 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptManip: Learning Adaptive Whole-Body Object Lifting and Delivery with Online Recurrent State Estimation
Feb 16, 2026This paper presents Adaptive Whole-body Loco-Manipulation, AdaptManip, a fully autonomous framework for humanoid robots to perform integrated navigation, object lifting, and delivery. Unlike prior imitation learning-based approaches that rely on human demonstrations and are often brittle to disturbances, AdaptManip aims to train a robust loco-manipulation policy via reinforcement learning without human demonstrations or teleoperation data. The proposed framework consists of three coupled components: (1) a recurrent object state estimator that tracks the manipulated object in real time under limited field-of-view and occlusions; (2) a whole-body base policy for robust locomotion with residual manipulation control for stable object lifting and delivery; and (3) a LiDAR-based robot global position estimator that provides drift-robust localization. All components are trained in simulation using reinforcement learning and deployed on real hardware in a zero-shot manner. Experimental results show that AdaptManip significantly outperforms baseline methods, including imitation learning-based approaches, in adaptability and overall success rate, while accurate object state estimation improves manipulation performance even under occlusion. We further demonstrate fully autonomous real-world navigation, object lifting, and delivery on a humanoid robot.
L-FUSION: Laplacian Fetal Ultrasound Segmentation & Uncertainty Estimation
Mar 07, 2025

Accurate analysis of prenatal ultrasound (US) is essential for early detection of developmental anomalies. However, operator dependency and technical limitations (e.g. intrinsic artefacts and effects, setting errors) can complicate image interpretation and the assessment of diagnostic uncertainty. We present L-FUSION (Laplacian Fetal US Segmentation with Integrated FoundatiON models), a framework that integrates uncertainty quantification through unsupervised, normative learning and large-scale foundation models for robust segmentation of fetal structures in normal and pathological scans. We propose to utilise the aleatoric logit distributions of Stochastic Segmentation Networks and Laplace approximations with fast Hessian estimations to estimate epistemic uncertainty only from the segmentation head. This enables us to achieve reliable abnormality quantification for instant diagnostic feedback. Combined with an integrated Dropout component, L-FUSION enables reliable differentiation of lesions from normal fetal anatomy with enhanced uncertainty maps and segmentation counterfactuals in US imaging. It improves epistemic and aleatoric uncertainty interpretation and removes the need for manual disease-labelling. Evaluations across multiple datasets show that L-FUSION achieves superior segmentation accuracy and consistent uncertainty quantification, supporting on-site decision-making and offering a scalable solution for advancing fetal ultrasound analysis in clinical settings.
PrivilegedDreamer: Explicit Imagination of Privileged Information for Rapid Adaptation of Learned Policies
Feb 17, 2025Numerous real-world control problems involve dynamics and objectives affected by unobservable hidden parameters, ranging from autonomous driving to robotic manipulation, which cause performance degradation during sim-to-real transfer. To represent these kinds of domains, we adopt hidden-parameter Markov decision processes (HIP-MDPs), which model sequential decision problems where hidden variables parameterize transition and reward functions. Existing approaches, such as domain randomization, domain adaptation, and meta-learning, simply treat the effect of hidden parameters as additional variance and often struggle to effectively handle HIP-MDP problems, especially when the rewards are parameterized by hidden variables. We introduce Privileged-Dreamer, a model-based reinforcement learning framework that extends the existing model-based approach by incorporating an explicit parameter estimation module. PrivilegedDreamer features its novel dual recurrent architecture that explicitly estimates hidden parameters from limited historical data and enables us to condition the model, actor, and critic networks on these estimated parameters. Our empirical analysis on five diverse HIP-MDP tasks demonstrates that PrivilegedDreamer outperforms state-of-the-art model-based, model-free, and domain adaptation learning algorithms. Additionally, we conduct ablation studies to justify the inclusion of each component in the proposed architecture.
