 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Norms and References Collide: Evaluating LLMs on Normative Reasoning
Feb 03, 2026Embodied agents, such as robots, will need to interact in situated environments where successful communication often depends on reasoning over social norms: shared expectations that constrain what actions are appropriate in context. A key capability in such settings is norm-based reference resolution (NBRR), where interpreting referential expressions requires inferring implicit normative expectations grounded in physical and social context. Yet it remains unclear whether Large Language Models (LLMs) can support this kind of reasoning. In this work, we introduce SNIC (Situated Norms in Context), a human-validated diagnostic testbed designed to probe how well state-of-the-art LLMs can extract and utilize normative principles relevant to NBRR. SNIC emphasizes physically grounded norms that arise in everyday tasks such as cleaning, tidying, and serving. Across a range of controlled evaluations, we find that even the strongest LLMs struggle to consistently identify and apply social norms, particularly when norms are implicit, underspecified, or in conflict. These findings reveal a blind spot in current LLMs and highlight a key challenge for deploying language-based systems in socially situated, embodied settings.
IntelliProof: An Argumentation Network-based Conversational Helper for Organized Reflection
Nov 06, 2025We present IntelliProof, an interactive system for analyzing argumentative essays through LLMs. IntelliProof structures an essay as an argumentation graph, where claims are represented as nodes, supporting evidence is attached as node properties, and edges encode supporting or attacking relations. Unlike existing automated essay scoring systems, IntelliProof emphasizes the user experience: each relation is initially classified and scored by an LLM, then visualized for enhanced understanding. The system provides justifications for classifications and produces quantitative measures for essay coherence. It enables rapid exploration of argumentative quality while retaining human oversight. In addition, IntelliProof provides a set of tools for a better understanding of an argumentative essay and its corresponding graph in natural language, bridging the gap between the structural semantics of argumentative essays and the user's understanding of a given text. A live demo and the system are available here to try: \textbf{https://intelliproof.vercel.app}
Tools in the Loop: Quantifying Uncertainty of LLM Question Answering Systems That Use Tools
May 22, 2025Modern Large Language Models (LLMs) often require external tools, such as machine learning classifiers or knowledge retrieval systems, to provide accurate answers in domains where their pre-trained knowledge is insufficient. This integration of LLMs with external tools expands their utility but also introduces a critical challenge: determining the trustworthiness of responses generated by the combined system. In high-stakes applications, such as medical decision-making, it is essential to assess the uncertainty of both the LLM's generated text and the tool's output to ensure the reliability of the final response. However, existing uncertainty quantification methods do not account for the tool-calling scenario, where both the LLM and external tool contribute to the overall system's uncertainty. In this work, we present a novel framework for modeling tool-calling LLMs that quantifies uncertainty by jointly considering the predictive uncertainty of the LLM and the external tool. We extend previous methods for uncertainty quantification over token sequences to this setting and propose efficient approximations that make uncertainty computation practical for real-world applications. We evaluate our framework on two new synthetic QA datasets, derived from well-known machine learning datasets, which require tool-calling for accurate answers. Additionally, we apply our method to retrieval-augmented generation (RAG) systems and conduct a proof-of-concept experiment demonstrating the effectiveness of our uncertainty metrics in scenarios where external information retrieval is needed. Our results show that the framework is effective in enhancing trust in LLM-based systems, especially in cases where the LLM's internal knowledge is insufficient and external tools are required.
Analogical Reasoning Within a Conceptual Hyperspace
Nov 13, 2024We propose an approach to analogical inference that marries the neuro-symbolic computational power of complex-sampled hyperdimensional computing (HDC) with Conceptual Spaces Theory (CST), a promising theory of semantic meaning. CST sketches, at an abstract level, approaches to analogical inference that go beyond the standard predicate-based structure mapping theories. But it does not describe how such an approach can be operationalized. We propose a concrete HDC-based architecture that computes several types of analogy classified by CST. We present preliminary proof-of-concept experimental results within a toy domain and describe how it can perform category-based and property-based analogical reasoning.
