 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Trustworthy AI by Addressing its 16+2 Desiderata with Goal-Directed Commonsense Reasoning
Jun 15, 2025
Current advances in AI and its applicability have highlighted the need to ensure its trustworthiness for legal, ethical, and even commercial reasons. Sub-symbolic machine learning algorithms, such as the LLMs, simulate reasoning but hallucinate and their decisions cannot be explained or audited (crucial aspects for trustworthiness). On the other hand, rule-based reasoners, such as Cyc, are able to provide the chain of reasoning steps but are complex and use a large number of reasoners. We propose a middle ground using s(CASP), a goal-directed constraint-based answer set programming reasoner that employs a small number of mechanisms to emulate reliable and explainable human-style commonsense reasoning. In this paper, we explain how s(CASP) supports the 16 desiderata for trustworthy AI introduced by Doug Lenat and Gary Marcus (2023), and two additional ones: inconsistency detection and the assumption of alternative worlds. To illustrate the feasibility and synergies of s(CASP), we present a range of diverse applications, including a conversational chatbot and a virtually embodied reasoner.
A Reliable Common-Sense Reasoning Socialbot Built Using LLMs and Goal-Directed ASP
Jul 26, 2024The development of large language models (LLMs), such as GPT, has enabled the construction of several socialbots, like ChatGPT, that are receiving a lot of attention for their ability to simulate a human conversation. However, the conversation is not guided by a goal and is hard to control. In addition, because LLMs rely more on pattern recognition than deductive reasoning, they can give confusing answers and have difficulty integrating multiple topics into a cohesive response. These limitations often lead the LLM to deviate from the main topic to keep the conversation interesting. We propose AutoCompanion, a socialbot that uses an LLM model to translate natural language into predicates (and vice versa) and employs commonsense reasoning based on Answer Set Programming (ASP) to hold a social conversation with a human. In particular, we rely on s(CASP), a goal-directed implementation of ASP as the backend. This paper presents the framework design and how an LLM is used to parse user messages and generate a response from the s(CASP) engine output. To validate our proposal, we describe (real) conversations in which the chatbot's goal is to keep the user entertained by talking about movies and books, and s(CASP) ensures (i) correctness of answers, (ii) coherence (and precision) during the conversation, which it dynamically regulates to achieve its specific purpose, and (iii) no deviation from the main topic.
Superfast Selection for Decision Tree Algorithms
Jun 04, 2024



We present a novel and systematic method, called Superfast Selection, for selecting the "optimal split" for decision tree and feature selection algorithms over tabular data. The method speeds up split selection on a single feature by lowering the time complexity, from O(MN) (using the standard selection methods) to O(M), where M represents the number of input examples and N the number of unique values. Additionally, the need for pre-encoding, such as one-hot or integer encoding, for feature value heterogeneity is eliminated. To demonstrate the efficiency of Superfast Selection, we empower the CART algorithm by integrating Superfast Selection into it, creating what we call Ultrafast Decision Tree (UDT). This enhancement enables UDT to complete the training process with a time complexity O(KM$^2$) (K is the number of features). Additionally, the Training Only Once Tuning enables UDT to avoid the repetitive training process required to find the optimal hyper-parameter. Experiments show that the UDT can finish a single training on KDD99-10% dataset (494K examples with 41 features) within 1 second and tuning with 214.8 sets of hyper-parameters within 0.25 second on a laptop.
NeSyFOLD: A System for Generating Logic-based Explanations from Convolutional Neural Networks
Jan 30, 2023