Logical Specifications-guided Dynamic Task Sampling for Reinforcement Learning Agents
Feb 08, 2024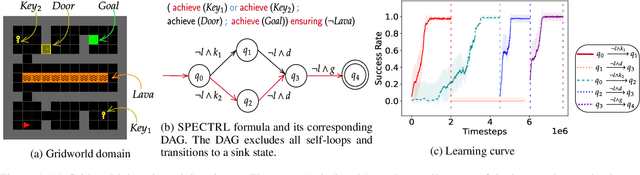

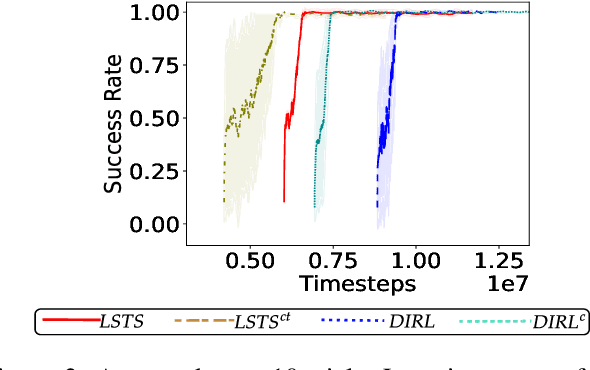

Reinforcement Learning (RL) has made significant strides in enabling artificial agents to learn diverse behaviors. However, learning an effective policy often requires a large number of environment interactions. To mitigate sample complexity issues, recent approaches have used high-level task specifications, such as Linear Temporal Logic (LTL$_f$) formulas or Reward Machines (RM), to guide the learning progress of the agent. In this work, we propose a novel approach, called Logical Specifications-guided Dynamic Task Sampling (LSTS), that learns a set of RL policies to guide an agent from an initial state to a goal state based on a high-level task specification, while minimizing the number of environmental interactions. Unlike previous work, LSTS does not assume information about the environment dynamics or the Reward Machine, and dynamically samples promising tasks that lead to successful goal policies. We evaluate LSTS on a gridworld and show that it achieves improved time-to-threshold