 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovelty Adaptation Through Hybrid Large Language Model (LLM)-Symbolic Planning and LLM-guided Reinforcement Learning
Mar 11, 2026In dynamic open-world environments, autonomous agents often encounter novelties that hinder their ability to find plans to achieve their goals. Specifically, traditional symbolic planners fail to generate plans when the robot's planning domain lacks the operators that enable it to interact appropriately with novel objects in the environment. We propose a neuro-symbolic architecture that integrates symbolic planning, reinforcement learning, and a large language model (LLM) to learn how to handle novel objects. In particular, we leverage the common sense reasoning capability of the LLM to identify missing operators, generate plans with the symbolic AI planner, and write reward functions to guide the reinforcement learning agent in learning control policies for newly identified operators. Our method outperforms the state-of-the-art methods in operator discovery as well as operator learning in continuous robotic domains.
Mapping Neural Signals to Agent Performance, A Step Towards Reinforcement Learning from Neural Feedback
Jun 14, 2025Implicit Human-in-the-Loop Reinforcement Learning (HITL-RL) is a methodology that integrates passive human feedback into autonomous agent training while minimizing human workload. However, existing methods often rely on active instruction, requiring participants to teach an agent through unnatural expression or gesture. We introduce NEURO-LOOP, an implicit feedback framework that utilizes the intrinsic human reward system to drive human-agent interaction. This work demonstrates the feasibility of a critical first step in the NEURO-LOOP framework: mapping brain signals to agent performance. Using functional near-infrared spectroscopy (fNIRS), we design a dataset to enable future research using passive Brain-Computer Interfaces for Human-in-the-Loop Reinforcement Learning. Participants are instructed to observe or guide a reinforcement learning agent in its environment while signals from the prefrontal cortex are collected. We conclude that a relationship between fNIRS data and agent performance exists using classical machine learning techniques. Finally, we highlight the potential that neural interfaces may offer to future applications of human-agent interaction, assistive AI, and adaptive autonomous systems.
FLEX: A Framework for Learning Robot-Agnostic Force-based Skills Involving Sustained Contact Object Manipulation
Mar 17, 2025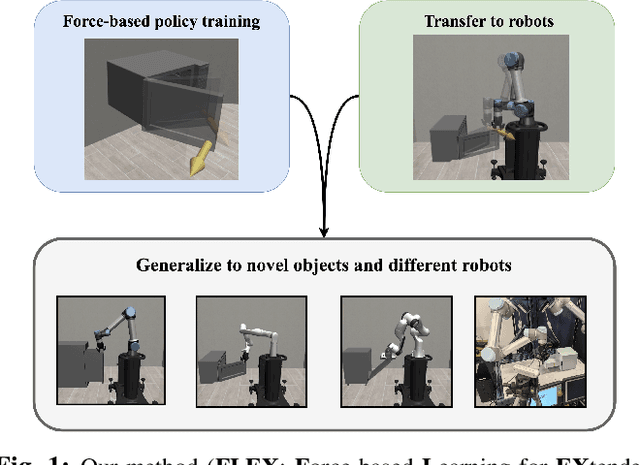
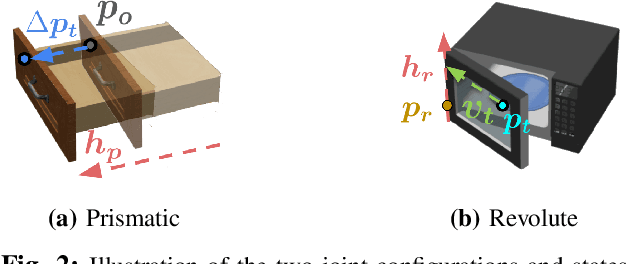
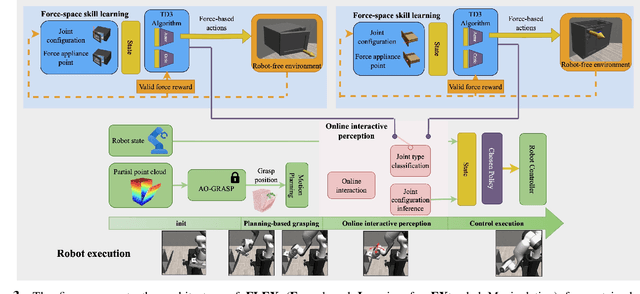
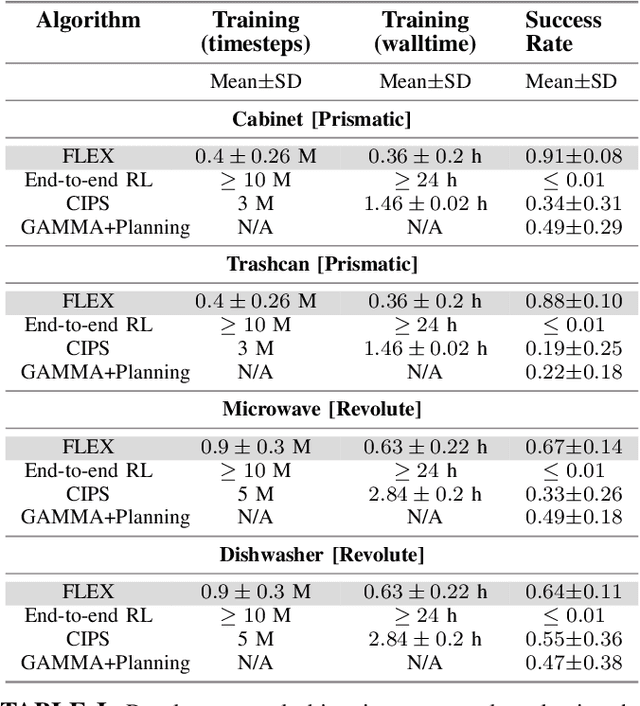