We present a novel neurosymbolic system called NeSyFOLD that classifies images while providing a logic-based explanation of the classification. NeSyFOLD's training process is as follows: (i) We first pre-train a CNN on the input image dataset and extract activations of the last layer filters as binary values; (ii) Next, we use the FOLD-SE-M rule-based machine learning algorithm to generate a logic program that can classify an image -- represented as a vector of binary activations corresponding to each filter -- while producing a logical explanation. The rules generated by the FOLD-SE-M algorithm have filter numbers as predicates. We use a novel algorithm that we have devised for automatically mapping the CNN filters to semantic concepts in the images. This mapping is used to replace predicate names (filter numbers) in the rule-set with corresponding semantic concept labels. The resulting rule-set is highly interpretable, and can be intuitively understood by humans. We compare our NeSyFOLD system with the ERIC system that uses a decision-tree like algorithm to obtain the rules. Our system has the following advantages over ERIC: (i) NeSyFOLD generates smaller rule-sets without compromising on the accuracy and fidelity; (ii) NeSyFOLD generates the mapping of filter numbers to semantic labels automatically.
FOLD-SE: Scalable Explainable AI
Aug 16, 2022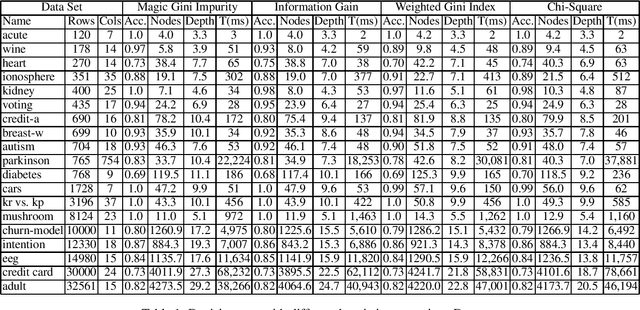
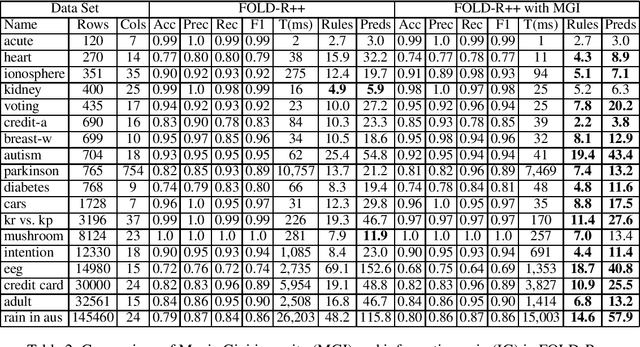

FOLD-R++ is a highly efficient and explainable rule-based machine learning algorithm for binary classification tasks. It generates a stratified normal logic program as an (explainable) trained model. We present an improvement over the FOLD-R++ algorithm, termed FOLD-SE, that provides scalable explainability (SE) while inheriting all the merits of FOLD-R++. Scalable explainability means that regardless of the size of the dataset, the number of learned rules and learned literals stay small and, hence, understandable by human beings, while maintaining good performance in classification. FOLD-SE is competitive in performance with state-of-the-art algorithms such as XGBoost and Multi-Layer Perceptrons (MLP). However, unlike XGBoost and MLP, the FOLD-SE algorithm generates a model with scalable explainability. The FOLD-SE algorithm outperforms FOLD-R++ and RIPPER algorithms in efficiency, performance, and explainability, especially for large datasets. The FOLD-RM algorithm is an extension of FOLD-R++ for multi-class classification tasks. An improved FOLD-RM algorithm built upon FOLD-SE is also presented.
FOLD-TR: A Scalable and Efficient Inductive Learning Algorithm for Learning To Rank
Jun 15, 2022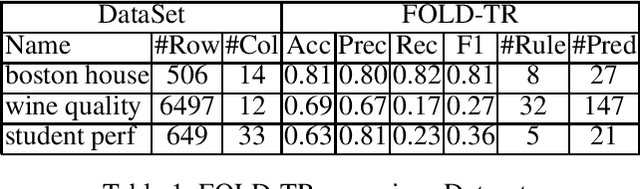
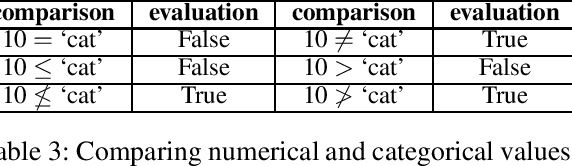
FOLD-R++ is a new inductive learning algorithm for binary classification tasks. It generates an (explainable) normal logic program for mixed type (numerical and categorical) data. We present a customized FOLD-R++ algorithm with the ranking framework, called FOLD-TR, that aims to rank new items following the ranking pattern in the training data. Like FOLD-R++, the FOLD-TR algorithm is able to handle mixed-type data directly and provide native justification to explain the comparison between a pair of items.
FOLD-RM: A Scalable and Efficient Inductive Learning Algorithm for Multi-Category Classification of Mixed Data
Feb 25, 2022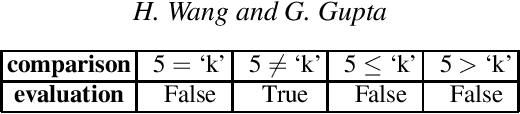

