 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Staff: Offline Reinforcement Learning and Fine-Tuned LLMs for Warehouse Staffing Optimization
Mar 25, 2026We investigate machine learning approaches for optimizing real-time staffing decisions in semi-automated warehouse sortation systems. Operational decision-making can be supported at different levels of abstraction, with different trade-offs. We evaluate two approaches, each in a matching simulation environment. First, we train custom Transformer-based policies using offline reinforcement learning on detailed historical state representations, achieving a 2.4% throughput improvement over historical baselines in learned simulators. In high-volume warehouse operations, improvements of this size translate to significant savings. Second, we explore LLMs operating on abstracted, human-readable state descriptions. These are a natural fit for decisions that warehouse managers make using high-level operational summaries. We systematically compare prompting techniques, automatic prompt optimization, and fine-tuning strategies. While prompting alone proves insufficient, supervised fine-tuning combined with Direct Preference Optimization on simulator-generated preferences achieves performance that matches or slightly exceeds historical baselines in a hand-crafted simulator. Our findings demonstrate that both approaches offer viable paths toward AI-assisted operational decision-making. Offline RL excels with task-specific architectures. LLMs support human-readable inputs and can be combined with an iterative feedback loop that can incorporate manager preferences.
A Modular LLM Framework for Explainable Price Outlier Detection
Mar 21, 2026Detecting product price outliers is important for retail and e-commerce stores as erroneous or unexpectedly high prices adversely affect competitiveness, revenue, and consumer trust. Classical techniques offer simple thresholds while ignoring the rich semantic relationships among product attributes. We propose an agentic Large Language Model (LLM) framework that treats outlier price flagging as a reasoning task grounded in related product detection and comparison. The system processes the prices of target products in three stages: (i) relevance classification selects price-relevant similar products using product descriptions and attributes; (ii) relative utility assessment evaluates the target product against each similar product along price influencing dimensions (e.g., brand, size, features); (iii) reasoning-based decision aggregates these justifications into an explainable price outlier judgment. The framework attains over 75% agreement with human auditors on a test dataset, and outperforms zero-shot and retrieval based LLM techniques. Ablation studies show the sensitivity of the method to key hyper-parameters and testify on its flexibility to be applied to cases with different accuracy requirement and auditor agreements.
Hint-Augmented Re-ranking: Efficient Product Search using LLM-Based Query Decomposition
Nov 17, 2025Search queries with superlatives (e.g., best, most popular) require comparing candidates across multiple dimensions, demanding linguistic understanding and domain knowledge. We show that LLMs can uncover latent intent behind these expressions in e-commerce queries through a framework that extracts structured interpretations or hints. Our approach decomposes queries into attribute-value hints generated concurrently with retrieval, enabling efficient integration into the ranking pipeline. Our method improves search performanc eby 10.9 points in MAP and ranking by 5.9 points in MRR over baselines. Since direct LLM-based reranking faces prohibitive latency, we develop an efficient approach transferring superlative interpretations to lightweight models. Our findings provide insights into how superlative semantics can be represented and transferred between models, advancing linguistic interpretation in retrieval systems while addressing practical deployment constraints.
Quantile Regression with Large Language Models for Price Prediction
Jun 07, 2025Large Language Models (LLMs) have shown promise in structured prediction tasks, including regression, but existing approaches primarily focus on point estimates and lack systematic comparison across different methods. We investigate probabilistic regression using LLMs for unstructured inputs, addressing challenging text-to-distribution prediction tasks such as price estimation where both nuanced text understanding and uncertainty quantification are critical. We propose a novel quantile regression approach that enables LLMs to produce full predictive distributions, improving upon traditional point estimates. Through extensive experiments across three diverse price prediction datasets, we demonstrate that a Mistral-7B model fine-tuned with quantile heads significantly outperforms traditional approaches for both point and distributional estimations, as measured by three established metrics each for prediction accuracy and distributional calibration. Our systematic comparison of LLM approaches, model architectures, training approaches, and data scaling reveals that Mistral-7B consistently outperforms encoder architectures, embedding-based methods, and few-shot learning methods. Our experiments also reveal the effectiveness of LLM-assisted label correction in achieving human-level accuracy without systematic bias. Our curated datasets are made available at https://github.com/vnik18/llm-price-quantile-reg/ to support future research.
