 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASSANDRA: Programmatic and Probabilistic Learning and Inference for Stochastic World Modeling
Jan 26, 2026Building world models is essential for planning in real-world domains such as businesses. Since such domains have rich semantics, we can leverage world knowledge to effectively model complex action effects and causal relationships from limited data. In this work, we propose CASSANDRA, a neurosymbolic world modeling approach that leverages an LLM as a knowledge prior to construct lightweight transition models for planning. CASSANDRA integrates two components: (1) LLM-synthesized code to model deterministic features, and (2) LLM-guided structure learning of a probabilistic graphical model to capture causal relationships among stochastic variables. We evaluate CASSANDRA in (i) a small-scale coffee-shop simulator and (ii) a complex theme park business simulator, where we demonstrate significant improvements in transition prediction and planning over baselines.
Tools in the Loop: Quantifying Uncertainty of LLM Question Answering Systems That Use Tools
May 22, 2025Modern Large Language Models (LLMs) often require external tools, such as machine learning classifiers or knowledge retrieval systems, to provide accurate answers in domains where their pre-trained knowledge is insufficient. This integration of LLMs with external tools expands their utility but also introduces a critical challenge: determining the trustworthiness of responses generated by the combined system. In high-stakes applications, such as medical decision-making, it is essential to assess the uncertainty of both the LLM's generated text and the tool's output to ensure the reliability of the final response. However, existing uncertainty quantification methods do not account for the tool-calling scenario, where both the LLM and external tool contribute to the overall system's uncertainty. In this work, we present a novel framework for modeling tool-calling LLMs that quantifies uncertainty by jointly considering the predictive uncertainty of the LLM and the external tool. We extend previous methods for uncertainty quantification over token sequences to this setting and propose efficient approximations that make uncertainty computation practical for real-world applications. We evaluate our framework on two new synthetic QA datasets, derived from well-known machine learning datasets, which require tool-calling for accurate answers. Additionally, we apply our method to retrieval-augmented generation (RAG) systems and conduct a proof-of-concept experiment demonstrating the effectiveness of our uncertainty metrics in scenarios where external information retrieval is needed. Our results show that the framework is effective in enhancing trust in LLM-based systems, especially in cases where the LLM's internal knowledge is insufficient and external tools are required.
Graph Pruning for Enumeration of Minimal Unsatisfiable Subsets
Feb 19, 2024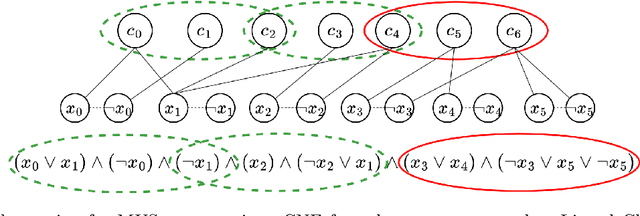
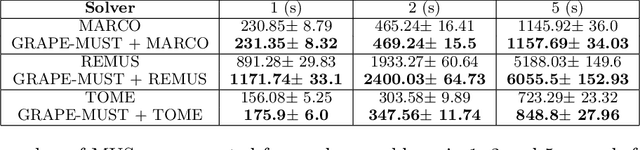
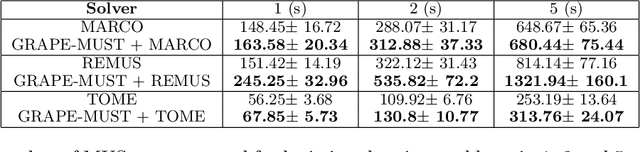
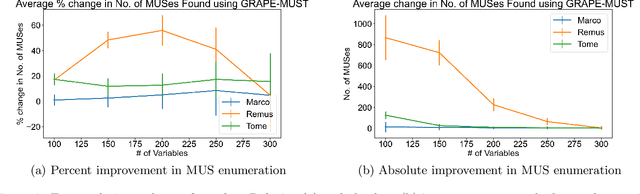
Finding Minimal Unsatisfiable Subsets (MUSes) of binary constraints is a common problem in infeasibility analysis of over-constrained systems. However, because of the exponential search space of the problem, enumerating MUSes is extremely time-consuming in real applications. In this work, we propose to prune formulas using a learned model to speed up MUS enumeration. We represent formulas as graphs and then develop a graph-based learning model to predict which part of the formula should be pruned. Importantly, our algorithm does not require data labeling by only checking the satisfiability of pruned formulas. It does not even require training data from the target application because it extrapolates to data with different distributions. In our experiments we combine our algorithm with existing MUS enumerators and validate its effectiveness in multiple benchmarks including a set of real-world problems outside our training distribution. The experiment results show that our method significantly accelerates MUS enumeration on average on these benchmark problems.