performance on complex sequential decision-making problems compared to state-of-the-art RM and Automaton-guided RL baselines, such as Q-Learning for Reward Machines and Compositional RL from logical Specifications (DIRL). Moreover, we demonstrate that our method outperforms RM and Automaton-guided RL baselines in terms of sample-efficiency, both in a partially observable robotic task and in a continuous control robotic manipulation task.
Whole-examination AI estimation of fetal biometrics from 20-week ultrasound scans
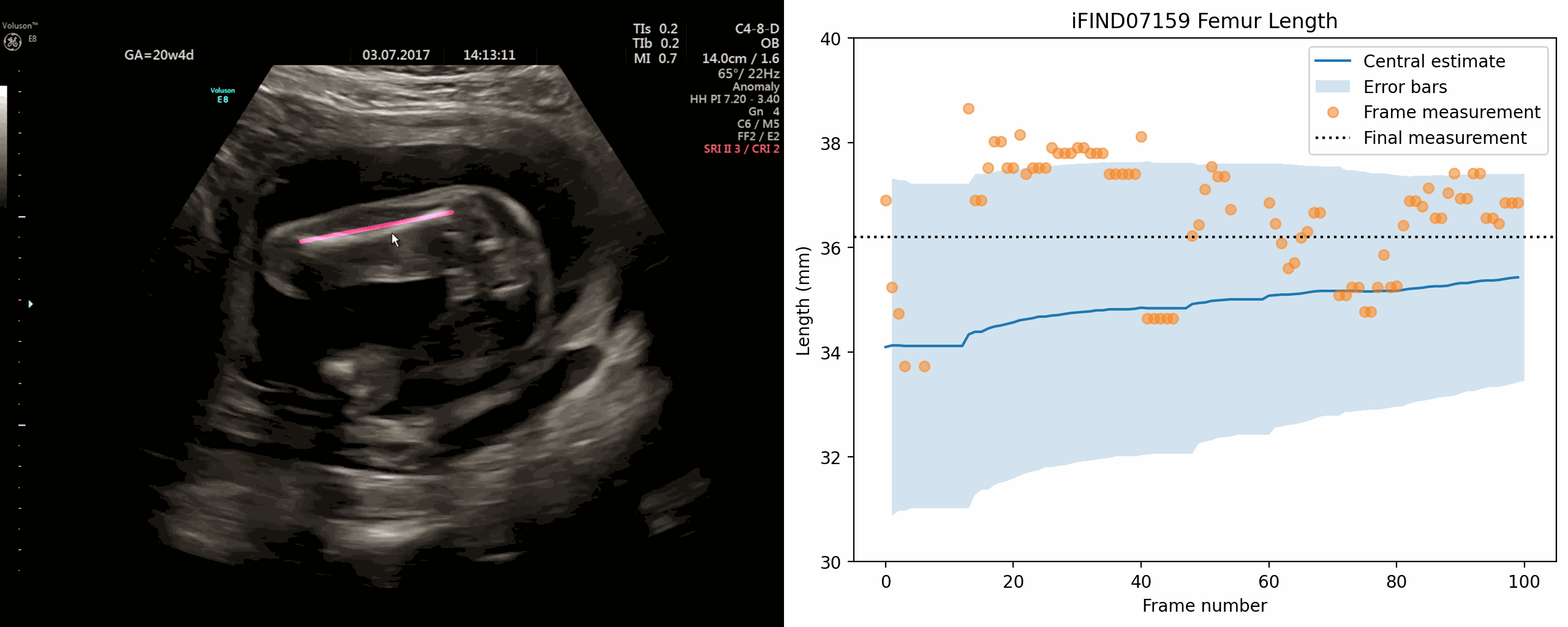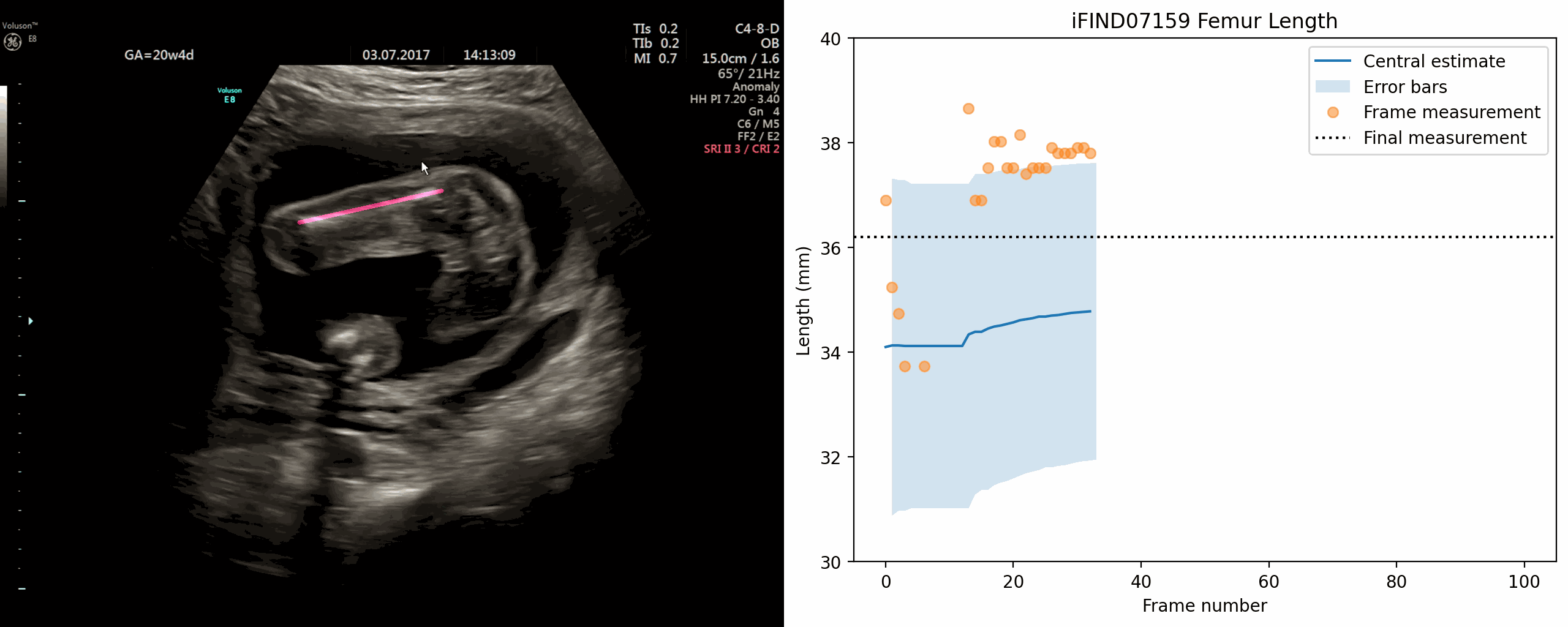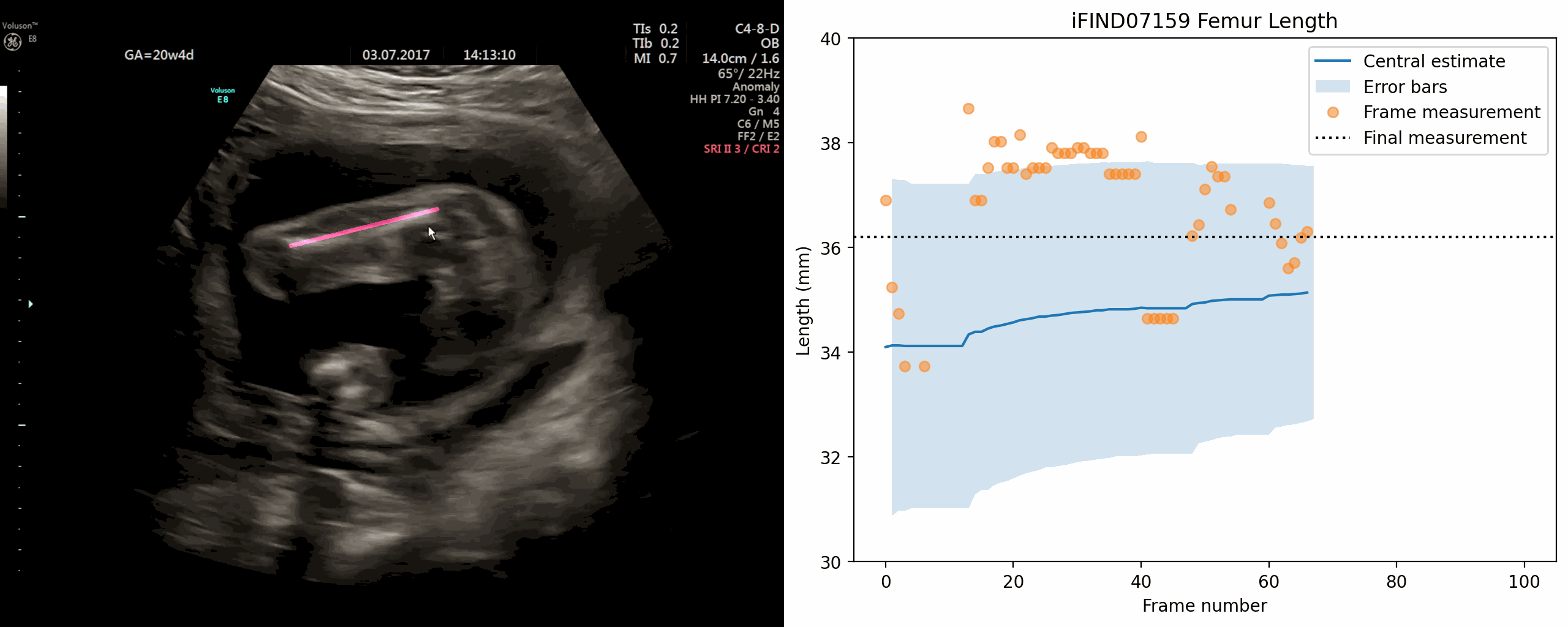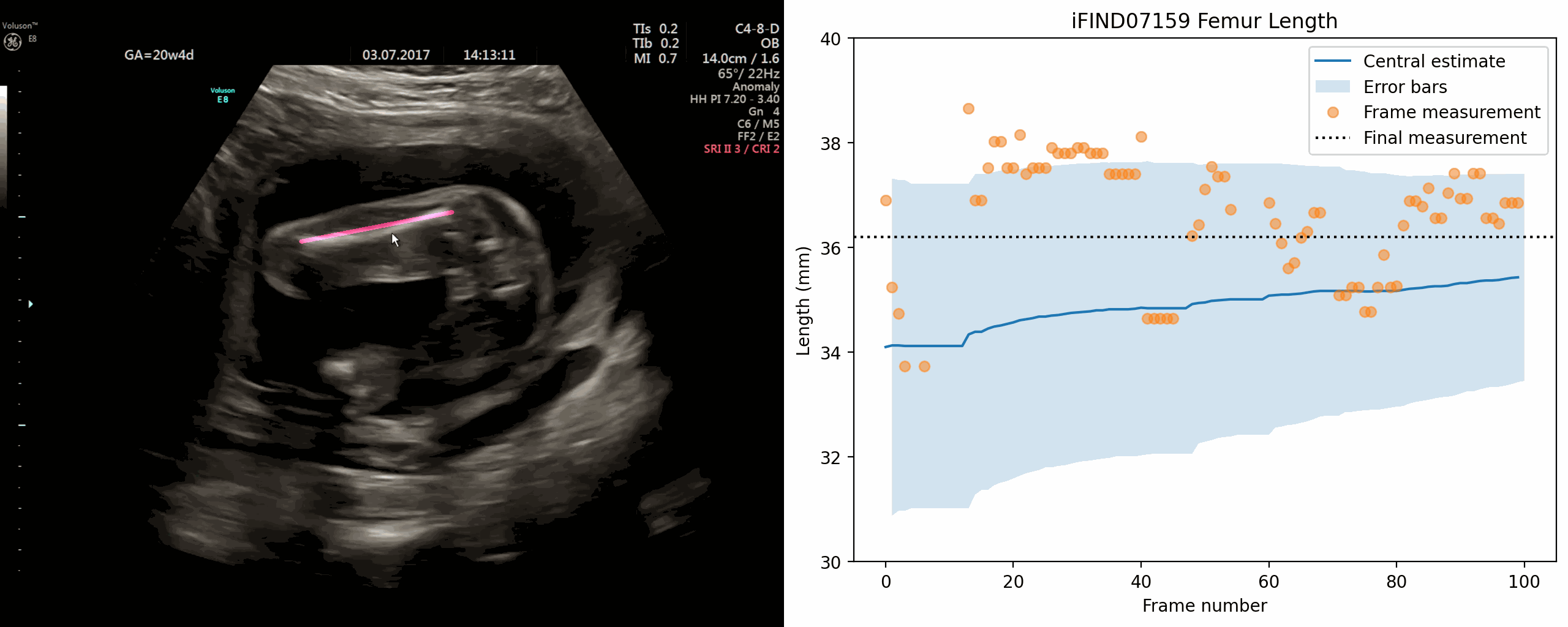
Jan 02, 2024The current approach to fetal anomaly screening is based on biometric measurements derived from individually selected ultrasound images. In this paper, we introduce a paradigm shift that attains human-level performance in biometric measurement by aggregating automatically extracted biometrics from every frame across an entire scan, with no need for operator intervention. We use a convolutional neural network to classify each frame of an ultrasound video recording. We then measure fetal biometrics