 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWizard of Shopping: Target-Oriented E-commerce Dialogue Generation with Decision Tree Branching
Feb 03, 2025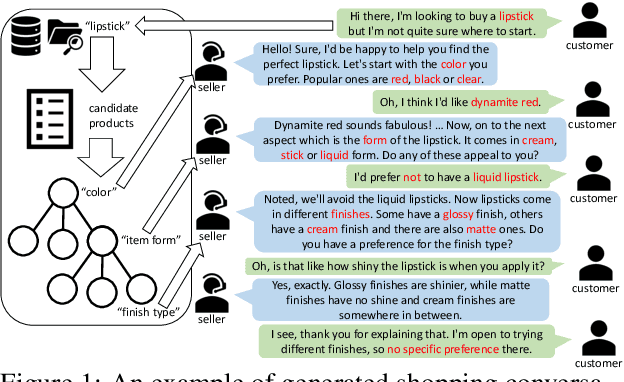

The goal of conversational product search (CPS) is to develop an intelligent, chat-based shopping assistant that can directly interact with customers to understand shopping intents, ask clarification questions, and find relevant products. However, training such assistants is hindered mainly due to the lack of reliable and large-scale datasets. Prior human-annotated CPS datasets are extremely small in size and lack integration with real-world product search systems. We propose a novel approach, TRACER, which leverages large language models (LLMs) to generate realistic and natural conversations for different shopping domains. TRACER's novelty lies in grounding the generation to dialogue plans, which are product search trajectories predicted from a decision tree model, that guarantees relevant product discovery in the shortest number of search conditions. We also release the first target-oriented CPS dataset Wizard of Shopping (WoS), containing highly natural and coherent conversations (3.6k) from three shopping domains. Finally, we demonstrate the quality and effectiveness of WoS via human evaluations and downstream tasks.
Multi-round, Chain-of-thought Post-editing for Unfaithful Summaries
Jan 20, 2025Recent large language models (LLMs) have demonstrated a remarkable ability to perform natural language understanding and generation tasks. In this work, we investigate the use of LLMs for evaluating faithfulness in news summarization, finding that it achieves a strong correlation with human judgments. We further investigate LLMs' capabilities as a faithfulness post-editor, experimenting with different chain-of-thought prompts for locating and correcting factual inconsistencies between a generated summary and the source news document and are able to achieve a higher editing success rate than was reported in prior work. We perform both automated and human evaluations of the post-edited summaries, finding that prompting LLMs using chain-of-thought reasoning about factual error types is an effective faithfulness post-editing strategy, performing comparably to fine-tuned post-editing models. We also demonstrate that multiple rounds of post-editing, which has not previously been explored, can be used to gradually improve the faithfulness of summaries whose errors cannot be fully corrected in a single round.