NovelGym: A Flexible Ecosystem for Hybrid Planning and Learning Agents Designed for Open Worlds
Jan 07, 2024



As AI agents leave the lab and venture into the real world as autonomous vehicles, delivery robots, and cooking robots, it is increasingly necessary to design and comprehensively evaluate algorithms that tackle the ``open-world''. To this end, we introduce NovelGym, a flexible and adaptable ecosystem designed to simulate gridworld environments, serving as a robust platform for benchmarking reinforcement learning (RL) and hybrid planning and learning agents in open-world contexts. The modular architecture of NovelGym facilitates rapid creation and modification of task environments, including multi-agent scenarios, with multiple environment transformations, thus providing a dynamic testbed for researchers to develop open-world AI agents.
NovelCraft: A Dataset for Novelty Detection and Discovery in Open Worlds
Jun 23, 2022
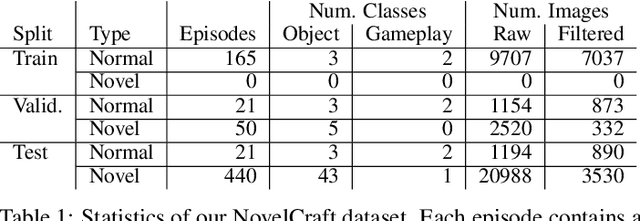
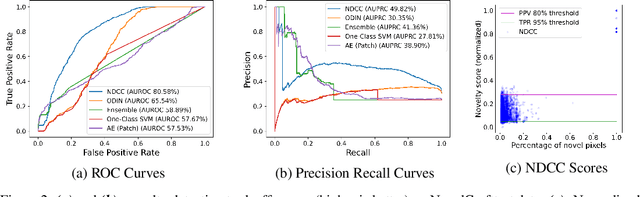
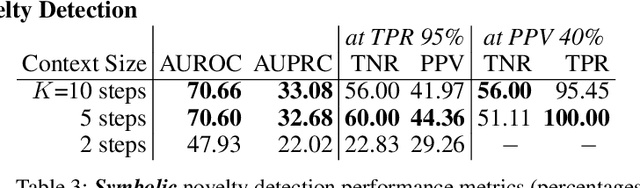
In order for artificial agents to perform useful tasks in changing environments, they must be able to both detect and adapt to novelty. However, visual novelty detection research often only evaluates on repurposed datasets such as CIFAR-10 originally intended for object classification. This practice restricts novelties to well-framed images of distinct object types. We suggest that new benchmarks are needed to represent the challenges of navigating an open world. Our new NovelCraft dataset contains multi-modal episodic data of the images and symbolic world-states seen by an agent completing a pogo-stick assembly task within a video game world. In some episodes, we insert novel objects that can impact gameplay. Novelty can vary in size, position, and occlusion within complex scenes. We benchmark state-of-the-art novelty detection and generalized category discovery models with a focus on comprehensive evaluation. Results suggest an opportunity for future research: models aware of task-specific costs of different types of mistakes could more effectively detect and adapt to novelty in open worlds.
Integrating Planning, Execution and Monitoring in the presence of Open World Novelties: Case Study of an Open World Monopoly Solver
Aug 09, 2021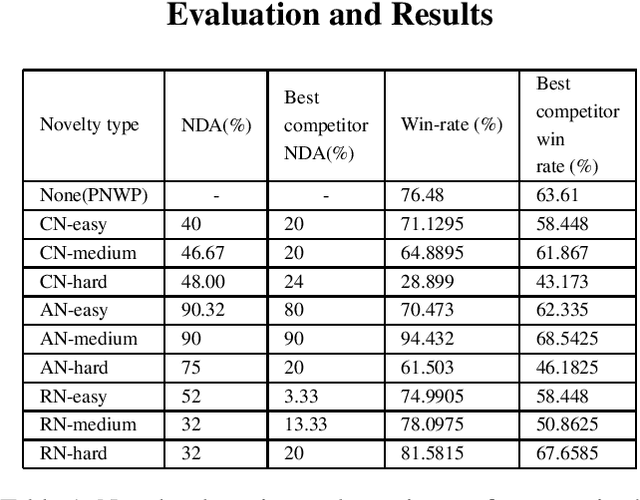
The game of monopoly is an adversarial multi-agent domain where there is no fixed goal other than to be the last player solvent, There are useful subgoals like monopolizing sets of properties, and developing them. There is also a lot of randomness from dice rolls, card-draws, and adversaries' strategies. This unpredictability is made worse when unknown novelties are added during gameplay. Given these challenges, Monopoly was one of the test beds chosen for the DARPA-SAILON program which aims to create agents that can detect and accommodate novelties. To handle the game complexities, we developed an agent that eschews complete plans, and adapts it's policy online as the game evolves. In the most recent independent evaluation in the SAILON program, our agent was the best performing agent on most measures. We herein present our approach and results.
