable Differentially-Private Machine Translation
Nov 24, 2023Neural machine translation (NMT) is a widely popular text generation task, yet there is a considerable research gap in the development of privacy-preserving NMT models, despite significant data privacy concerns for NMT systems. Differentially private stochastic gradient descent (DP-SGD) is a popular method for training machine learning models with concrete privacy guarantees; however, the implementation specifics of training a model with DP-SGD are not always clarified in existing models, with differing software libraries used and code bases not always being public, leading to reproducibility issues. To tackle this, we introduce DP-NMT, an open-source framework for carrying out research on privacy-preserving NMT with DP-SGD, bringing together numerous models, datasets, and evaluation metrics in one systematic software package. Our goal is to provide a platform for researchers to advance the development of privacy-preserving NMT systems, keeping the specific details of the DP-SGD algorithm transparent and intuitive to implement. We run a set of experiments on datasets from both general and privacy-related domains to demonstrate our framework in use. We make our framework publicly available and welcome feedback from the community.
DP-BART for Privatized Text Rewriting under Local Differential Privacy
Feb 15, 2023Privatized text rewriting with local differential privacy (LDP) is a recent approach that enables sharing of sensitive textual documents while formally guaranteeing privacy protection to individuals. However, existing systems face several issues, such as formal mathematical flaws, unrealistic privacy guarantees, privatization of only individual words, as well as a lack of transparency and reproducibility. In this paper, we propose a new system 'DP-BART' that largely outperforms existing LDP systems. Our approach uses a novel clipping method, iterative pruning, and further training of internal representations which drastically reduces the amount of noise required for DP guarantees. We run experiments on five textual datasets of varying sizes, rewriting them at different privacy guarantees and evaluating the rewritten texts on downstream text classification tasks. Finally, we thoroughly discuss the privatized text rewriting approach and its limitations, including the problem of the strict text adjacency constraint in the LDP paradigm that leads to the high noise requirement.