A Systematic Investigation of Knowledge Retrieval and Selection for Retrieval Augmented Generation
Oct 17, 2024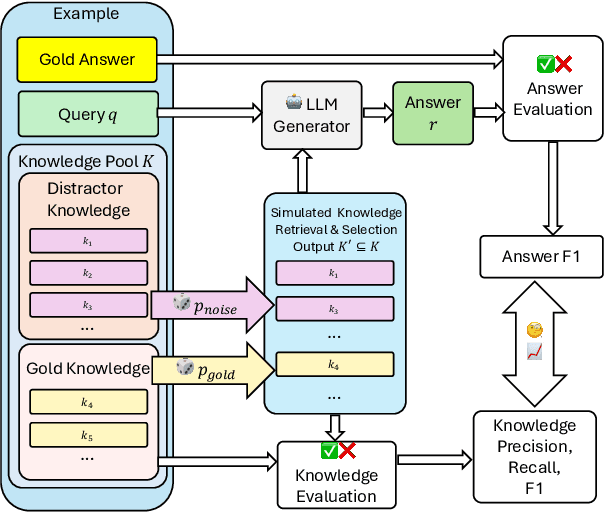
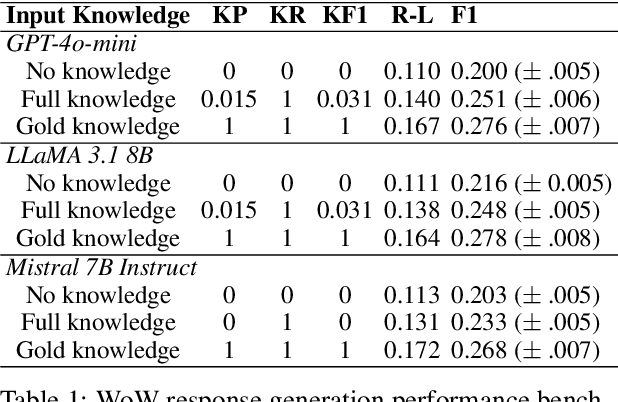
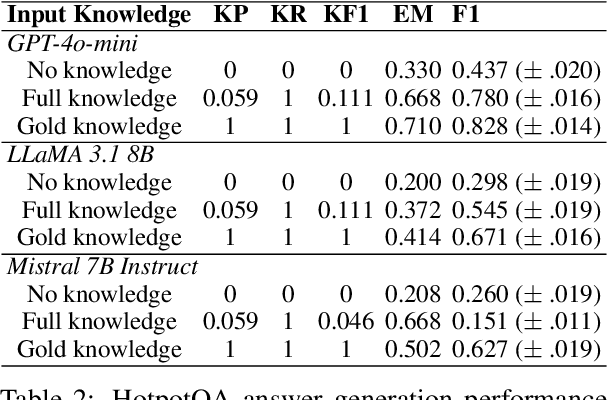
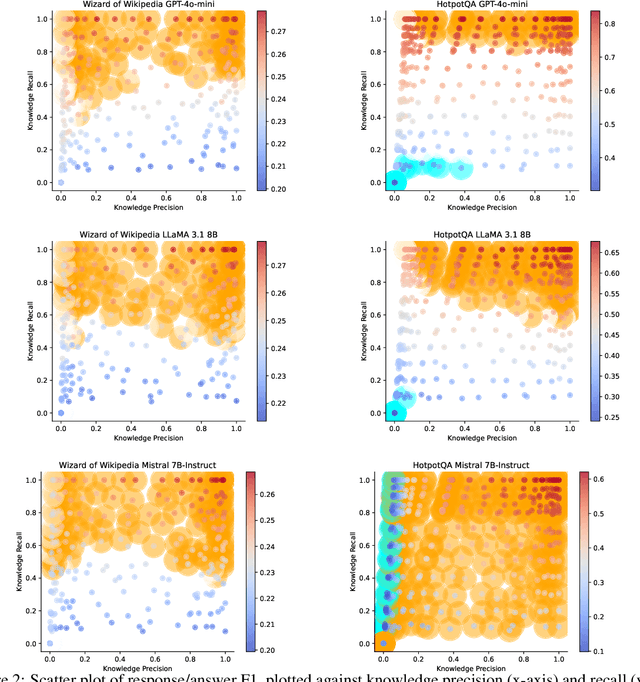
Retrieval-augmented generation (RAG) has emerged as a powerful method for enhancing natural language generation by integrating external knowledge into a model's output. While prior work has demonstrated the importance of improving knowledge retrieval for boosting generation quality, the role of knowledge selection remains less clear. In this paper, we perform a comprehensive analysis of how knowledge retrieval and selection influence downstream generation performance in RAG systems. By simulating different retrieval and selection conditions through a controlled mixture of gold and distractor knowledge, we assess the impact of these factors on generation outcomes. Our findings indicate that the downstream generator model's capability, as well as the complexity of the task and dataset, significantly influence the impact of knowledge retrieval and selection on the overall RAG system performance. In typical scenarios, improving the knowledge recall score is key to enhancing generation outcomes, with the knowledge selector providing a limited additional benefit when a strong generator model is used on clear, well-defined tasks. For weaker generator models or more ambiguous tasks and datasets, the knowledge F1 score becomes a critical factor, and the knowledge selector plays a more prominent role in improving overall performance.
Improving Citation Text Generation: Overcoming Limitations in Length Control
Jul 20, 2024A key challenge in citation text generation is that the length of generated text often differs from the length of the target, lowering the quality of the generation. While prior works have investigated length-controlled generation, their effectiveness depends on knowing the appropriate generation length. In this work, we present an in-depth study of the limitations of predicting scientific citation text length and explore the use of heuristic estimates of desired length.
