 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASSANDRA: Programmatic and Probabilistic Learning and Inference for Stochastic World Modeling
Jan 26, 2026Building world models is essential for planning in real-world domains such as businesses. Since such domains have rich semantics, we can leverage world knowledge to effectively model complex action effects and causal relationships from limited data. In this work, we propose CASSANDRA, a neurosymbolic world modeling approach that leverages an LLM as a knowledge prior to construct lightweight transition models for planning. CASSANDRA integrates two components: (1) LLM-synthesized code to model deterministic features, and (2) LLM-guided structure learning of a probabilistic graphical model to capture causal relationships among stochastic variables. We evaluate CASSANDRA in (i) a small-scale coffee-shop simulator and (ii) a complex theme park business simulator, where we demonstrate significant improvements in transition prediction and planning over baselines.
Automated Interactive Domain-Specific Conversational Agents that Understand Human Dialogs
Mar 17, 2023Achieving human-like communication with machines remains a classic, challenging topic in the field of Knowledge Representation and Reasoning and Natural Language Processing. These Large Language Models (LLMs) rely on pattern-matching rather than a true understanding of the semantic meaning of a sentence. As a result, they may generate incorrect responses. To generate an assuredly correct response, one has to "understand" the semantics of a sentence. To achieve this "understanding", logic-based (commonsense) reasoning methods such as Answer Set Programming (ASP) are arguably needed. In this paper, we describe the AutoConcierge system that leverages LLMs and ASP to develop a conversational agent that can truly "understand" human dialogs in restricted domains. AutoConcierge is focused on a specific domain-advising users about restaurants in their local area based on their preferences. AutoConcierge will interactively understand a user's utterances, identify the missing information in them, and request the user via a natural language sentence to provide it. Once AutoConcierge has determined that all the information has been received, it computes a restaurant recommendation based on the user-preferences it has acquired from the human user. AutoConcierge is based on our STAR framework developed earlier, which uses GPT-3 to convert human dialogs into predicates that capture the deep structure of the dialog's sentence. These predicates are then input into the goal-directed s(CASP) ASP system for performing commonsense reasoning. To the best of our knowledge, AutoConcierge is the first automated conversational agent that can realistically converse like a human and provide help to humans based on truly understanding human utterances.
Reliable Natural Language Understanding with Large Language Models and Answer Set Programming
Feb 09, 2023Humans understand language by extracting information (meaning) from sentences, combining it with existing commonsense knowledge, and then performing reasoning to draw conclusions. While large language models (LLMs) such as GPT-3 and ChatGPT are able to leverage patterns in the text to solve a variety of NLP tasks, they fall short in problems that require reasoning. They also cannot reliably explain the answers generated for a given question. In order to emulate humans better, we propose STAR, a framework that combines LLMs with Answer Set Programming (ASP). We show how LLMs can be used to effectively extract knowledge -- represented as predicates -- from language. Goal-directed ASP is then employed to reliably reason over this knowledge. We apply the STAR framework to three different NLU tasks requiring reasoning: qualitative reasoning, mathematical reasoning, and goal-directed conversation. Our experiments reveal that STAR is able to bridge the gap of reasoning in NLU tasks, leading to significant performance improvements, especially for smaller LLMs, i.e., LLMs with a smaller number of parameters. NLU applications developed using the STAR framework are also explainable: along with the predicates generated, a justification in the form of a proof tree can be produced for a given output.
Transfer Reinforcement Learning for Differing Action Spaces via Q-Network Representations
Feb 15, 2022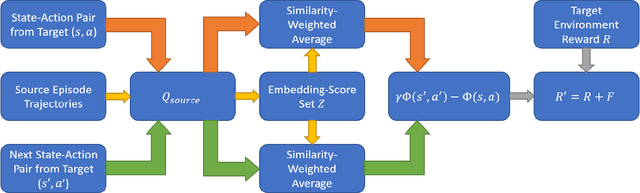

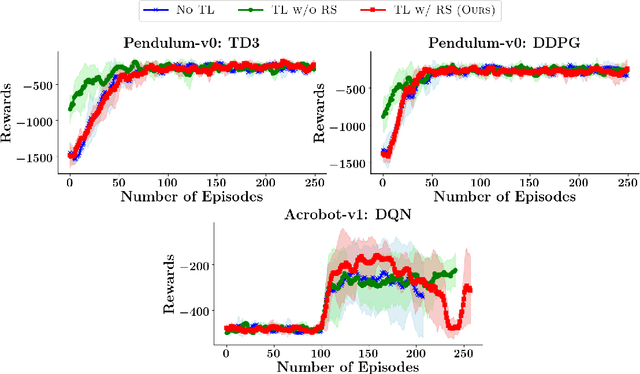
Transfer learning approaches in reinforcement learning aim to assist agents in learning their target domains by leveraging the knowledge learned from other agents that have been trained on similar source domains. For example, recent research focus within this space has been placed on knowledge transfer between tasks that have different transition dynamics and reward functions; however, little focus has been placed on knowledge transfer between tasks that have different action spaces. In this paper, we approach the task of transfer learning between domains that differ in action spaces. We present a reward shaping method based on source embedding similarity that is applicable to domains with both discrete and continuous action spaces. The efficacy of our approach is evaluated on transfer to restricted action spaces in the Acrobot-v1 and Pendulum-v0 domains. A comparison with two baselines shows that our method does not outperform these baselines in these continuous action spaces but does show an improvement in these discrete action spaces. We conclude our analysis with future directions for this work.