DP-Rewrite: Towards Reproducibility and Transparency in Differentially Private Text Rewriting
Aug 22, 2022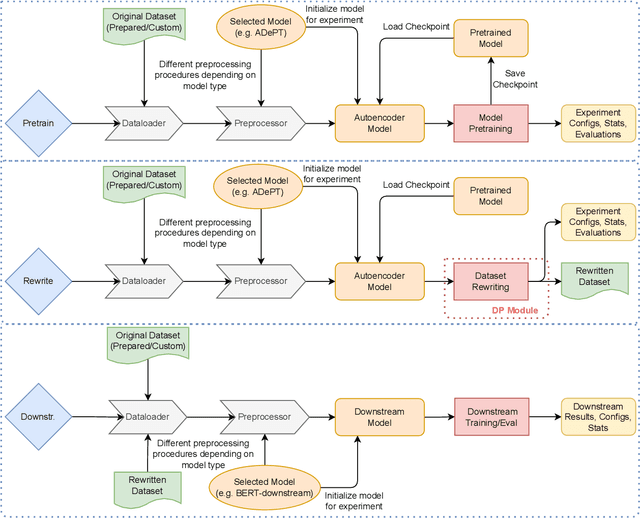
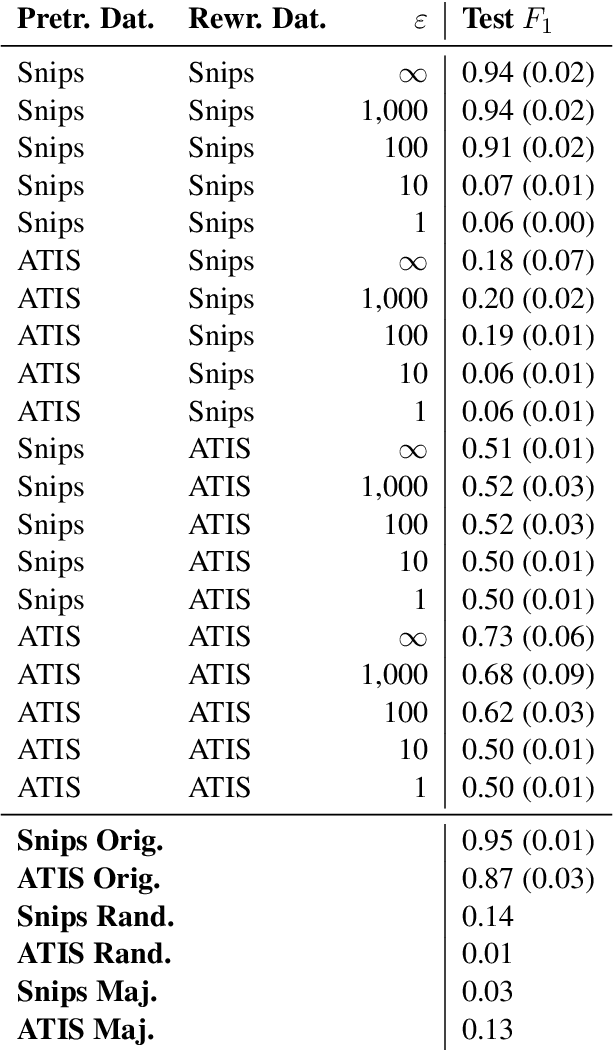
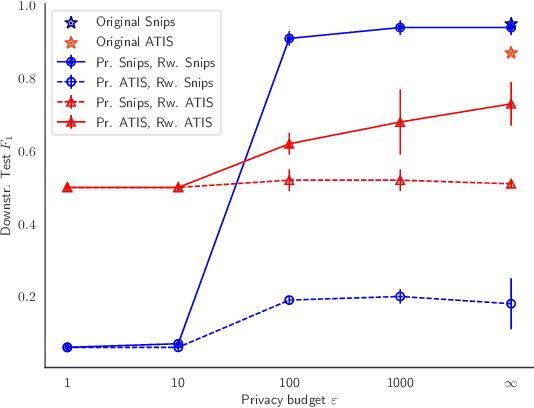

Text rewriting with differential privacy (DP) provides concrete theoretical guarantees for protecting the privacy of individuals in textual documents. In practice, existing systems may lack the means to validate their privacy-preserving claims, leading to problems of transparency and reproducibility. We introduce DP-Rewrite, an open-source framework for differentially private text rewriting which aims to solve these problems by being modular, extensible, and highly customizable. Our system incorporates a variety of downstream datasets, models, pre-training procedures, and evaluation metrics to provide a flexible way to lead and validate private text rewriting research. To demonstrate our software in practice, we provide a set of experiments as a case study on the ADePT DP text rewriting system, detecting a privacy leak in its pre-training approach. Our system is publicly available, and we hope that it will help the community to make DP text rewriting research more accessible and transparent.
One size does not fit all: Investigating strategies for differentially-private learning across NLP tasks
Dec 15, 2021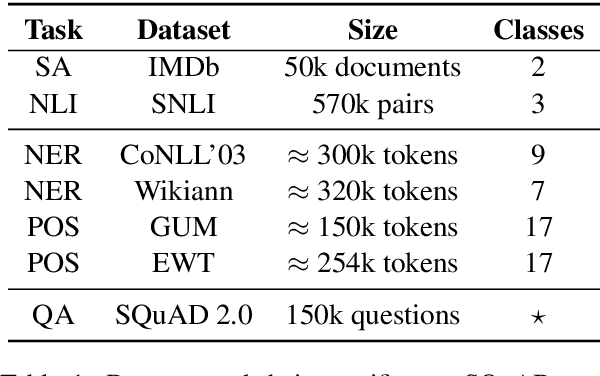
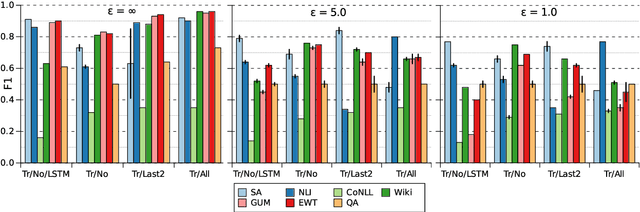
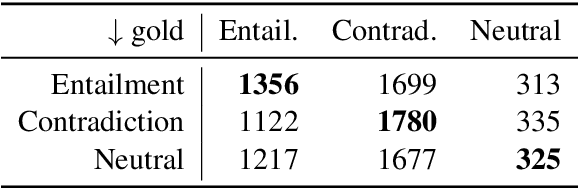
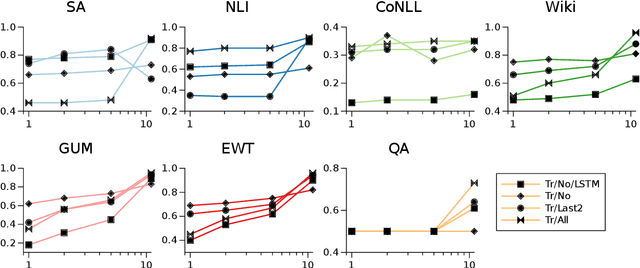
Preserving privacy in training modern NLP models comes at a cost. We know that stricter privacy guarantees in differentially-private stochastic gradient descent (DP-SGD) generally degrade model performance. However, previous research on the efficiency of DP-SGD in NLP is inconclusive or even counter-intuitive. In this short paper, we provide a thorough analysis of different privacy preserving strategies on seven downstream datasets in five different `typical' NLP tasks with varying complexity using modern neural models. We show that unlike standard non-private approaches to solving NLP tasks, where bigger is usually better, privacy-preserving strategies do not exhibit a winning pattern, and each task and privacy regime requires a special treatment to achieve adequate performance.