Large Language Models Know What To Say But Not When To Speak
Oct 21, 2024Turn-taking is a fundamental mechanism in human communication that ensures smooth and coherent verbal interactions. Recent advances in Large Language Models (LLMs) have motivated their use in improving the turn-taking capabilities of Spoken Dialogue Systems (SDS), such as their ability to respond at appropriate times. However, existing models often struggle to predict opportunities for speaking -- called Transition Relevance Places (TRPs) -- in natural, unscripted conversations, focusing only on turn-final TRPs and not within-turn TRPs. To address these limitations, we introduce a novel dataset of participant-labeled within-turn TRPs and use it to evaluate the performance of state-of-the-art LLMs in predicting opportunities for speaking. Our experiments reveal the current limitations of LLMs in modeling unscripted spoken interactions, highlighting areas for improvement and paving the way for more naturalistic dialogue systems.
"Let's Argue Both Sides": Argument Generation Can Force Small Models to Utilize Previously Inaccessible Reasoning Capabilities
Oct 16, 2024

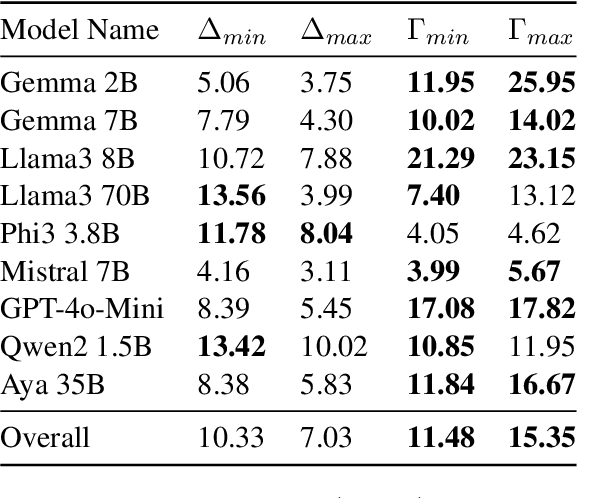
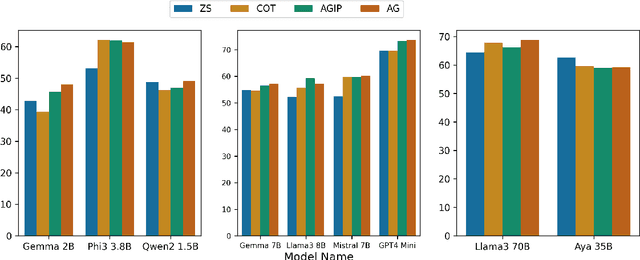
Large Language Models (LLMs), despite achieving state-of-the-art results in a number of evaluation tasks, struggle to maintain their performance when logical reasoning is strictly required to correctly infer a prediction. In this work, we propose Argument Generation as a method of forcing models to utilize their reasoning capabilities when other approaches such as chain-of-thought reasoning prove insufficient. Our method involves the generation of arguments for each possible inference result, and asking the end model to rank the generated arguments. We show that Argument Generation can serve as an appropriate substitute for zero-shot prompting techniques without the requirement to add layers of complexity. Furthermore, we argue that knowledge-probing techniques such as chain-of-thought reasoning and Argument Generation are only useful when further reasoning is required to infer a prediction, making them auxiliary to more common zero-shot approaches. Finally, we demonstrate that our approach forces larger gains in smaller language models, showcasing a complex relationship between model size and prompting methods in foundation models.
LgTS: Dynamic Task Sampling using LLM-generated sub-goals for Reinforcement Learning Agents
Oct 14, 2023



Recent advancements in reasoning abilities of Large Language Models (LLM) has promoted their usage in problems that require high-level planning for robots and artificial agents. However, current techniques that utilize LLMs for such planning tasks make certain key assumptions such as, access to datasets that permit finetuning, meticulously engineered prompts that only provide relevant and essential information to the LLM, and most importantly, a deterministic approach to allow execution of the LLM responses either in the form of existing policies or plan operators. In this work, we propose LgTS (LLM-guided Teacher-Student learning), a novel approach that explores the planning abilities of LLMs to provide a graphical representation of the sub-goals to a reinforcement learning (RL) agent that does not have access to the transition dynamics of the environment. The RL agent uses Teacher-Student learning algorithm to learn a set of successful policies for reaching the goal state from the start state while simultaneously minimizing the number of environmental interactions. Unlike previous methods that utilize LLMs, our approach does not assume access to a propreitary or a fine-tuned LLM, nor does it require pre-trained policies that achieve the sub-goals proposed by the LLM. Through experiments on a gridworld based DoorKey domain and a search-and-rescue inspired domain, we show that generating a graphical structure of sub-goals helps in learning policies for the LLM proposed sub-goals and the Teacher-Student learning algorithm minimizes the number of environment interactions when the transition dynamics are unknown.
