 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAAD-LLM: Adaptive Anomaly Detection Using LLMs and RAG Integration
Mar 04, 2025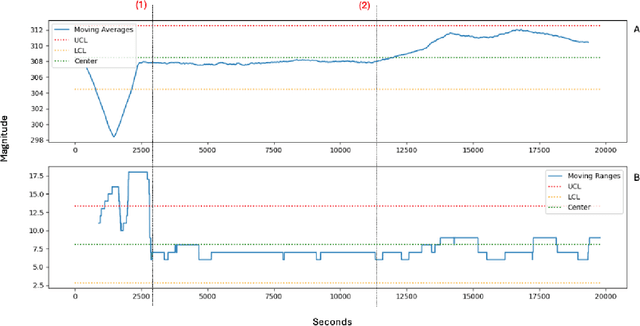
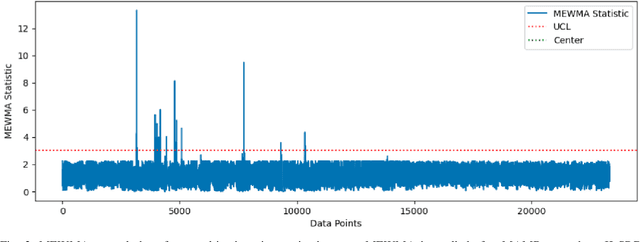
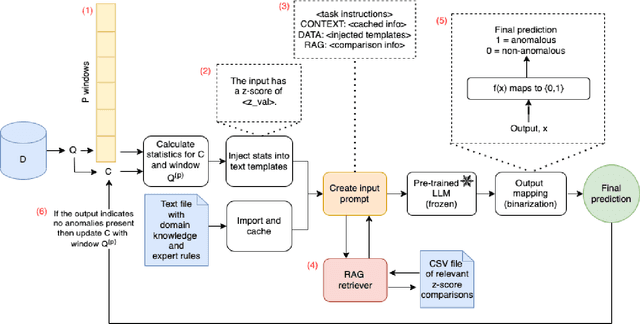
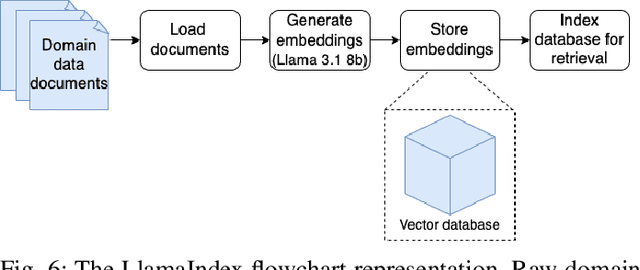
Anomaly detection in complex industrial environments poses unique challenges, particularly in contexts characterized by data sparsity and evolving operational conditions. Predictive maintenance (PdM) in such settings demands methodologies that are adaptive, transferable, and capable of integrating domain-specific knowledge. In this paper, we present RAAD-LLM, a novel framework for adaptive anomaly detection, leveraging large language models (LLMs) integrated with Retrieval-Augmented Generation (RAG). This approach addresses the aforementioned PdM challenges. By effectively utilizing domain-specific knowledge, RAAD-LLM enhances the detection of anomalies in time series data without requiring fine-tuning on specific datasets. The framework's adaptability mechanism enables it to adjust its understanding of normal operating conditions dynamically, thus increasing detection accuracy. We validate this methodology through a real-world application for a plastics manufacturing plant and the Skoltech Anomaly Benchmark (SKAB). Results show significant improvements over our previous model with an accuracy increase from 70.7 to 89.1 on the real-world dataset. By allowing for the enriching of input series data with semantics, RAAD-LLM incorporates multimodal capabilities that facilitate more collaborative decision-making between the model and plant operators. Overall, our findings support RAAD-LLM's ability to revolutionize anomaly detection methodologies in PdM, potentially leading to a paradigm shift in how anomaly detection is implemented across various industries.
AAD-LLM: Adaptive Anomaly Detection Using Large Language Models
Nov 01, 2024



For data-constrained, complex and dynamic industrial environments, there is a critical need for transferable and multimodal methodologies to enhance anomaly detection and therefore, prevent costs associated with system failures. Typically, traditional PdM approaches are not transferable or multimodal. This work examines the use of Large Language Models (LLMs) for anomaly detection in complex and dynamic manufacturing systems. The research aims to improve the transferability of anomaly detection models by leveraging Large Language Models (LLMs) and seeks to validate the enhanced effectiveness of the proposed approach in data-sparse industrial applications. The research also seeks to enable more collaborative decision-making between the model and plant operators by allowing for the enriching of input series data with semantics. Additionally, the research aims to address the issue of concept drift in dynamic industrial settings by integrating an adaptability mechanism. The literature review examines the latest developments in LLM time series tasks alongside associated adaptive anomaly detection methods to establish a robust theoretical framework for the proposed architecture. This paper presents a novel model framework (AAD-LLM) that doesn't require any training or finetuning on the dataset it is applied to and is multimodal. Results suggest that anomaly detection can be converted into a "language" task to deliver effective, context-aware detection in data-constrained industrial applications. This work, therefore, contributes significantly to advancements in anomaly detection methodologies.
Explainable Anomaly Detection: Counterfactual driven What-If Analysis
Aug 21, 2024