Privacy-Preserving Graph Convolutional Networks for Text Classification
Feb 10, 2021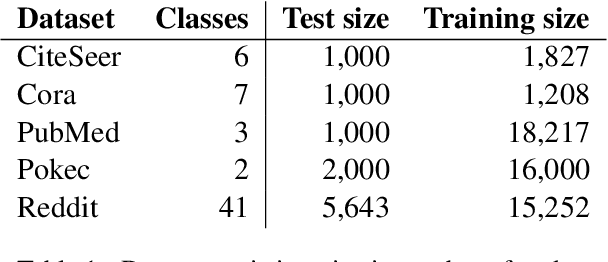
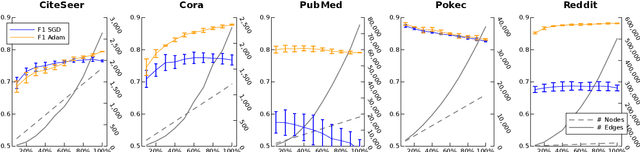
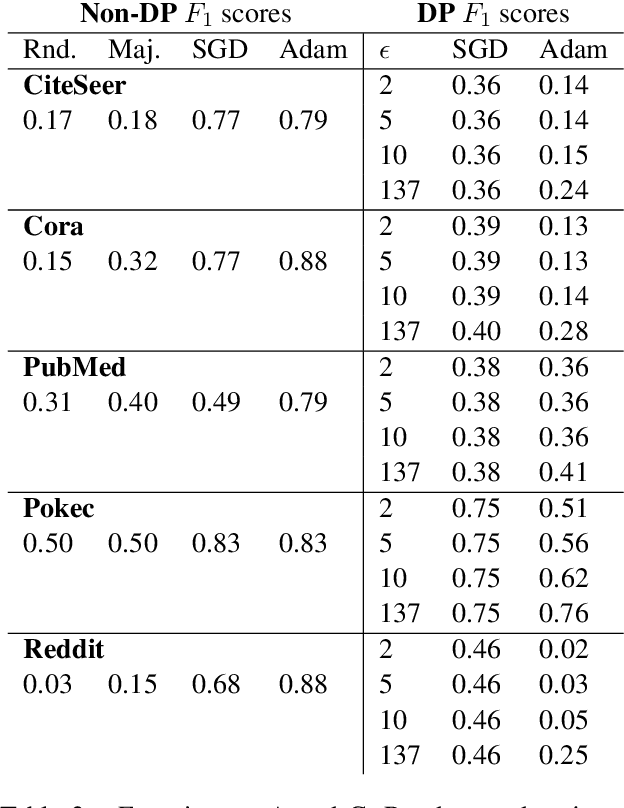
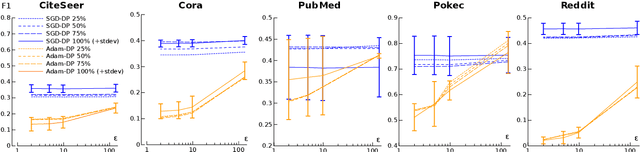
Graph convolutional networks (GCNs) are a powerful architecture for representation learning and making predictions on documents that naturally occur as graphs, e.g., citation or social networks. Data containing sensitive personal information, such as documents with people's profiles or relationships as edges, are prone to privacy leaks from GCNs, as an adversary might reveal the original input from the trained model. Although differential privacy (DP) offers a well-founded privacy-preserving framework, GCNs pose theoretical and practical challenges due to their training specifics. We address these challenges by adapting differentially-private gradient-based training to GCNs. We investigate the impact of various privacy budgets, dataset sizes, and two optimizers in an experimental setup over five NLP datasets in two languages. We show that, under certain modeling choices, privacy-preserving GCNs perform up to 90% of their non-private variants, while formally guaranteeing strong privacy measures.