RAPid-Learn: A Framework for Learning to Recover for Handling Novelties in Open-World Environments
Jun 24, 2022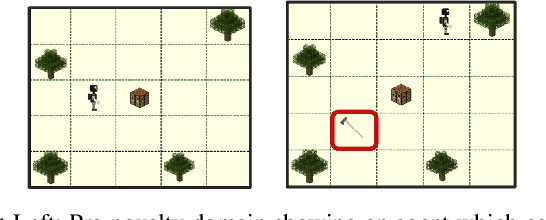
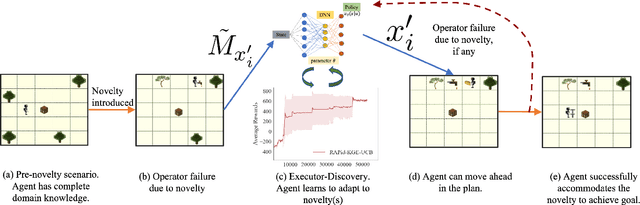
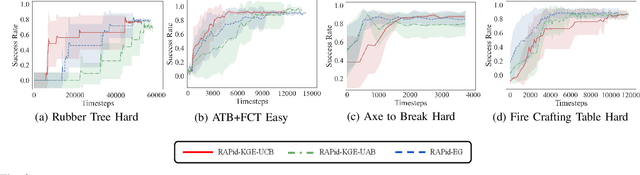

We propose RAPid-Learn: Learning to Recover and Plan Again, a hybrid planning and learning method, to tackle the problem of adapting to sudden and unexpected changes in an agent's environment (i.e., novelties). RAPid-Learn is designed to formulate and solve modifications to a task's Markov Decision Process (MDPs) on-the-fly and is capable of exploiting domain knowledge to learn any new dynamics caused by the environmental changes. It is capable of exploiting the domain knowledge to learn action executors which can be further used to resolve execution impasses, leading to a successful plan execution. This novelty information is reflected in its updated domain model. We demonstrate its efficacy by introducing a wide variety of novelties in a gridworld environment inspired by Minecraft, and compare our algorithm with transfer learning baselines from the literature. Our method is (1) effective even in the presence of multiple novelties, (2) more sample efficient than transfer learning RL baselines, and (3) robust to incomplete model information, as opposed to pure symbolic planning approaches.
