 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Trustworthy AI by Addressing its 16+2 Desiderata with Goal-Directed Commonsense Reasoning
Jun 15, 2025Current advances in AI and its applicability have highlighted the need to ensure its trustworthiness for legal, ethical, and even commercial reasons. Sub-symbolic machine learning algorithms, such as the LLMs, simulate reasoning but hallucinate and their decisions cannot be explained or audited (crucial aspects for trustworthiness). On the other hand, rule-based reasoners, such as Cyc, are able to provide the chain of reasoning steps but are complex and use a large number of reasoners. We propose a middle ground using s(CASP), a goal-directed constraint-based answer set programming reasoner that employs a small number of mechanisms to emulate reliable and explainable human-style commonsense reasoning. In this paper, we explain how s(CASP) supports the 16 desiderata for trustworthy AI introduced by Doug Lenat and Gary Marcus (2023), and two additional ones: inconsistency detection and the assumption of alternative worlds. To illustrate the feasibility and synergies of s(CASP), we present a range of diverse applications, including a conversational chatbot and a virtually embodied reasoner.
Reliable Collaborative Conversational Agent System Based on LLMs and Answer Set Programming
May 09, 2025As the Large-Language-Model-driven (LLM-driven) Artificial Intelligence (AI) bots became popular, people realized their strong potential in Task-Oriented Dialogue (TOD). However, bots relying wholly on LLMs are unreliable in their knowledge, and whether they can finally produce a correct result for the task is not guaranteed. The collaboration among these agents also remains a challenge, since the necessary information to convey is unclear, and the information transfer is by prompts -- unreliable, and malicious knowledge is easy to inject. With the help of logic programming tools such as Answer Set Programming (ASP), conversational agents can be built safely and reliably, and communication among the agents made more efficient and secure. We proposed an Administrator-Assistant Dual-Agent paradigm, where the two ASP-driven bots share the same knowledge base and complete their tasks independently, while the information can be passed by a Collaborative Rule Set (CRS). The knowledge and information conveyed are encapsulated and invisible to the users, ensuring the security of information transmission. We have constructed AutoManager, a dual-agent system for managing the drive-through window of a fast-food restaurant such as Taco Bell in the US. In AutoManager, the assistant bot takes the customer's order while the administrator bot manages the menu and food supply. We evaluated our AutoManager and compared it with the real-world Taco Bell Drive-Thru AI Order Taker, and the results show that our method is more reliable.
Reliable Conversational Agents under ASP Control that Understand Natural Language
Feb 13, 2025Efforts have been made to make machines converse like humans in the past few decades. The recent techniques of Large Language Models (LLMs) make it possible to have human-like conversations with machines, but LLM's flaws of lacking understanding and reliability are well documented. We believe that the best way to eliminate this problem is to use LLMs only as parsers to translate text to knowledge and vice versa and carry out the conversation by reasoning over this knowledge using the answer set programming. I have been developing a framework based on LLMs and ASP to realize reliable chatbots that "understand" human conversation. This framework has been used to develop task-specific chatbots as well as socialbots. My future research is focused on making these chatbots scalable and trainable.
* In Proceedings ICLP 2024, arXiv:2502.08453
A Reliable Common-Sense Reasoning Socialbot Built Using LLMs and Goal-Directed ASP
Jul 26, 2024The development of large language models (LLMs), such as GPT, has enabled the construction of several socialbots, like ChatGPT, that are receiving a lot of attention for their ability to simulate a human conversation. However, the conversation is not guided by a goal and is hard to control. In addition, because LLMs rely more on pattern recognition than deductive reasoning, they can give confusing answers and have difficulty integrating multiple topics into a cohesive response. These limitations often lead the LLM to deviate from the main topic to keep the conversation interesting. We propose AutoCompanion, a socialbot that uses an LLM model to translate natural language into predicates (and vice versa) and employs commonsense reasoning based on Answer Set Programming (ASP) to hold a social conversation with a human. In particular, we rely on s(CASP), a goal-directed implementation of ASP as the backend. This paper presents the framework design and how an LLM is used to parse user messages and generate a response from the s(CASP) engine output. To validate our proposal, we describe (real) conversations in which the chatbot's goal is to keep the user entertained by talking about movies and books, and s(CASP) ensures (i) correctness of answers, (ii) coherence (and precision) during the conversation, which it dynamically regulates to achieve its specific purpose, and (iii) no deviation from the main topic.
Automated Interactive Domain-Specific Conversational Agents that Understand Human Dialogs
Mar 17, 2023Achieving human-like communication with machines remains a classic, challenging topic in the field of Knowledge Representation and Reasoning and Natural Language Processing. These Large Language Models (LLMs) rely on pattern-matching rather than a true understanding of the semantic meaning of a sentence. As a result, they may generate incorrect responses. To generate an assuredly correct response, one has to "understand" the semantics of a sentence. To achieve this "understanding", logic-based (commonsense) reasoning methods such as Answer Set Programming (ASP) are arguably needed. In this paper, we describe the AutoConcierge system that leverages LLMs and ASP to develop a conversational agent that can truly "understand" human dialogs in restricted domains. AutoConcierge is focused on a specific domain-advising users about restaurants in their local area based on their preferences. AutoConcierge will interactively understand a user's utterances, identify the missing information in them, and request the user via a natural language sentence to provide it. Once AutoConcierge has determined that all the information has been received, it computes a restaurant recommendation based on the user-preferences it has acquired from the human user. AutoConcierge is based on our STAR framework developed earlier, which uses GPT-3 to convert human dialogs into predicates that capture the deep structure of the dialog's sentence. These predicates are then input into the goal-directed s(CASP) ASP system for performing commonsense reasoning. To the best of our knowledge, AutoConcierge is the first automated conversational agent that can realistically converse like a human and provide help to humans based on truly understanding human utterances.
Reliable Natural Language Understanding with Large Language Models and Answer Set Programming
Feb 09, 2023Humans understand language by extracting information (meaning) from sentences, combining it with existing commonsense knowledge, and then performing reasoning to draw conclusions. While large language models (LLMs) such as GPT-3 and ChatGPT are able to leverage patterns in the text to solve a variety of NLP tasks, they fall short in problems that require reasoning. They also cannot reliably explain the answers generated for a given question. In order to emulate humans better, we propose STAR, a framework that combines LLMs with Answer Set Programming (ASP). We show how LLMs can be used to effectively extract knowledge -- represented as predicates -- from language. Goal-directed ASP is then employed to reliably reason over this knowledge. We apply the STAR framework to three different NLU tasks requiring reasoning: qualitative reasoning, mathematical reasoning, and goal-directed conversation. Our experiments reveal that STAR is able to bridge the gap of reasoning in NLU tasks, leading to significant performance improvements, especially for smaller LLMs, i.e., LLMs with a smaller number of parameters. NLU applications developed using the STAR framework are also explainable: along with the predicates generated, a justification in the form of a proof tree can be produced for a given output.
Weakly-Supervised Visual-Retriever-Reader for Knowledge-based Question Answering
Sep 09, 2021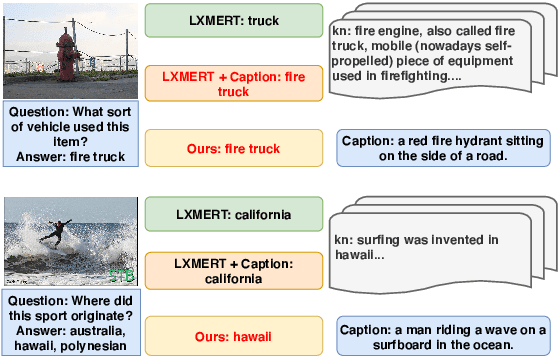
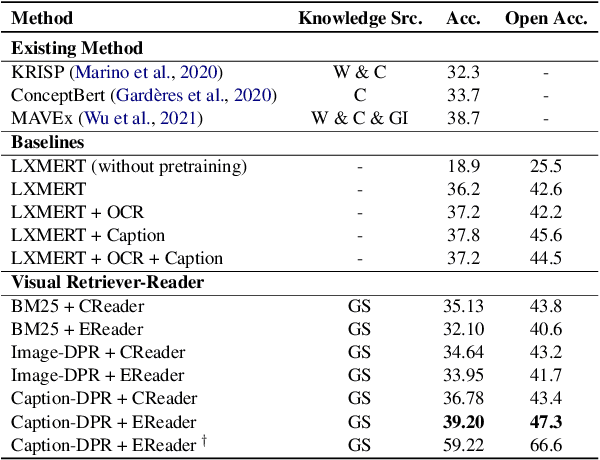