in every frame where appropriate anatomy is visible. We use a Bayesian method to estimate the true value of each biometric from a large number of measurements and probabilistically reject outliers. We performed a retrospective experiment on 1457 recordings (comprising 48 million frames) of 20-week ultrasound scans, estimated fetal biometrics in those scans and compared our estimates to the measurements sonographers took during the scan. Our method achieves human-level performance in estimating fetal biometrics and estimates well-calibrated credible intervals in which the true biometric value is expected to lie.
{kind=link}
LgTS: Dynamic Task Sampling using LLM-generated sub-goals for Reinforcement Learning Agents
Oct 14, 2023



Recent advancements in reasoning abilities of Large Language Models (LLM) has promoted their usage in problems that require high-level planning for robots and artificial agents. However, current techniques that utilize LLMs for such planning tasks make certain key assumptions such as, access to datasets that permit finetuning, meticulously engineered prompts that only provide relevant and essential information to the LLM, and most importantly, a deterministic approach to allow execution of the LLM responses either in the form of existing policies or plan operators. In this work, we propose LgTS (LLM-guided Teacher-Student learning), a novel approach that explores the planning abilities of LLMs to provide a graphical representation of the sub-goals to a reinforcement learning (RL) agent that does not have access to the transition dynamics of the environment. The RL agent uses Teacher-Student learning algorithm to learn a set of successful policies for reaching the goal state from the start state while simultaneously minimizing the number of environmental interactions. Unlike previous methods that utilize LLMs, our approach does not assume access to a propreitary or a fine-tuned LLM, nor does it require pre-trained policies that achieve the sub-goals proposed by the LLM. Through experiments on a gridworld based DoorKey domain and a search-and-rescue inspired domain, we show that generating a graphical structure of sub-goals helps in learning policies for the LLM proposed sub-goals and the Teacher-Student learning algorithm minimizes the number of environment interactions when the transition dynamics are unknown.