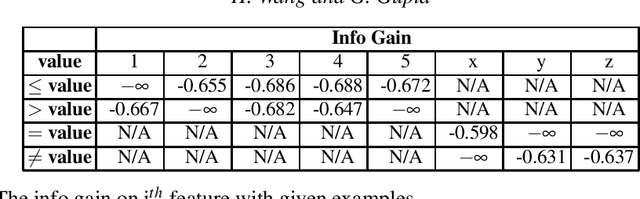
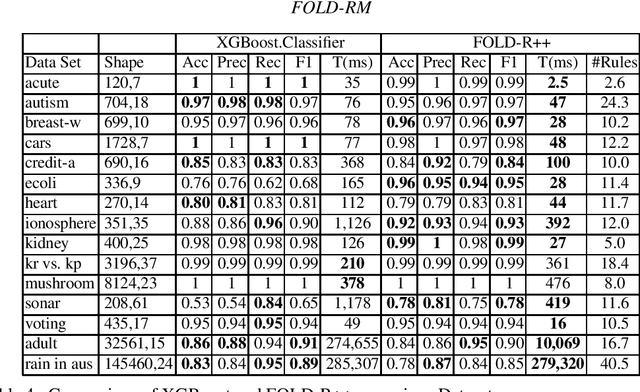
FOLD-RM is an automated inductive learning algorithm for learning default rules for mixed (numerical and categorical) data. It generates an (explainable) answer set programming (ASP) rule set for multi-category classification tasks while maintaining efficiency and scalability. The FOLD-RM algorithm is competitive in performance with the widely-used XGBoost algorithm, however, unlike XGBoost, the FOLD-RM algorithm produces an explainable model. FOLD-RM outperforms XGBoost on some datasets, particularly large ones. FOLD-RM also provides human-friendly explanations for predictions.
AUTO-DISCERN: Autonomous Driving Using Common Sense Reasoning
Oct 17, 2021



Driving an automobile involves the tasks of observing surroundings, then making a driving decision based on these observations (steer, brake, coast, etc.). In autonomous driving, all these tasks have to be automated. Autonomous driving technology thus far has relied primarily on machine learning techniques. We argue that appropriate technology should be used for the appropriate task. That is, while machine learning technology is good for observing and automatically understanding the surroundings of an automobile, driving decisions are better automated via commonsense reasoning rather than machine learning. In this paper, we discuss (i) how commonsense reasoning can be automated using answer set programming (ASP) and the goal-directed s(CASP) ASP system, and (ii) develop the AUTO-DISCERN system using this technology for automating decision-making in driving. The goal of our research, described in this paper, is to develop an autonomous driving system that works by simulating the mind of a human driver. Since driving decisions are based on human-style reasoning, they are explainable, their ethics can be ensured, and they will always be correct, provided the system modeling and system inputs are correct.
FOLD-R++: A Toolset for Automated Inductive Learning of Default Theories from Mixed Data
Oct 15, 2021