Minimal Evidence Group Identification for Claim Verification
Apr 24, 2024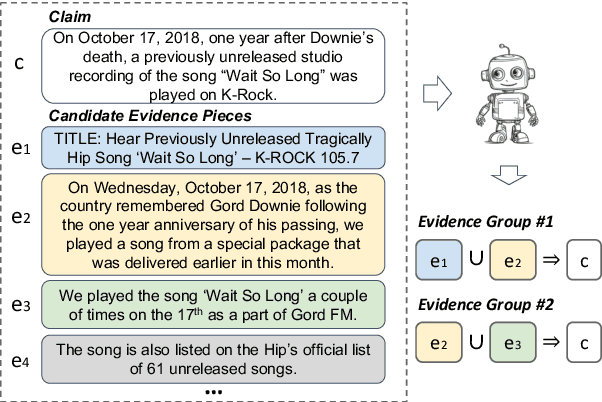
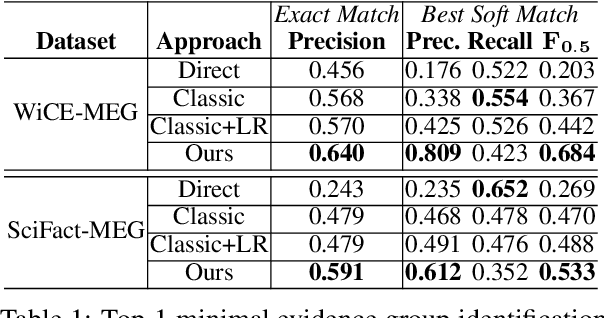
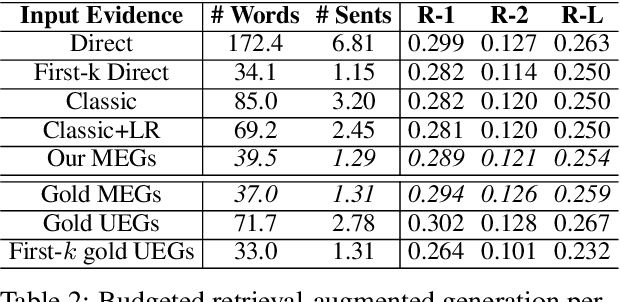

Claim verification in real-world settings (e.g. against a large collection of candidate evidences retrieved from the web) typically requires identifying and aggregating a complete set of evidence pieces that collectively provide full support to the claim. The problem becomes particularly challenging when there exists distinct sets of evidence that could be used to verify the claim from different perspectives. In this paper, we formally define and study the problem of identifying such minimal evidence groups (MEGs) for claim verification. We show that MEG identification can be reduced from Set Cover problem, based on entailment inference of whether a given evidence group provides full/partial support to a claim. Our proposed approach achieves 18.4% and 34.8% absolute improvements on the WiCE and SciFact datasets over LLM prompting. Finally, we demonstrate the benefits of MEGs in downstream applications such as claim generation.
Related Work and Citation Text Generation: A Survey
Apr 17, 2024To convince readers of the novelty of their research paper, authors must perform a literature review and compose a coherent story that connects and relates prior works to the current work. This challenging nature of literature review writing makes automatic related work generation (RWG) academically and computationally interesting, and also makes it an excellent test bed for examining the capability of SOTA natural language processing (NLP) models. Since the initial proposal of the RWG task, its popularity has waxed and waned, following the capabilities of mainstream NLP approaches. In this work, we survey the zoo of RWG historical works, summarizing the key approaches and task definitions and discussing the ongoing challenges of RWG.