Learning to manipulate objects efficiently, particularly those involving sustained contact (e.g., pushing, sliding) and articulated parts (e.g., drawers, doors), presents significant challenges. Traditional methods, such as robot-centric reinforcement learning (RL), imitation learning, and hybrid techniques, require massive training and often struggle to generalize across different objects and robot platforms. We propose a novel framework for learning object-centric manipulation policies in force space, decoupling the robot from the object. By directly applying forces to selected regions of the object, our method simplifies the action space, reduces unnecessary exploration, and decreases simulation overhead. This approach, trained in simulation on a small set of representative objects, captures object dynamics -- such as joint configurations -- allowing policies to generalize effectively to new, unseen objects. Decoupling these policies from robot-specific dynamics enables direct transfer to different robotic platforms (e.g., Kinova, Panda, UR5) without retraining. Our evaluations demonstrate that the method significantly outperforms baselines, achieving over an order of magnitude improvement in training efficiency compared to other state-of-the-art methods. Additionally, operating in force space enhances policy transferability across diverse robot platforms and object types. We further showcase the applicability of our method in a real-world robotic setting. For supplementary materials and videos, please visit: https://tufts-ai-robotics-group.github.io/FLEX/
Creative Problem Solving in Large Language and Vision Models -- What Would it Take?
May 02, 2024



In this paper, we discuss approaches for integrating Computational Creativity (CC) with research in large language and vision models (LLVMs) to address a key limitation of these models, i.e., creative problem solving. We present preliminary experiments showing how CC principles can be applied to address this limitation through augmented prompting. With this work, we hope to foster discussions of Computational Creativity in the context of ML algorithms for creative problem solving in LLVMs. Our code is at: https://github.com/lnairGT/creative-problem-solving-LLMs
Dialogue with Robots: Proposals for Broadening Participation and Research in the SLIVAR Community
Apr 01, 2024
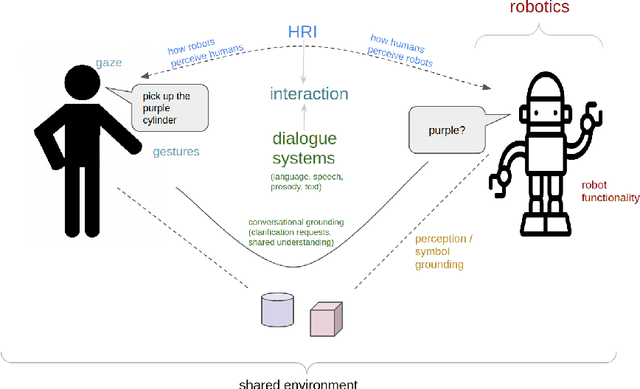
The ability to interact with machines using natural human language is becoming not just commonplace, but expected. The next step is not just text interfaces, but speech interfaces and not just with computers, but with all machines including robots. In this paper, we chronicle the recent history of this growing field of spoken dialogue with robots and offer the community three proposals, the first focused on education, the second on benchmarks, and the third on the modeling of language when it comes to spoken interaction with robots. The three proposals should act as white papers for any researcher to take and build upon.