There exists three main areas of study inside of the field of predictive maintenance: anomaly detection, fault diagnosis, and remaining useful life prediction. Notably, anomaly detection alerts the stakeholder that an anomaly is occurring. This raises two fundamental questions: what is causing the fault and how can we fix it? Inside of the field of explainable artificial intelligence, counterfactual explanations can give that information in the form of what changes to make to put the data point into the opposing class, in this case "healthy". The suggestions are not always actionable which may raise the interest in asking "what if we do this instead?" In this work, we provide a proof of concept for utilizing counterfactual explanations as what-if analysis. We perform this on the PRONOSTIA dataset with a temporal convolutional network as the anomaly detector. Our method presents the counterfactuals in the form of a what-if analysis for this base problem to inspire future work for more complex systems and scenarios.
A Survey of Transformer Enabled Time Series Synthesis
Jun 04, 2024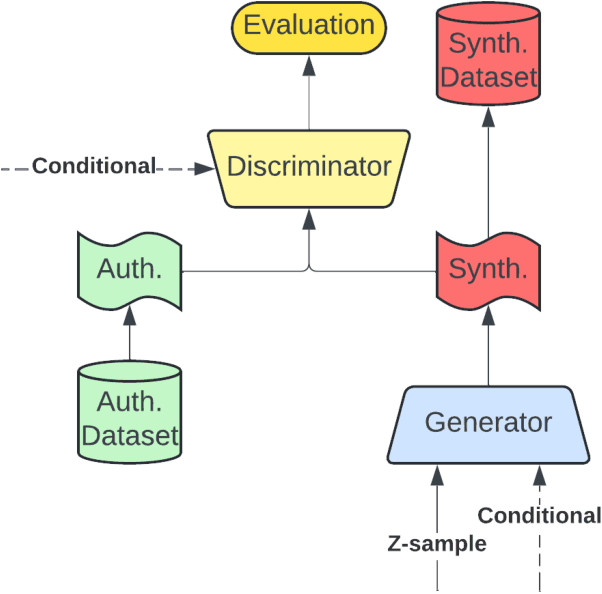
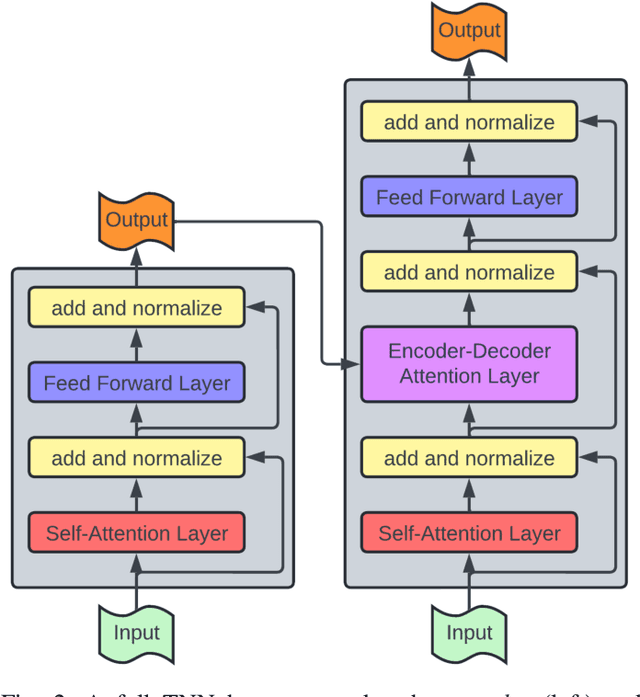


Generative AI has received much attention in the image and language domains, with the transformer neural network continuing to dominate the state of the art. Application of these models to time series generation is less explored, however, and is of great utility to machine learning, privacy preservation, and explainability research. The present survey identifies this gap at the intersection of the transformer, generative AI, and time series data, and reviews works in this sparsely populated subdomain. The reviewed works show great variety in approach, and have not yet converged on a conclusive answer to the problems the domain poses. GANs, diffusion models, state space models, and autoencoders were all encountered alongside or surrounding the transformers which originally motivated the survey. While too open a domain to offer conclusive insights, the works surveyed are quite suggestive, and several recommendations for best practice, and suggestions of valuable future work, are provided.
SemEval-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Apr 22, 2024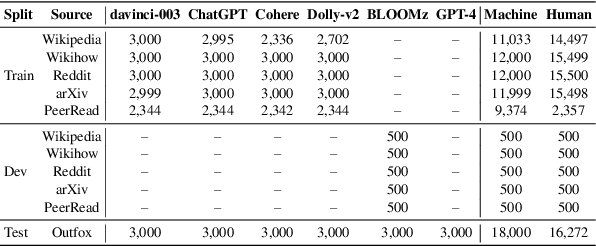