Generative Product Recommendations for Implicit Superlative Queries
Apr 26, 2025In Recommender Systems, users often seek the best products through indirect, vague, or under-specified queries, such as "best shoes for trail running". Such queries, also referred to as implicit superlative queries, pose a significant challenge for standard retrieval and ranking systems as they lack an explicit mention of attributes and require identifying and reasoning over complex factors. We investigate how Large Language Models (LLMs) can generate implicit attributes for ranking as well as reason over them to improve product recommendations for such queries. As a first step, we propose a novel four-point schema for annotating the best product candidates for superlative queries called SUPERB, paired with LLM-based product annotations. We then empirically evaluate several existing retrieval and ranking approaches on our new dataset, providing insights and discussing their integration into real-world e-commerce production systems.
Wizard of Shopping: Target-Oriented E-commerce Dialogue Generation with Decision Tree Branching
Feb 03, 2025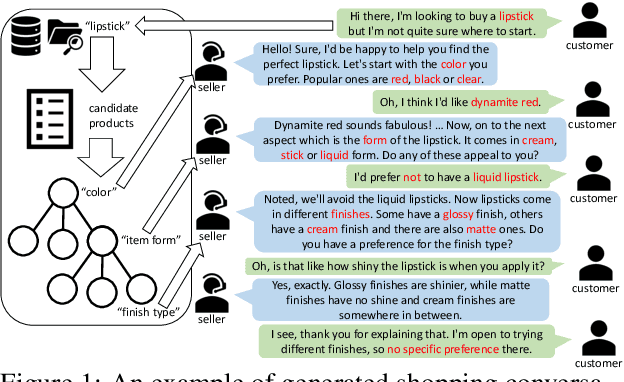

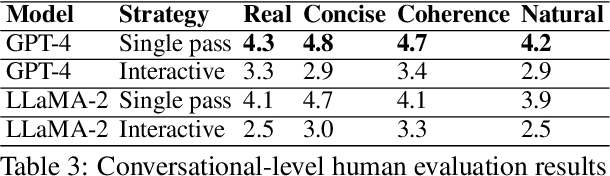
The goal of conversational product search (CPS) is to develop an intelligent, chat-based shopping assistant that can directly interact with customers to understand shopping intents, ask clarification questions, and find relevant products. However, training such assistants is hindered mainly due to the lack of reliable and large-scale datasets. Prior human-annotated CPS datasets are extremely small in size and lack integration with real-world product search systems. We propose a novel approach, TRACER, which leverages large language models (LLMs) to generate realistic and natural conversations for different shopping domains. TRACER's novelty lies in grounding the generation to dialogue plans, which are product search trajectories predicted from a decision tree model, that guarantees relevant product discovery in the shortest number of search conditions. We also release the first target-oriented CPS dataset Wizard of Shopping (WoS), containing highly natural and coherent conversations (3.6k) from three shopping domains. Finally, we demonstrate the quality and effectiveness of WoS via human evaluations and downstream tasks.