Knowledge-based visual question answering (VQA) requires answering questions with external knowledge in addition to the content of images. One dataset that is mostly used in evaluating knowledge-based VQA is OK-VQA, but it lacks a gold standard knowledge corpus for retrieval. Existing work leverage different knowledge bases (e.g., ConceptNet and Wikipedia) to obtain external knowledge. Because of varying knowledge bases, it is hard to fairly compare models' performance. To address this issue, we collect a natural language knowledge base that can be used for any VQA system. Moreover, we propose a Visual Retriever-Reader pipeline to approach knowledge-based VQA. The visual retriever aims to retrieve relevant knowledge, and the visual reader seeks to predict answers based on given knowledge. We introduce various ways to retrieve knowledge using text and images and two reader styles: classification and extraction. Both the retriever and reader are trained with weak supervision. Our experimental results show that a good retriever can significantly improve the reader's performance on the OK-VQA challenge. The code and corpus are provided in https://github.com/luomancs/retriever\_reader\_for\_okvqa.git
'Just because you are right, doesn't mean I am wrong': Overcoming a Bottleneck in the Development and Evaluation of Open-Ended Visual Question Answering Tasks
Mar 28, 2021

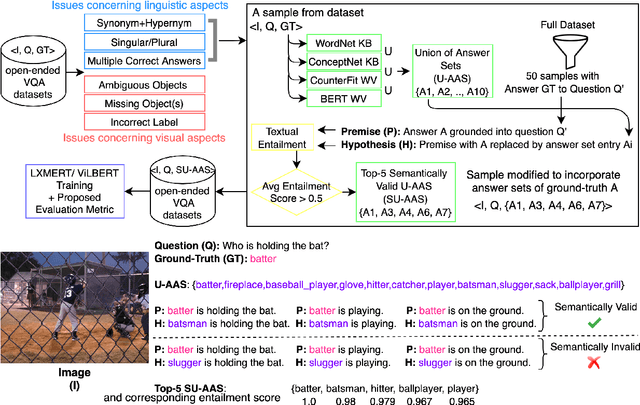

GQA (Hudson and Manning, 2019) is a dataset for real-world visual reasoning and compositional question answering. We found that many answers predicted by the best visionlanguage models on the GQA dataset do not match the ground-truth answer but still are semantically meaningful and correct in the given context. In fact, this is the case with most existing visual question answering (VQA) datasets where they assume only one ground-truth answer for each question. We propose Alternative Answer Sets (AAS) of ground-truth answers to address this limitation, which is created automatically using off-the-shelf NLP tools. We introduce a semantic metric based on AAS and modify top VQA solvers to support multiple plausible answers for a question. We implement this approach on the GQA dataset and show the performance improvements.