 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Differences in Strategic Behavior Between Humans and LLMs
Feb 10, 2026As Large Language Models (LLMs) are increasingly deployed in social and strategic scenarios, it becomes critical to understand where and why their behavior diverges from that of humans. While behavioral game theory (BGT) provides a framework for analyzing behavior, existing models do not fully capture the idiosyncratic behavior of humans or black-box, non-human agents like LLMs. We employ AlphaEvolve, a cutting-edge program discovery tool, to directly discover interpretable models of human and LLM behavior from data, thereby enabling open-ended discovery of structural factors driving human and LLM behavior. Our analysis on iterated rock-paper-scissors reveals that frontier LLMs can be capable of deeper strategic behavior than humans. These results provide a foundation for understanding structural differences driving differences in human and LLM behavior in strategic interactions.
Evaluating Gemini in an arena for learning
May 30, 2025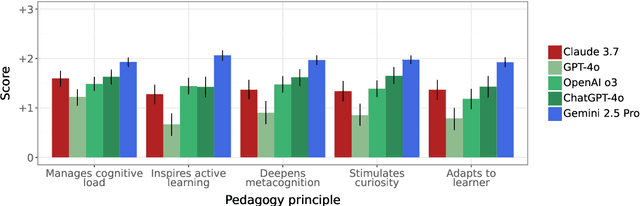

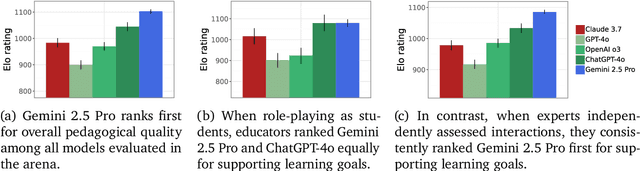
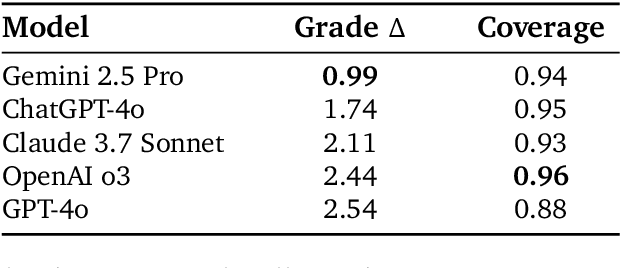
Artificial intelligence (AI) is poised to transform education, but the research community lacks a robust, general benchmark to evaluate AI models for learning. To assess state-of-the-art support for educational use cases, we ran an "arena for learning" where educators and pedagogy experts conduct blind, head-to-head, multi-turn comparisons of leading AI models. In particular, $N = 189$ educators drew from their experience to role-play realistic learning use cases, interacting with two models sequentially, after which $N = 206$ experts judged which model better supported the user's learning goals. The arena evaluated a slate of state-of-the-art models: Gemini 2.5 Pro, Claude 3.7 Sonnet, GPT-4o, and OpenAI o3. Excluding ties, experts preferred Gemini 2.5 Pro in 73.2% of these match-ups -- ranking it first overall in the arena. Gemini 2.5 Pro also demonstrated markedly higher performance across key principles of good pedagogy. Altogether, these results position Gemini 2.5 Pro as a leading model for learning.