Identifying High Consideration E-Commerce Search Queries
Oct 17, 2024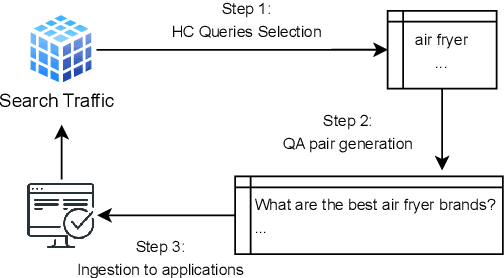
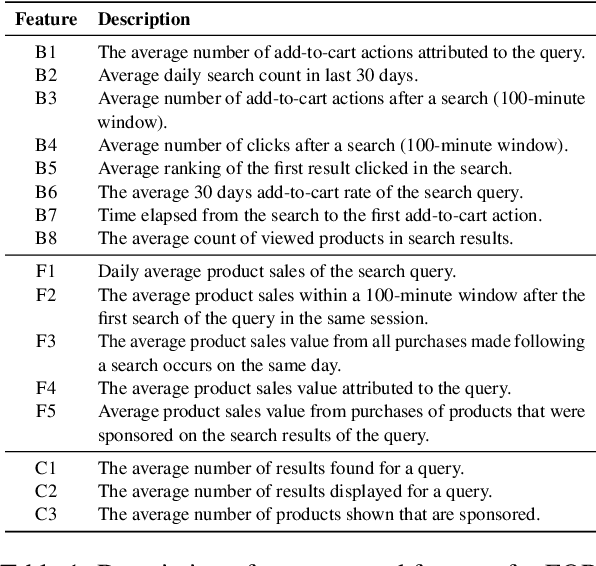
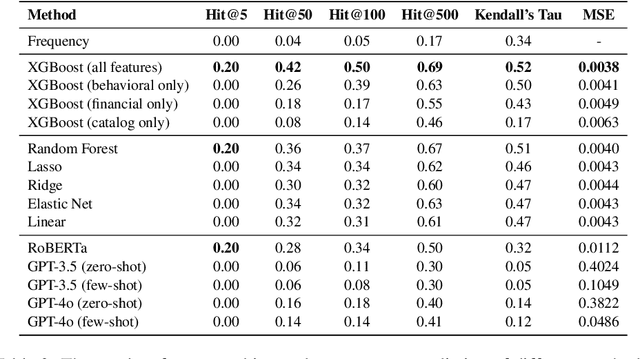
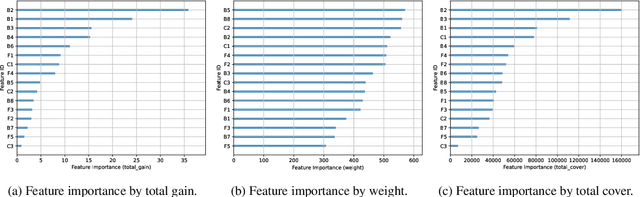
In e-commerce, high consideration search missions typically require careful and elaborate decision making, and involve a substantial research investment from customers. We consider the task of identifying High Consideration (HC) queries. Identifying such queries enables e-commerce sites to better serve user needs using targeted experiences such as curated QA widgets that help users reach purchase decisions. We explore the task by proposing an Engagement-based Query Ranking (EQR) approach, focusing on query ranking to indicate potential engagement levels with query-related shopping knowledge content during product search. Unlike previous studies on predicting trends, EQR prioritizes query-level features related to customer behavior, finance, and catalog information rather than popularity signals. We introduce an accurate and scalable method for EQR and present experimental results demonstrating its effectiveness. Offline experiments show strong ranking performance. Human evaluation shows a precision of 96% for HC queries identified by our model. The model was commercially deployed, and shown to outperform human-selected queries in terms of downstream customer impact, as measured through engagement.
Bridging the Gap Between Information Seeking and Product Search Systems: Q&A Recommendation for E-commerce
Jul 12, 2024Consumers on a shopping mission often leverage both product search and information seeking systems, such as web search engines and Question Answering (QA) systems, in an iterative process to improve their understanding of available products and reach a purchase decision. While product search is useful for shoppers to find the actual products meeting their requirements in the catalog, information seeking systems can be utilized to answer any questions they may have to refine those requirements. The recent success of Large Language Models (LLMs) has opened up an opportunity to bridge the gap between the two tasks to help customers achieve their goals quickly and effectively by integrating conversational QA within product search. In this paper, we propose to recommend users Question-Answer (Q&A) pairs that are relevant to their product search and can help them make a purchase decision. We discuss the different aspects of the problem including the requirements and characteristics of the Q&A pairs, their generation, and the optimization of the Q&A recommendation task. We highlight the challenges, open problems, and suggested solutions to encourage future research in this emerging area.