From Unstructured Text to Causal Knowledge Graphs: A Transformer-Based Approach
Feb 23, 2022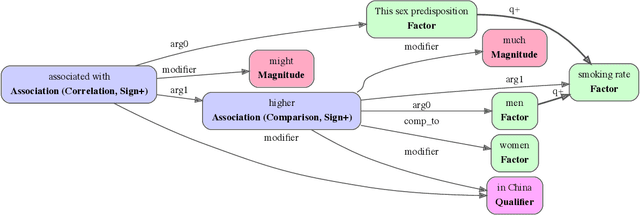
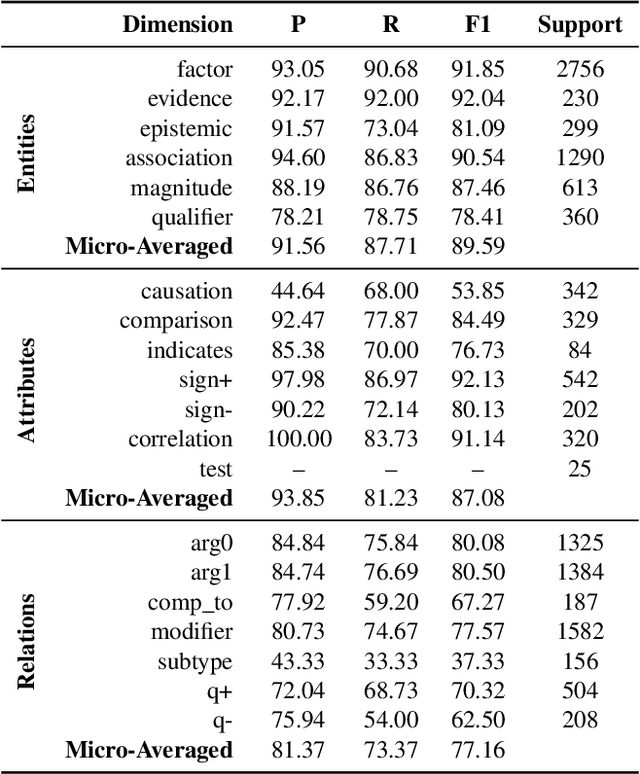
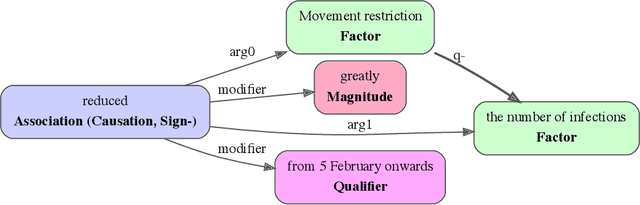
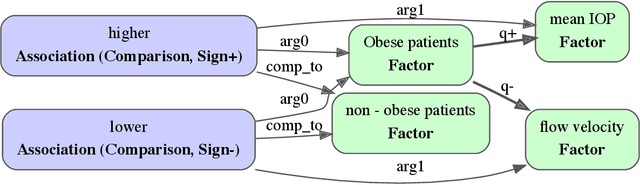
Qualitative causal relationships compactly express the direction, dependency, temporal constraints, and monotonicity constraints of discrete or continuous interactions in the world. In everyday or academic language, we may express interactions between quantities (e.g., sleep decreases stress), between discrete events or entities (e.g., a protein inhibits another protein's transcription), or between intentional or functional factors (e.g., hospital patients pray to relieve their pain). Extracting and representing these diverse causal relations are critical for cognitive systems that operate in domains spanning from scientific discovery to social science. This paper presents a transformer-based NLP architecture that jointly extracts knowledge graphs including (1) variables or factors described in language, (2) qualitative causal relationships over these variables, (3) qualifiers and magnitudes that constrain these causal relationships, and (4) word senses to localize each extracted node within a large ontology. We do not claim that our transformer-based architecture is itself a cognitive system; however, we provide evidence of its accurate knowledge graph extraction in real-world domains and the practicality of its resulting knowledge graphs for cognitive systems that perform graph-based reasoning. We demonstrate this approach and include promising results in two use cases, processing textual inputs from academic publications, news articles, and social media.
SPOTTER: Extending Symbolic Planning Operators through Targeted Reinforcement Learning
Dec 24, 2020



Symbolic planning models allow decision-making agents to sequence actions in arbitrary ways to achieve a variety of goals in dynamic domains. However, they are typically handcrafted and tend to require precise formulations that are not robust to human error. Reinforcement learning (RL) approaches do not require such models, and instead learn domain dynamics by exploring the environment and collecting rewards. However, RL approaches tend to require millions of episodes of experience and often learn policies that are not easily transferable to other tasks. In this paper, we address one aspect of the open problem of integrating these approaches: how can decision-making agents resolve discrepancies in their symbolic planning models while attempting to accomplish goals? We propose an integrated framework named SPOTTER that uses RL to augment and support ("spot") a planning agent by discovering new operators needed by the agent to accomplish goals that are initially unreachable for the agent. SPOTTER outperforms pure-RL approaches while also discovering transferable symbolic knowledge and does not require supervision, successful plan traces or any a priori knowledge about the missing planning operator.