 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPid-Learn: A Framework for Learning to Recover for Handling Novelties in Open-World Environments
Paper and Code
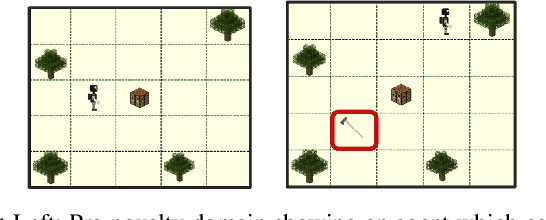
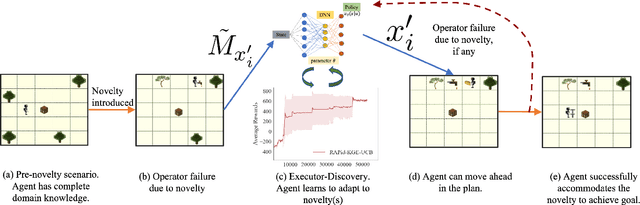
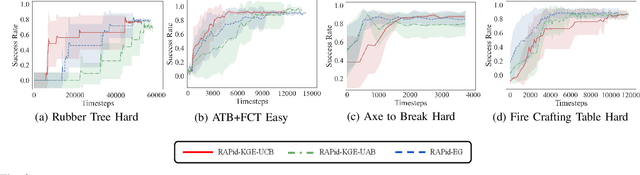

We propose RAPid-Learn: Learning to Recover and Plan Again, a hybrid planning and learning method, to tackle the problem of adapting to sudden and unexpected changes in an agent's environment (i.e., novelties). RAPid-Learn is designed to formulate and solve modifications to a task's Markov Decision Process (MDPs) on-the-fly and is capable of exploiting domain knowledge to learn any new dynamics caused by the environmental changes. It is capable of exploiting the domain knowledge to learn action executors which can be further used to resolve execution impasses, leading to a successful plan execution. This novelty information is reflected in its updated domain model. We demonstrate its efficacy by introducing a wide variety of novelties in a gridworld environment inspired by Minecraft, and compare our algorithm with transfer learning baselines from the literature. Our method is (1) effective even in the presence of multiple novelties, (2) more sample efficient than transfer learning RL baselines, and (3) robust to incomplete model information, as opposed to pure symbolic planning approaches.