Generative Explore-Exploit: Training-free Optimization of Generative Recommender Systems using LLM Optimizers
Jun 07, 2024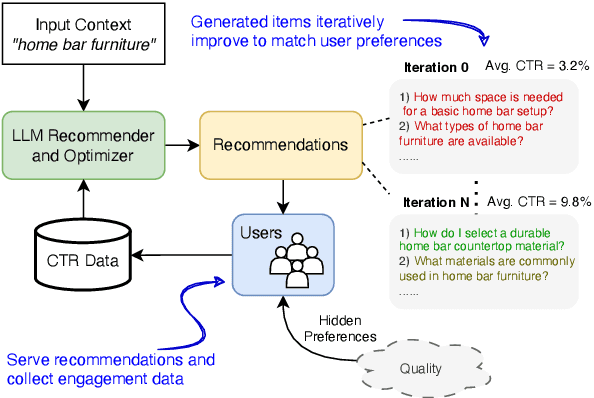



Recommender systems are widely used to suggest engaging content, and Large Language Models (LLMs) have given rise to generative recommenders. Such systems can directly generate items, including for open-set tasks like question suggestion. While the world knowledge of LLMs enable good recommendations, improving the generated content through user feedback is challenging as continuously fine-tuning LLMs is prohibitively expensive. We present a training-free approach for optimizing generative recommenders by connecting user feedback loops to LLM-based optimizers. We propose a generative explore-exploit method that can not only exploit generated items with known high engagement, but also actively explore and discover hidden population preferences to improve recommendation quality. We evaluate our approach on question generation in two domains (e-commerce and general knowledge), and model user feedback with Click Through Rate (CTR). Experiments show our LLM-based explore-exploit approach can iteratively improve recommendations, and consistently increase CTR. Ablation analysis shows that generative exploration is key to learning user preferences, avoiding the pitfalls of greedy exploit-only approaches. A human evaluation strongly supports our quantitative findings.
Question Suggestion for Conversational Shopping Assistants Using Product Metadata
May 02, 2024
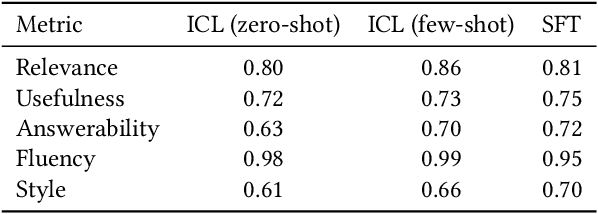
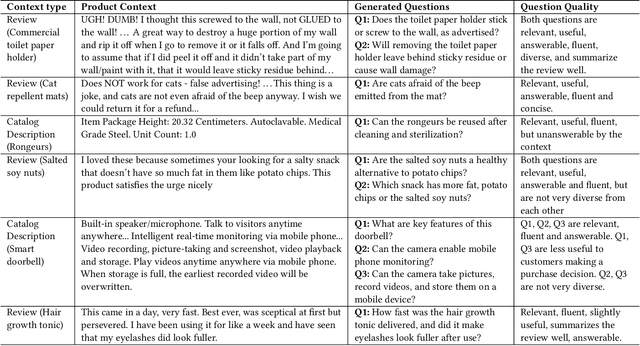
Digital assistants have become ubiquitous in e-commerce applications, following the recent advancements in Information Retrieval (IR), Natural Language Processing (NLP) and Generative Artificial Intelligence (AI). However, customers are often unsure or unaware of how to effectively converse with these assistants to meet their shopping needs. In this work, we emphasize the importance of providing customers a fast, easy to use, and natural way to interact with conversational shopping assistants. We propose a framework that employs Large Language Models (LLMs) to automatically generate contextual, useful, answerable, fluent and diverse questions about products, via in-context learning and supervised fine-tuning. Recommending these questions to customers as helpful suggestions or hints to both start and continue a conversation can result in a smoother and faster shopping experience with reduced conversation overhead and friction. We perform extensive offline evaluations, and discuss in detail about potential customer impact, and the type, length and latency of our generated product questions if incorporated into a real-world shopping assistant.