A Framework for Few-Shot Policy Transfer through Observation Mapping and Behavior Cloning
Oct 13, 2023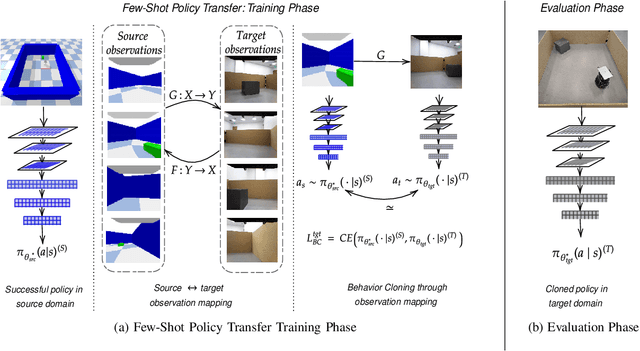
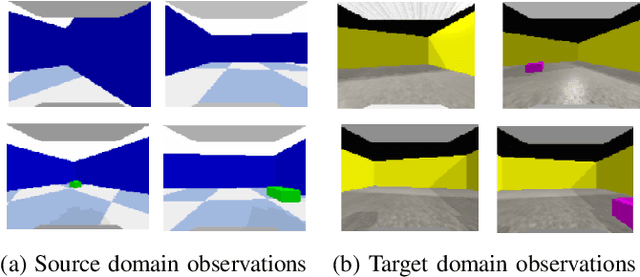
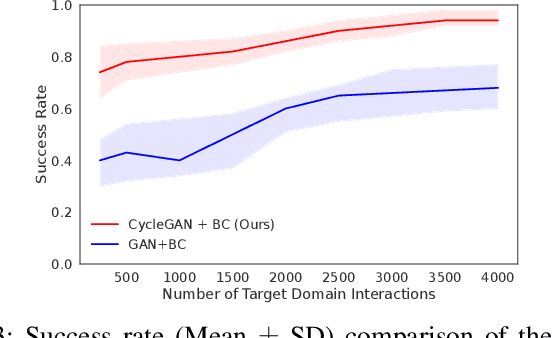
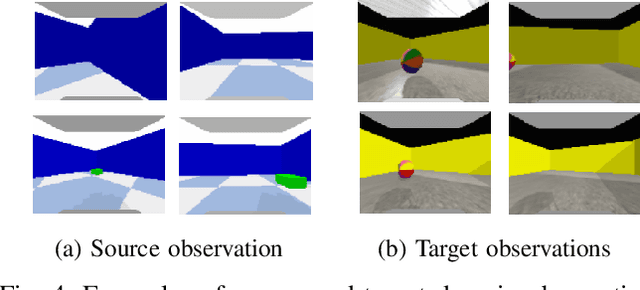
Despite recent progress in Reinforcement Learning for robotics applications, many tasks remain prohibitively difficult to solve because of the expensive interaction cost. Transfer learning helps reduce the training time in the target domain by transferring knowledge learned in a source domain. Sim2Real transfer helps transfer knowledge from a simulated robotic domain to a physical target domain. Knowledge transfer reduces the time required to train a task in the physical world, where the cost of interactions is high. However, most existing approaches assume exact correspondence in the task structure and the physical properties of the two domains. This work proposes a framework for Few-Shot Policy Transfer between two domains through Observation Mapping and Behavior Cloning. We use Generative Adversarial Networks (GANs) along with a cycle-consistency loss to map the observations between the source and target domains and later use this learned mapping to clone the successful source task behavior policy to the target domain. We observe successful behavior policy transfer with limited target task interactions and in cases where the source and target task are semantically dissimilar.