LearnLM: Improving Gemini for Learning
Dec 21, 2024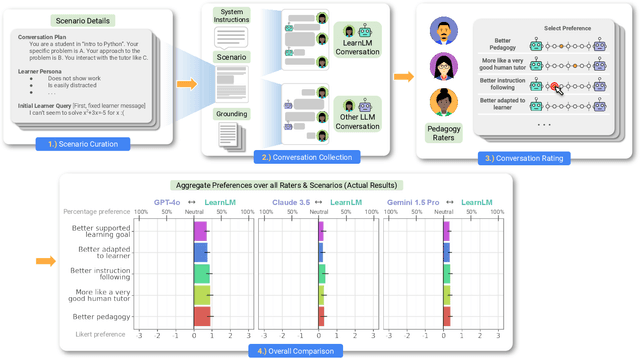
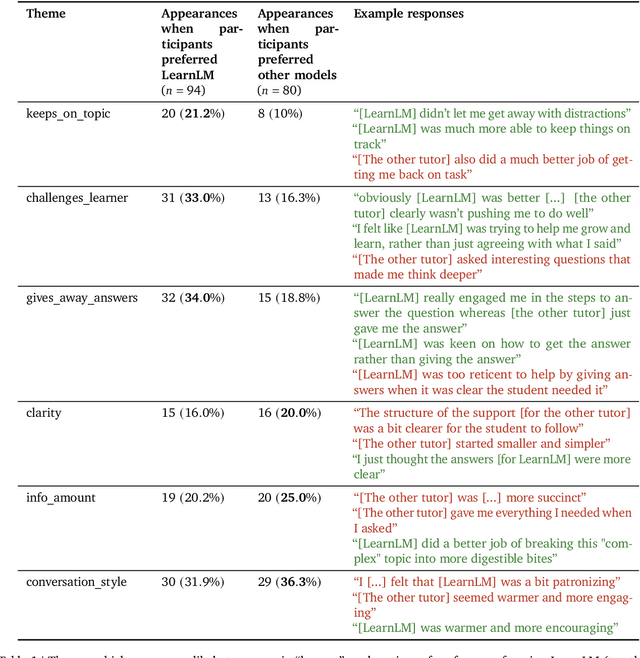
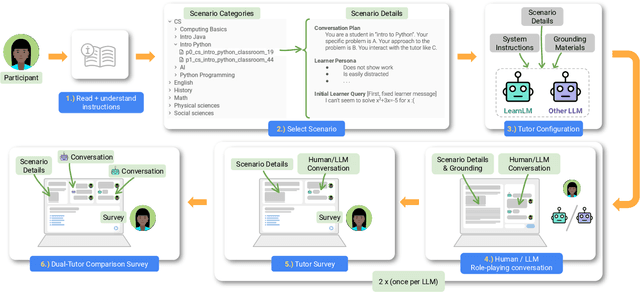
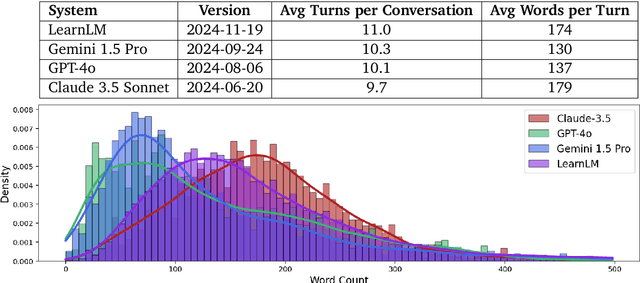
Today's generative AI systems are tuned to present information by default rather than engage users in service of learning as a human tutor would. To address the wide range of potential education use cases for these systems, we reframe the challenge of injecting pedagogical behavior as one of \textit{pedagogical instruction following}, where training and evaluation examples include system-level instructions describing the specific pedagogy attributes present or desired in subsequent model turns. This framing avoids committing our models to any particular definition of pedagogy, and instead allows teachers or developers to specify desired model behavior. It also clears a path to improving Gemini models for learning -- by enabling the addition of our pedagogical data to post-training mixtures -- alongside their rapidly expanding set of capabilities. Both represent important changes from our initial tech report. We show how training with pedagogical instruction following produces a LearnLM model (available on Google AI Studio) that is preferred substantially by expert raters across a diverse set of learning scenarios, with average preference strengths of 31\% over GPT-4o, 11\% over Claude 3.5, and 13\% over the Gemini 1.5 Pro model LearnLM was based on.
SPOTTER: Extending Symbolic Planning Operators through Targeted Reinforcement Learning
Dec 24, 2020



Symbolic planning models allow decision-making agents to sequence actions in arbitrary ways to achieve a variety of goals in dynamic domains. However, they are typically handcrafted and tend to require precise formulations that are not robust to human error. Reinforcement learning (RL) approaches do not require such models, and instead learn domain dynamics by exploring the environment and collecting rewards. However, RL approaches tend to require millions of episodes of experience and often learn policies that are not easily transferable to other tasks. In this paper, we address one aspect of the open problem of integrating these approaches: how can decision-making agents resolve discrepancies in their symbolic planning models while attempting to accomplish goals? We propose an integrated framework named SPOTTER that uses RL to augment and support ("spot") a planning agent by discovering new operators needed by the agent to accomplish goals that are initially unreachable for the agent. SPOTTER outperforms pure-RL approaches while also discovering transferable symbolic knowledge and does not require supervision, successful plan traces or any a priori knowledge about the missing planning operator.