Forecasting COVID-19 Counts At A Single Hospital: A Hierarchical Bayesian Approach
Apr 14, 2021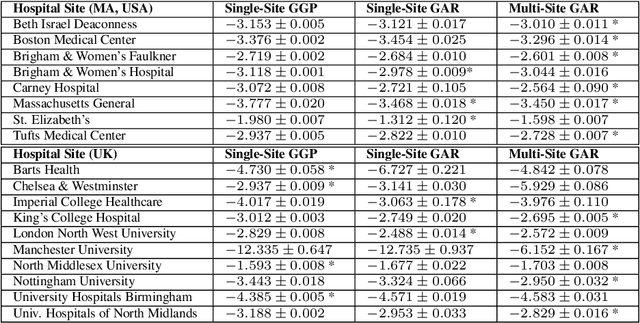
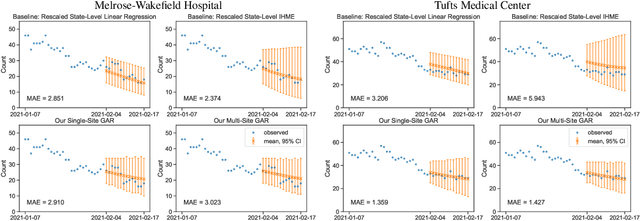
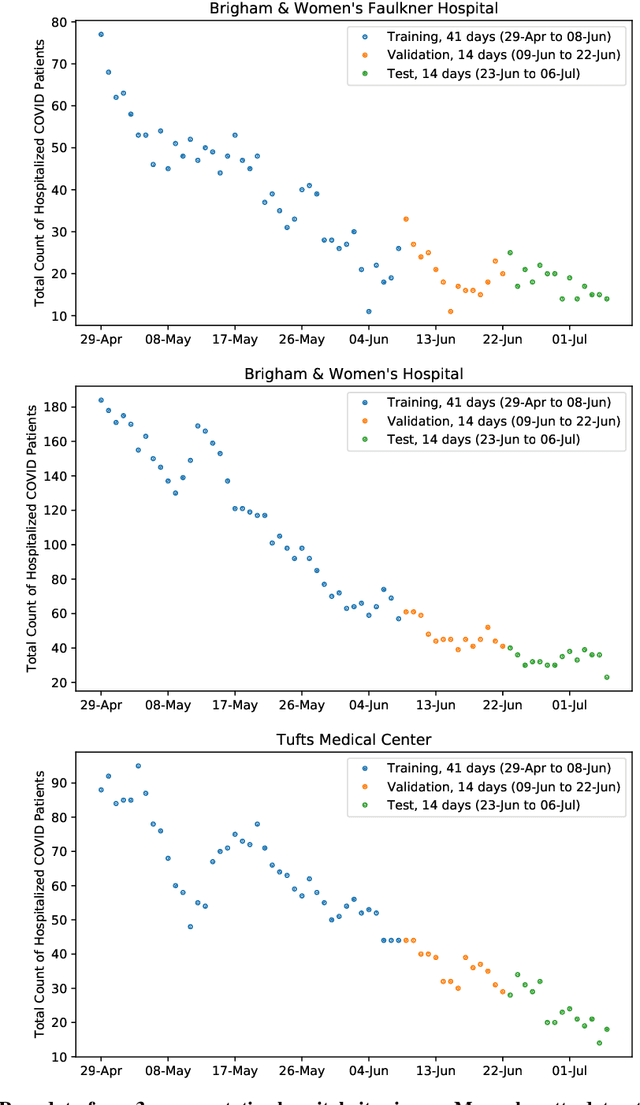
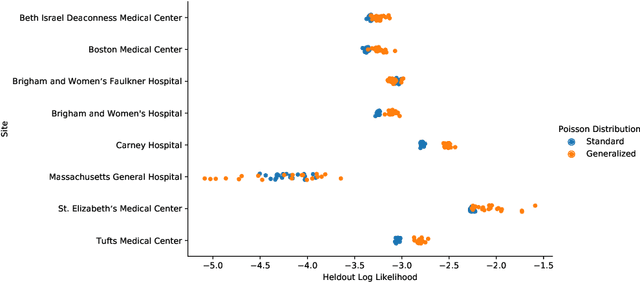
We consider the problem of forecasting the daily number of hospitalized COVID-19 patients at a single hospital site, in order to help administrators with logistics and planning. We develop several candidate hierarchical Bayesian models which directly capture the count nature of data via a generalized Poisson likelihood, model time-series dependencies via autoregressive and Gaussian process latent processes, and share statistical strength across related sites. We demonstrate our approach on public datasets for 8 hospitals in Massachusetts, U.S.A. and 10 hospitals in the United Kingdom. Further prospective evaluation compares our approach favorably to baselines currently used by stakeholders at 3 related hospitals to forecast 2-week-ahead demand by rescaling state-level forecasts.