A Simple Way to Incorporate Novelty Detection in World Models
Oct 12, 2023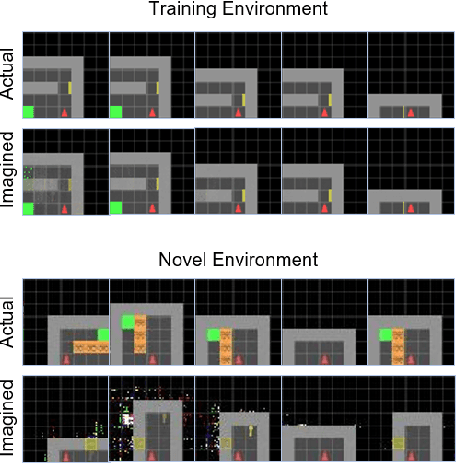

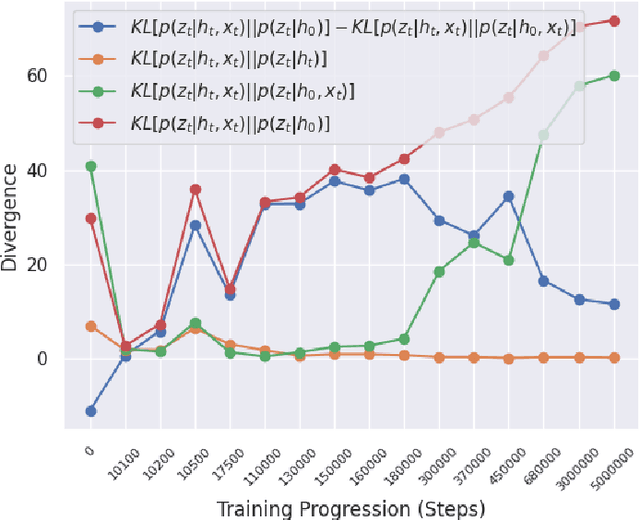
Reinforcement learning (RL) using world models has found significant recent successes. However, when a sudden change to world mechanics or properties occurs then agent performance and reliability can dramatically decline. We refer to the sudden change in visual properties or state transitions as {\em novelties}. Implementing novelty detection within generated world model frameworks is a crucial task for protecting the agent when deployed. In this paper, we propose straightforward bounding approaches to incorporate novelty detection into world model RL agents, by utilizing the misalignment of the world model's hallucinated states and the true observed states as an anomaly score. We first provide an ontology of novelty detection relevant to sequential decision making, then we provide effective approaches to detecting novelties in a distribution of transitions learned by an agent in a world model. Finally, we show the advantage of our work in a novel environment compared to traditional machine learning novelty detection methods as well as currently accepted RL focused novelty detection algorithms.
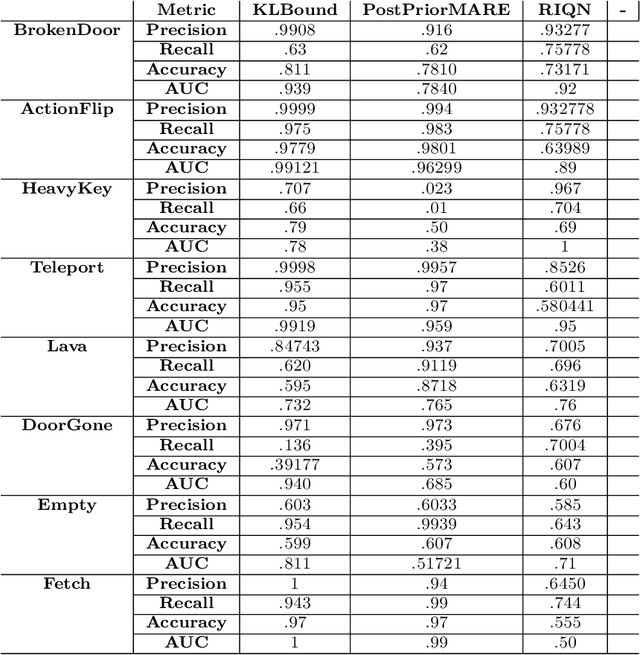
Automaton-Guided Curriculum Generation for Reinforcement Learning Agents
Apr 11, 2023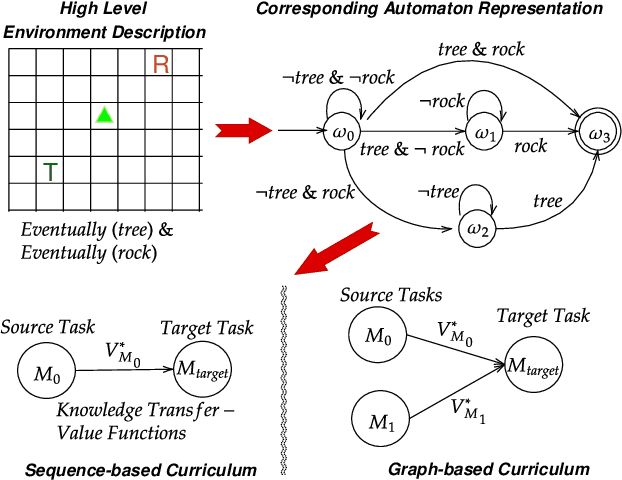
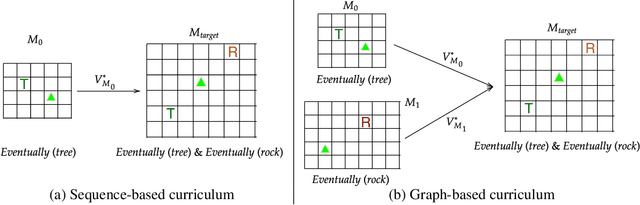

Despite advances in Reinforcement Learning, many sequential decision making tasks remain prohibitively expensive and impractical to learn. Recently, approaches that automatically generate reward functions from logical task specifications have been proposed to mitigate this issue; however, they scale poorly on long-horizon tasks (i.e., tasks where the agent needs to perform a series of correct actions to reach the goal state, considering future transitions while choosing an action). Employing a curriculum (a sequence of increasingly complex tasks) further improves the learning speed of the agent by sequencing intermediate tasks suited to the learning capacity of the agent. However, generating curricula from the logical specification still remains an unsolved problem. To this end, we propose AGCL, Automaton-guided Curriculum Learning, a novel method for automatically generating curricula