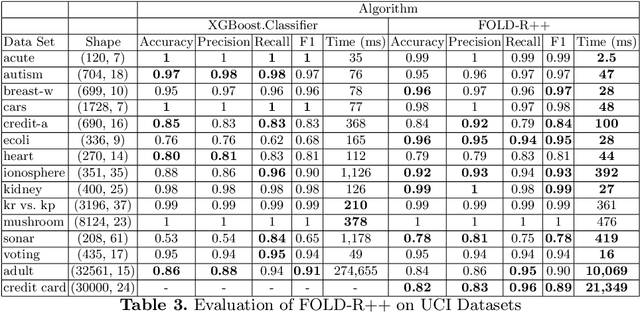
FOLD-R is an automated inductive learning algorithm for learning default rules with exceptions for mixed (numerical and categorical) data. It generates an (explainable) answer set programming (ASP) rule set for classification tasks. We present an improved FOLD-R algorithm, called FOLD-R++, that significantly increases the efficiency and scalability of FOLD-R. FOLD-R++ improves upon FOLD-R without compromising or losing information in the input training data during the encoding or feature selection phase. The FOLD-R++ algorithm is competitive in performance with the widely-used XGBoost algorithm, however, unlike XGBoost, the FOLD-R++ algorithm produces an explainable model. Next, we create a powerful tool-set by combining FOLD-R++ with s(CASP)-a goal-directed ASP execution engine-to make predictions on new data samples using the answer set program generated by FOLD-R++. The s(CASP) system also produces a justification for the prediction. Experiments presented in this paper show that our improved FOLD-R++ algorithm is a significant improvement over the original design and that the s(CASP) system can make predictions in an efficient manner as well.
CASPR: A Commonsense Reasoning-based Conversational Socialbot
Oct 11, 2021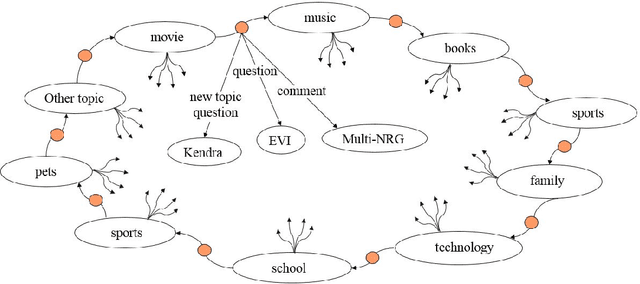

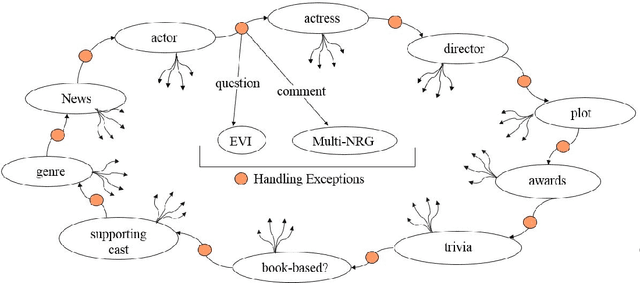
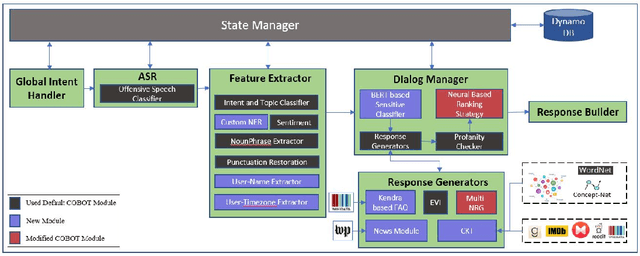
We report on the design and development of the CASPR system, a socialbot designed to compete in the Amazon Alexa Socialbot Challenge 4. CASPR's distinguishing characteristic is that it will use automated commonsense reasoning to truly "understand" dialogs, allowing it to converse like a human. Three main requirements of a socialbot are that it should be able to "understand" users' utterances, possess a strategy for holding a conversation, and be able to learn new knowledge. We developed techniques such as conversational knowledge template (CKT) to approximate commonsense reasoning needed to hold a conversation on specific topics. We present the philosophy behind CASPR's design as well as details of its implementation. We also report on CASPR's performance as well as discuss lessons learned.