Logical Specifications-guided Dynamic Task Sampling for Reinforcement Learning Agents
Feb 08, 2024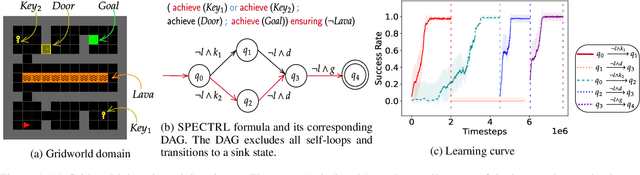

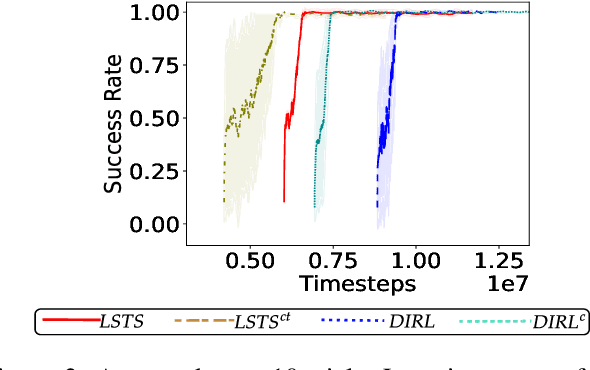

Reinforcement Learning (RL) has made significant strides in enabling artificial agents to learn diverse behaviors. However, learning an effective policy often requires a large number of environment interactions. To mitigate sample complexity issues, recent approaches have used high-level task specifications, such as Linear Temporal Logic (LTL$_f$) formulas or Reward Machines (RM), to guide the learning progress of the agent. In this work, we propose a novel approach, called Logical Specifications-guided Dynamic Task Sampling (LSTS), that learns a set of RL policies to guide an agent from an initial state to a goal state based on a high-level task specification, while minimizing the number of environmental interactions. Unlike previous work, LSTS does not assume information about the environment dynamics or the Reward Machine, and dynamically samples promising tasks that lead to successful goal policies. We evaluate LSTS on a gridworld and show that it achieves improved time-to-threshold performance on complex sequential decision-making problems compared to state-of-the-art RM and Automaton-guided RL baselines, such as Q-Learning for Reward Machines and Compositional RL from logical Specifications (DIRL). Moreover, we demonstrate that our method outperforms RM and Automaton-guided RL baselines in terms of sample-efficiency, both in a partially observable robotic task and in a continuous control robotic manipulation task.
NovelGym: A Flexible Ecosystem for Hybrid Planning and Learning Agents Designed for Open Worlds
Jan 07, 2024



As AI agents leave the lab and venture into the real world as autonomous vehicles, delivery robots, and cooking robots, it is increasingly necessary to design and comprehensively evaluate algorithms that tackle the ``open-world''. To this end, we introduce NovelGym, a flexible and adaptable ecosystem designed to simulate gridworld environments, serving as a robust platform for benchmarking reinforcement learning (RL) and hybrid planning and learning agents in open-world contexts. The modular architecture of NovelGym facilitates rapid creation and modification of task environments, including multi-agent scenarios, with multiple environment transformations, thus providing a dynamic testbed for researchers to develop open-world AI agents.
LgTS: Dynamic Task Sampling using LLM-generated sub-goals for Reinforcement Learning Agents
Oct 14, 2023



Recent advancements in reasoning abilities of Large Language Models (LLM) has promoted their usage in problems that require high-level planning for robots and artificial agents. However, current techniques that utilize LLMs for such planning tasks make certain key assumptions such as, access to datasets that permit finetuning, meticulously engineered prompts that only provide relevant and essential information to the LLM, and most importantly, a deterministic approach to allow execution of the LLM responses either in the form of existing policies or plan operators. In this work, we propose LgTS (LLM-guided Teacher-Student learning), a novel approach that explores the planning abilities of LLMs to provide a graphical representation of the sub-goals to a reinforcement learning (RL) agent that does not have access to the transition dynamics of the environment. The RL agent uses Teacher-Student learning algorithm to learn a set of successful policies for reaching the goal state from the start state while simultaneously minimizing the number of environmental interactions. Unlike previous methods that utilize LLMs, our approach does not assume access to a propreitary or a fine-tuned LLM, nor does it require pre-trained policies that achieve the sub-goals proposed by the LLM. Through experiments on a gridworld based DoorKey domain and a search-and-rescue inspired domain, we show that generating a graphical structure of sub-goals helps in learning policies for the LLM proposed sub-goals and the Teacher-Student learning algorithm minimizes the number of environment interactions when the transition dynamics are unknown.