for the target task in the form of Directed Acyclic Graphs (DAGs). AGCL encodes the specification in the form of a deterministic finite automaton (DFA), and then uses the DFA along with the Object-Oriented MDP (OOMDP) representation to generate a curriculum as a DAG, where the vertices correspond to tasks, and edges correspond to the direction of knowledge transfer. Experiments in gridworld and physics-based simulated robotics domains show that the curricula produced by AGCL achieve improved time-to-threshold performance on a complex sequential decision-making problem relative to state-of-the-art curriculum learning (e.g, teacher-student, self-play) and automaton-guided reinforcement learning baselines (e.g, Q-Learning for Reward Machines). Further, we demonstrate that AGCL performs well even in the presence of noise in the task's OOMDP description, and also when distractor objects are present that are not modeled in the logical specification of the tasks' objectives.
Neuro-Symbolic World Models for Adapting to Open World Novelty
Jan 16, 2023



Open-world novelty--a sudden change in the mechanics or properties of an environment--is a common occurrence in the real world. Novelty adaptation is an agent's ability to improve its policy performance post-novelty. Most reinforcement learning (RL) methods assume that the world is a closed, fixed process. Consequentially, RL policies adapt inefficiently to novelties. To address this, we introduce WorldCloner, an end-to-end trainable neuro-symbolic world model for rapid novelty adaptation. WorldCloner learns an efficient symbolic representation of the pre-novelty environment transitions, and uses this transition model to detect novelty and efficiently adapt to novelty in a single-shot fashion. Additionally, WorldCloner augments the policy learning process using imagination-based adaptation, where the world model simulates transitions of the post-novelty environment to help the policy adapt. By blending ''imagined'' transitions with interactions in the post-novelty environment, performance can be recovered with fewer total environment interactions. Using environments designed for studying novelty in sequential decision-making problems, we show that the symbolic world model helps its neural policy adapt more efficiently than model-based and model-based neural-only reinforcement learning methods.