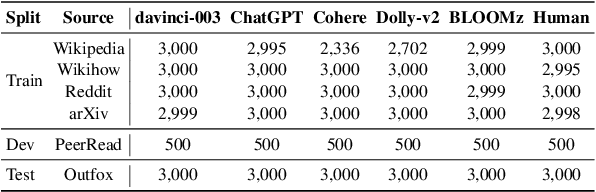

We present the results and the main findings of SemEval-2024 Task 8: Multigenerator, Multidomain, and Multilingual Machine-Generated Text Detection. The task featured three subtasks. Subtask A is a binary classification task determining whether a text is written by a human or generated by a machine. This subtask has two tracks: a monolingual track focused solely on English texts and a multilingual track. Subtask B is to detect the exact source of a text, discerning whether it is written by a human or generated by a specific LLM. Subtask C aims to identify the changing point within a text, at which the authorship transitions from human to machine. The task attracted a large number of participants: subtask A monolingual (126), subtask A multilingual (59), subtask B (70), and subtask C (30). In this paper, we present the task, analyze the results, and discuss the system submissions and the methods they used. For all subtasks, the best systems used LLMs.
* 23 pages, 12 tables
M4GT-Bench: Evaluation Benchmark for Black-Box Machine-Generated Text Detection
Feb 17, 2024



The advent of Large Language Models (LLMs) has brought an unprecedented surge in machine-generated text (MGT) across diverse channels. This raises legitimate concerns about its potential misuse and societal implications. The need to identify and differentiate such content from genuine human-generated text is critical in combating disinformation, preserving the integrity of education and scientific fields, and maintaining trust in communication. In this work, we address this problem by introducing a new benchmark involving multilingual, multi-domain and multi-generator for MGT detection -- M4GT-Bench. It is collected for three task formulations: (1) mono-lingual and multi-lingual binary MGT detection; (2) multi-way detection identifies which particular model generates the text; and (3) human-machine mixed text detection, where a word boundary delimiting MGT from human-written content should be determined. Human evaluation for Task 2 shows less than random guess performance, demonstrating the challenges to distinguish unique LLMs. Promising results always occur when training and test data distribute within the same domain or generators.
DP-Rewrite: Towards Reproducibility and Transparency in Differentially Private Text Rewriting
Aug 22, 2022
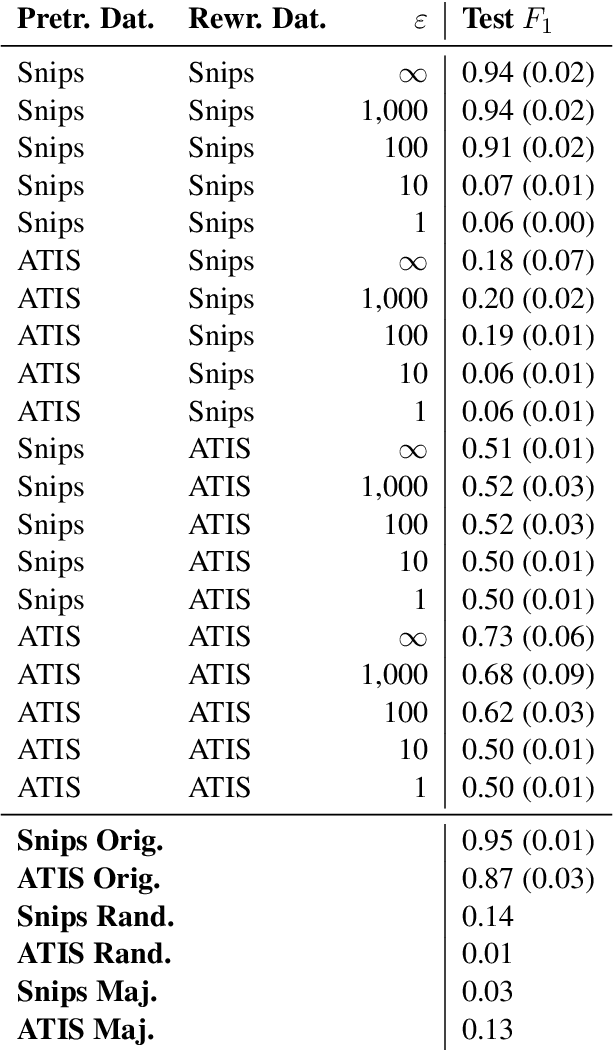
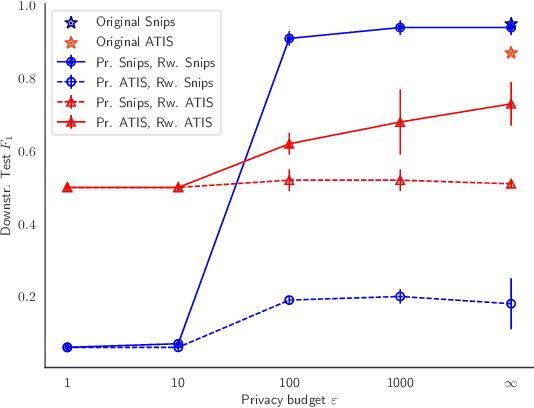

