 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Investigation of Knowledge Retrieval and Selection for Retrieval Augmented Generation
Paper and Code
Oct 17, 2024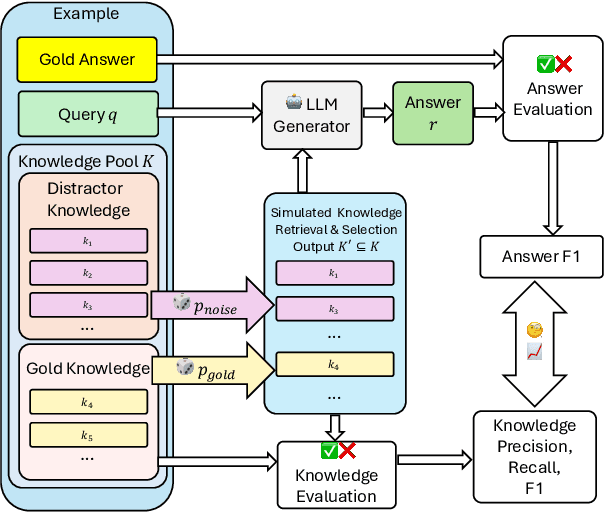
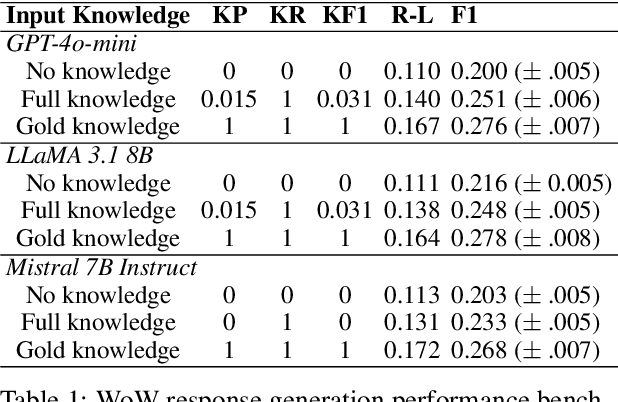
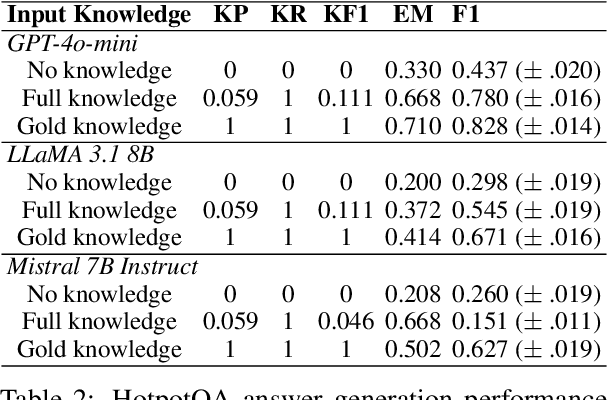
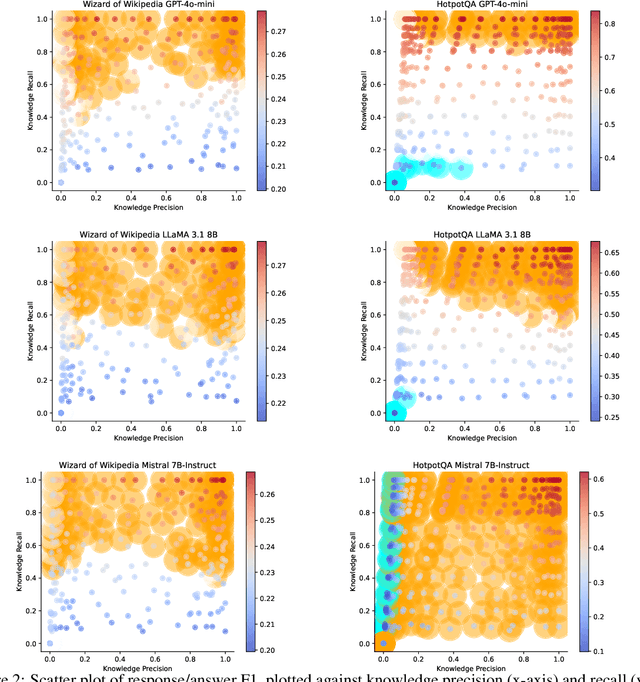
Retrieval-augmented generation (RAG) has emerged as a powerful method for enhancing natural language generation by integrating external knowledge into a model's output. While prior work has demonstrated the importance of improving knowledge retrieval for boosting generation quality, the role of knowledge selection remains less clear. In this paper, we perform a comprehensive analysis of how knowledge retrieval and selection influence downstream generation performance in RAG systems. By simulating different retrieval and selection conditions through a controlled mixture of gold and distractor knowledge, we assess the impact of these factors on generation outcomes. Our findings indicate that the downstream generator model's capability, as well as the complexity of the task and dataset, significantly influence the impact of knowledge retrieval and selection on the overall RAG system performance. In typical scenarios, improving the knowledge recall score is key to enhancing generation outcomes, with the knowledge selector providing a limited additional benefit when a strong generator model is used on clear, well-defined tasks. For weaker generator models or more ambiguous tasks and datasets, the knowledge F1 score becomes a critical factor, and the knowledge selector plays a more prominent role in improving overall performance.