Engaging in Dialogue about an Agent's Norms and Behaviors
Nov 01, 2019
We present a set of capabilities allowing an agent planning with moral and social norms represented in temporal logic to respond to queries about its norms and behaviors in natural language, and for the human user to add and remove norms directly in natural language. The user may also pose hypothetical modifications to the agent's norms and inquire about their effects.
Generating Justifications for Norm-Related Agent Decisions
Nov 01, 2019
We present an approach to generating natural language justifications of decisions derived from norm-based reasoning. Assuming an agent which maximally satisfies a set of rules specified in an object-oriented temporal logic, the user can ask factual questions (about the agent's rules, actions, and the extent to which the agent violated the rules) as well as "why" questions that require the agent comparing actual behavior to counterfactual trajectories with respect to these rules. To produce natural-sounding explanations, we focus on the subproblem of producing natural language clauses from statements in a fragment of temporal logic, and then describe how to embed these clauses into explanatory sentences. We use a human judgment evaluation on a testbed task to compare our approach to variants in terms of intelligibility, mental model and perceived trust.
Quasi-Dilemmas for Artificial Moral Agents
Jul 06, 2018In this paper we describe moral quasi-dilemmas (MQDs): situations similar to moral dilemmas, but in which an agent is unsure whether exploring the plan space or the world may reveal a course of action that satisfies all moral requirements. We argue that artificial moral agents (AMAs) should be built to handle MQDs (in particular, by exploring the plan space rather than immediately accepting the inevitability of the moral dilemma), and that MQDs may be useful for evaluating AMA architectures.
Interpretable Apprenticeship Learning with Temporal Logic Specifications
Oct 28, 2017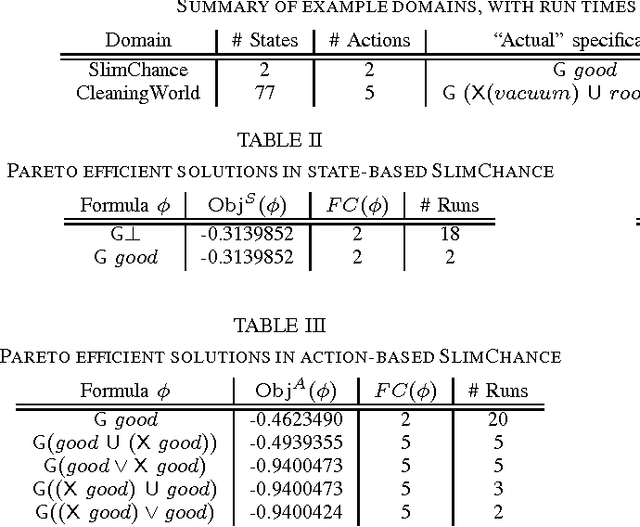
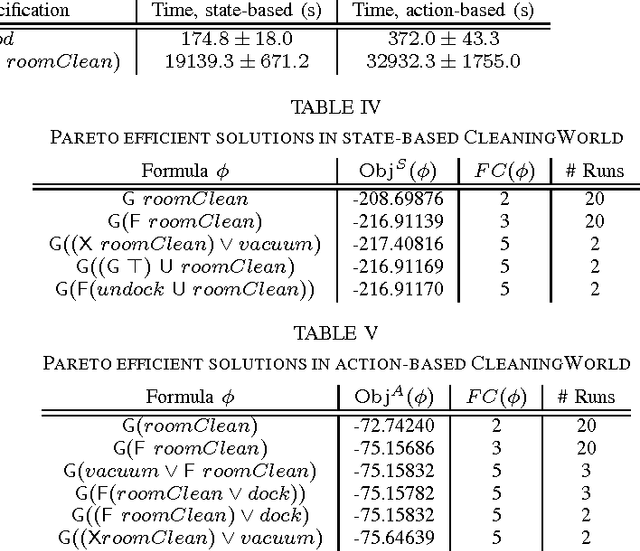
Recent work has addressed using formulas in linear temporal logic (LTL) as specifications for agents planning in Markov Decision Processes (MDPs). We consider the inverse problem: inferring an LTL specification from demonstrated behavior trajectories in MDPs. We formulate this as a multiobjective optimization problem, and describe state-based ("what actually happened") and action-based ("what the agent expected to happen") objective functions based on a notion of "violation cost". We demonstrate the efficacy of the approach by employing genetic programming to solve this problem in two simple domains.