Text rewriting with differential privacy (DP) provides concrete theoretical guarantees for protecting the privacy of individuals in textual documents. In practice, existing systems may lack the means to validate their privacy-preserving claims, leading to problems of transparency and reproducibility. We introduce DP-Rewrite, an open-source framework for differentially private text rewriting which aims to solve these problems by being modular, extensible, and highly customizable. Our system incorporates a variety of downstream datasets, models, pre-training procedures, and evaluation metrics to provide a flexible way to lead and validate private text rewriting research. To demonstrate our software in practice, we provide a set of experiments as a case study on the ADePT DP text rewriting system, detecting a privacy leak in its pre-training approach. Our system is publicly available, and we hope that it will help the community to make DP text rewriting research more accessible and transparent.
When Exceptions are the Norm: Exploring the Role of Consent in HRI
Feb 04, 2019HRI researchers have made major strides in developing robotic architectures that are capable of reading a limited set of social cues and producing behaviors that enhance their likeability and feeling of comfort amongst humans. However, the cues in these models are fairly direct and the interactions largely dyadic. To capture the normative qualities of interaction more robustly, we propose consent as a distinct, critical area for HRI research. Convening important insights in existing HRI work around topics like touch, proxemics, gaze, and moral norms, the notion of consent reveals key expectations that can shape how a robot acts in social space. By sorting various kinds of consent through social and legal doctrine, we delineate empirical and technical questions to meet consent challenges faced in major application domains and robotic roles. Attention to consent could show, for example, how extraordinary, norm-violating actions can be justified by agents and accepted by those around them. We argue that operationalizing ideas from legal scholarship can better guide how robotic systems might cultivate and sustain proper forms of consent.
Quasi-Dilemmas for Artificial Moral Agents
Jul 06, 2018In this paper we describe moral quasi-dilemmas (MQDs): situations similar to moral dilemmas, but in which an agent is unsure whether exploring the plan space or the world may reveal a course of action that satisfies all moral requirements. We argue that artificial moral agents (AMAs) should be built to handle MQDs (in particular, by exploring the plan space rather than immediately accepting the inevitability of the moral dilemma), and that MQDs may be useful for evaluating AMA architectures.
Enabling Basic Normative HRI in a Cognitive Robotic Architecture
Feb 11, 2016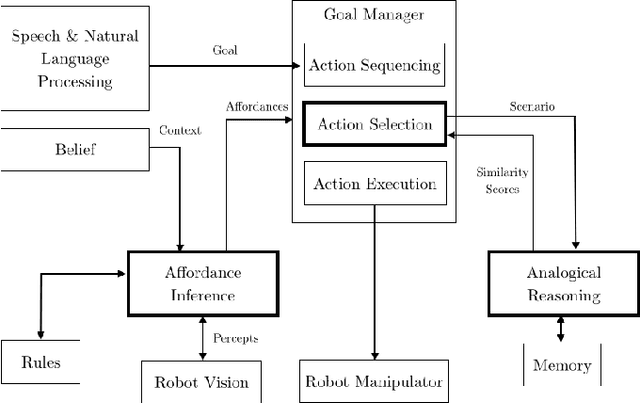
Collaborative human activities are grounded in social and moral norms, which humans consciously and subconsciously use to guide and constrain their decision-making and behavior, thereby strengthening their interactions and preventing emotional and physical harm. This type of norm-based processing is also critical for robots in many human-robot interaction scenarios (e.g., when helping elderly and disabled persons in assisted living facilities, or assisting humans in assembly tasks in factories or even the space station). In this position paper, we will briefly describe how several components in an integrated cognitive architecture can be used to implement processes that are required for normative human-robot interactions, especially in collaborative tasks where actions and situations could potentially be perceived as threatening and thus need a change in course of action to mitigate the perceived threats.