A Knowledge Plug-and-Play Test Bed for Open-domain Dialogue Generation
Mar 06, 2024
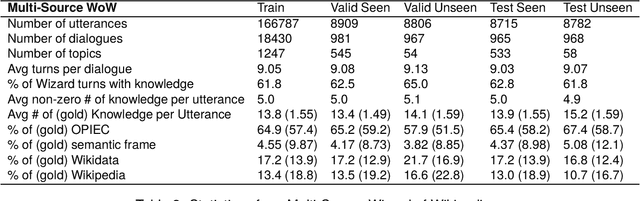

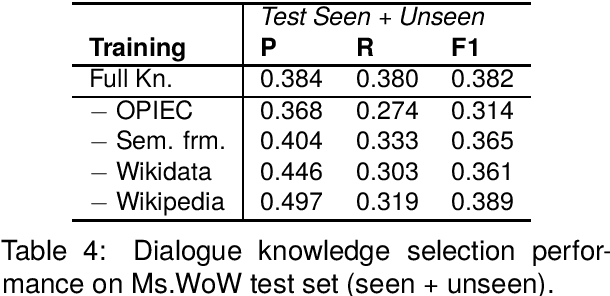
Knowledge-based, open-domain dialogue generation aims to build chit-chat systems that talk to humans using mined support knowledge. Many types and sources of knowledge have previously been shown to be useful as support knowledge. Even in the era of large language models, response generation grounded in knowledge retrieved from additional up-to-date sources remains a practically important approach. While prior work using single-source knowledge has shown a clear positive correlation between the performances of knowledge selection and response generation, there are no existing multi-source datasets for evaluating support knowledge retrieval. Further, prior work has assumed that the knowledge sources available at test time are the same as during training. This unrealistic assumption unnecessarily handicaps models, as new knowledge sources can become available after a model is trained. In this paper, we present a high-quality benchmark named multi-source Wizard of Wikipedia (Ms.WoW) for evaluating multi-source dialogue knowledge selection and response generation. Unlike existing datasets, it contains clean support knowledge, grounded at the utterance level and partitioned into multiple knowledge sources. We further propose a new challenge, dialogue knowledge plug-and-play, which aims to test an already trained dialogue model on using new support knowledge from previously unseen sources in a zero-shot fashion.
Contextualizing Generated Citation Texts
Feb 28, 2024Abstractive citation text generation is usually framed as an infilling task, where a sequence-to-sequence model is trained to generate a citation given a reference paper and the context window around the target; the generated citation should be a brief discussion of the reference paper as it relates to the citing context. However, examining a recent LED-based citation generation system, we find that many of the generated citations are generic summaries of the reference papers main contribution, ignoring the citation contexts focus on a different topic. To address this problem, we propose a simple modification to the citation text generation task: the generation target is not only the citation itself, but the entire context window, including the target citation. This approach can be easily applied to any abstractive citation generation system, and our experimental results show that training in this way is preferred by human readers and allows the generation model to make use of contextual clues about what topic to discuss and what stance to take.
Explaining Relationships Among Research Papers
Feb 20, 2024Due to the rapid pace of research publications, keeping up to date with all the latest related papers is very time-consuming, even with daily feed tools. There is a need for automatically generated, short, customized literature reviews of sets of papers to help researchers decide what to read. While several works in the last decade have addressed the task of explaining a single research paper, usually in the context of another paper citing it, the relationship among multiple papers has been ignored; prior works have focused on generating a single citation sentence in isolation, without addressing the expository and transition sentences needed to connect multiple papers in a coherent story. In this work, we explore a feature-based, LLM-prompting approach to generate richer citation texts, as well as generating multiple citations at once to capture the complex relationships among research papers. We perform an expert evaluation to investigate the impact of our proposed features on the quality of the generated paragraphs and find a strong correlation between human preference and integrative writing style, suggesting that humans prefer high-level, abstract citations, with transition sentences between them to provide an overall story.
Cited Text Spans for Citation Text Generation
Sep 12, 2023



Automatic related work generation must ground their outputs to the content of the cited papers to avoid non-factual hallucinations, but due to the length of scientific documents, existing abstractive approaches have conditioned only on the cited paper \textit{abstracts}. We demonstrate that the abstract is not always the most appropriate input for citation generation and that models trained in this way learn to hallucinate. We propose to condition instead on the \textit{cited text span} (CTS) as an alternative to the abstract. Because manual CTS annotation is extremely time- and labor-intensive, we experiment with automatic, ROUGE-based labeling of candidate CTS sentences, achieving sufficiently strong performance to substitute for expensive human annotations, and we propose a human-in-the-loop, keyword-based CTS retrieval approach that makes generating citation texts grounded in the full text of cited papers both promising and practical.