 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Graph Convolutional Networks for Text Classification
Paper and Code
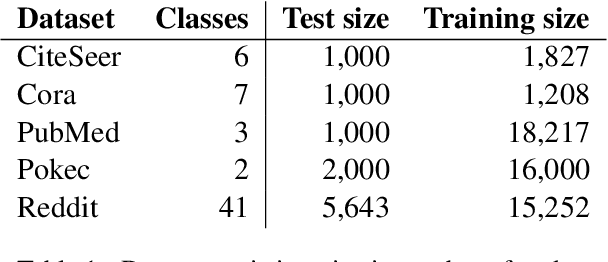
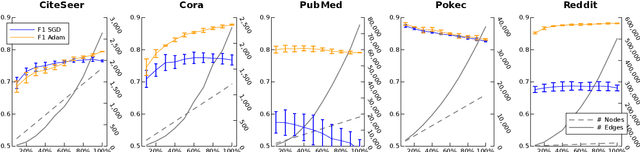
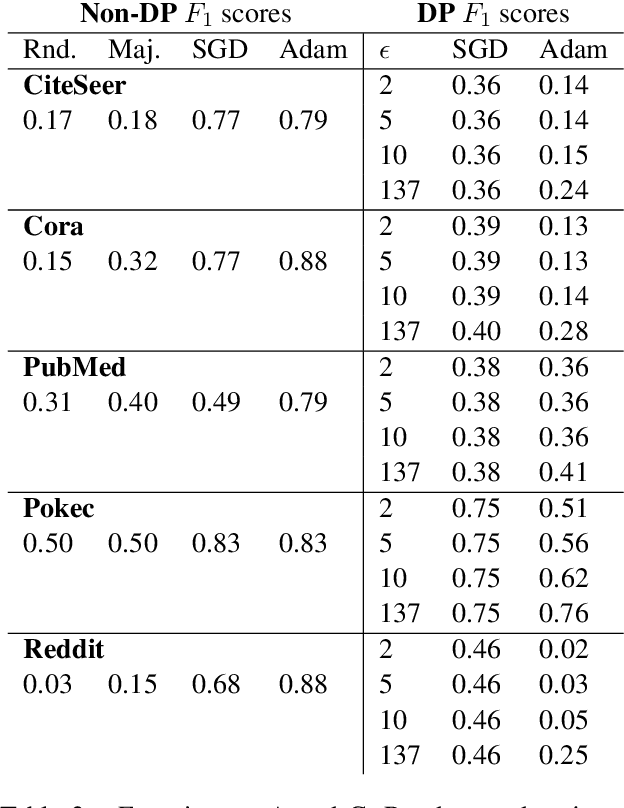
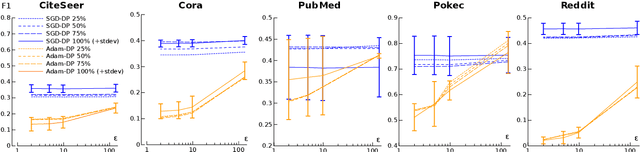
Graph convolutional networks (GCNs) are a powerful architecture for representation learning and making predictions on documents that naturally occur as graphs, e.g., citation or social networks. Data containing sensitive personal information, such as documents with people's profiles or relationships as edges, are prone to privacy leaks from GCNs, as an adversary might reveal the original input from the trained model. Although differential privacy (DP) offers a well-founded privacy-preserving framework, GCNs pose theoretical and practical challenges due to their training specifics. We address these challenges by adapting differentially-private gradient-based training to GCNs. We investigate the impact of various privacy budgets, dataset sizes, and two optimizers in an experimental setup over five NLP datasets in two languages. We show that, under certain modeling choices, privacy-preserving GCNs perform up to 90% of their non-private variants, while formally guaranteeing strong privacy measures.