A Framework for Few-Shot Policy Transfer through Observation Mapping and Behavior Cloning
Oct 13, 2023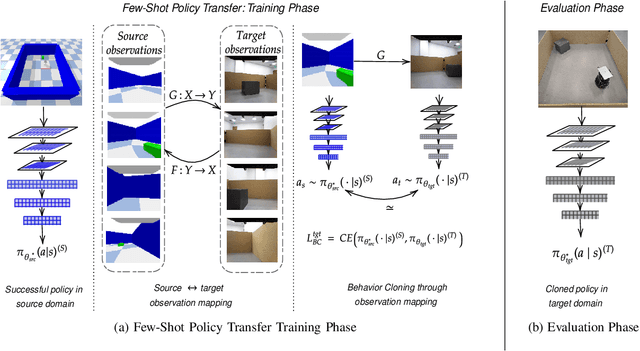
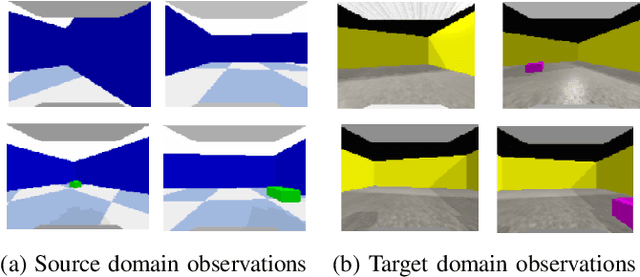
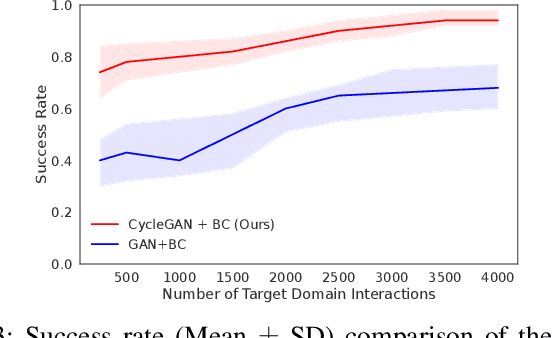
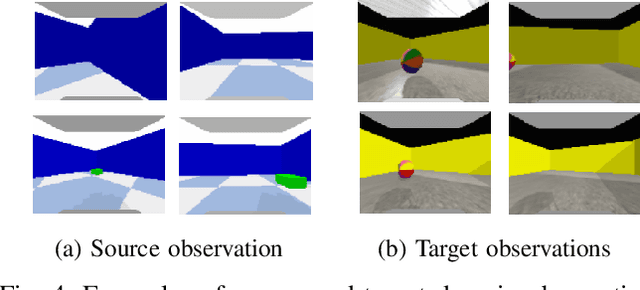
Despite recent progress in Reinforcement Learning for robotics applications, many tasks remain prohibitively difficult to solve because of the expensive interaction cost. Transfer learning helps reduce the training time in the target domain by transferring knowledge learned in a source domain. Sim2Real transfer helps transfer knowledge from a simulated robotic domain to a physical target domain. Knowledge transfer reduces the time required to train a task in the physical world, where the cost of interactions is high. However, most existing approaches assume exact correspondence in the task structure and the physical properties of the two domains. This work proposes a framework for Few-Shot Policy Transfer between two domains through Observation Mapping and Behavior Cloning. We use Generative Adversarial Networks (GANs) along with a cycle-consistency loss to map the observations between the source and target domains and later use this learned mapping to clone the successful source task behavior policy to the target domain. We observe successful behavior policy transfer with limited target task interactions and in cases where the source and target task are semantically dissimilar.
MOSAIC: Learning Unified Multi-Sensory Object Property Representations for Robot Perception
Sep 15, 2023A holistic understanding of object properties across diverse sensory modalities (e.g., visual, audio, and haptic) is essential for tasks ranging from object categorization to complex manipulation. Drawing inspiration from cognitive science studies that emphasize the significance of multi-sensory integration in human perception, we introduce MOSAIC (Multi-modal Object property learning with Self-Attention and Integrated Comprehension), a novel framework designed to facilitate the learning of unified multi-sensory object property representations. While it is undeniable that visual information plays a prominent role, we acknowledge that many fundamental object properties extend beyond the visual domain to encompass attributes like texture, mass distribution, or sounds, which significantly influence how we interact with objects. In MOSAIC, we leverage this profound insight by distilling knowledge from the extensive pre-trained Contrastive Language-Image Pre-training (CLIP) model, aligning these representations not only across vision but also haptic and auditory sensory modalities. Through extensive experiments on a dataset where a humanoid robot interacts with 100 objects across 10 exploratory behaviors, we demonstrate the versatility of MOSAIC in two task families: object categorization and object-fetching tasks. Our results underscore the efficacy of MOSAIC's unified representations, showing competitive performance in category recognition through a simple linear probe setup and excelling in the fetch object task under zero-shot transfer conditions. This work pioneers the application of CLIP-based sensory grounding in robotics, promising a significant leap in multi-sensory perception capabilities for autonomous systems. We have released the code, datasets, and additional results: https://github.com/gtatiya/MOSAIC.