 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Explore-Exploit: Training-free Optimization of Generative Recommender Systems using LLM Optimizers
Jun 07, 2024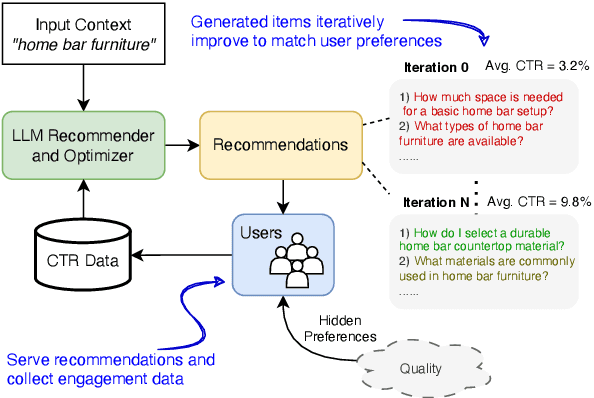



Recommender systems are widely used to suggest engaging content, and Large Language Models (LLMs) have given rise to generative recommenders. Such systems can directly generate items, including for open-set tasks like question suggestion. While the world knowledge of LLMs enable good recommendations, improving the generated content through user feedback is challenging as continuously fine-tuning LLMs is prohibitively expensive. We present a training-free approach for optimizing generative recommenders by connecting user feedback loops to LLM-based optimizers. We propose a generative explore-exploit method that can not only exploit generated items with known high engagement, but also actively explore and discover hidden population preferences to improve recommendation quality. We evaluate our approach on question generation in two domains (e-commerce and general knowledge), and model user feedback with Click Through Rate (CTR). Experiments show our LLM-based explore-exploit approach can iteratively improve recommendations, and consistently increase CTR. Ablation analysis shows that generative exploration is key to learning user preferences, avoiding the pitfalls of greedy exploit-only approaches. A human evaluation strongly supports our quantitative findings.
CoDA21: Evaluating Language Understanding Capabilities of NLP Models With Context-Definition Alignment
Mar 11, 2022



Pretrained language models (PLMs) have achieved superhuman performance on many benchmarks, creating a need for harder tasks. We introduce CoDA21 (Context Definition Alignment), a challenging benchmark that measures natural language understanding (NLU) capabilities of PLMs: Given a definition and a context each for k words, but not the words themselves, the task is to align the k definitions with the k contexts. CoDA21 requires a deep understanding of contexts and definitions, including complex inference and world knowledge. We find that there is a large gap between human and PLM performance, suggesting that CoDA21 measures an aspect of NLU that is not sufficiently covered in existing benchmarks.