 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByteFlow: Language Modeling through Adaptive Byte Compression without a Tokenizer
Mar 03, 2026Modern language models still rely on fixed, pre-defined subword tokenizations. Once a tokenizer is trained, the LM can only operate at this fixed level of granularity, which often leads to brittle and counterintuitive behaviors even in otherwise strong reasoning models. We introduce \textbf{ByteFlow Net}, a new hierarchical architecture that removes tokenizers entirely and instead enables models to learn their own segmentation of raw byte streams into semantically meaningful units. ByteFlow Net performs compression-driven segmentation based on the coding rate of latent representations, yielding adaptive boundaries \emph{while preserving a static computation graph via Top-$K$ selection}. Unlike prior self-tokenizing methods that depend on brittle heuristics with human-designed inductive biases, ByteFlow Net adapts its internal representation granularity to the input itself. Experiments demonstrate that this compression-based chunking strategy yields substantial performance gains, with ByteFlow Net outperforming both BPE-based Transformers and previous byte-level architectures. These results suggest that end-to-end, tokenizer-free modeling is not only feasible but also more effective, opening a path toward more adaptive and information-grounded language models.
Stepwise Penalization for Length-Efficient Chain-of-Thought Reasoning
Feb 27, 2026Large reasoning models improve with more test-time computation, but often overthink, producing unnecessarily long chains-of-thought that raise cost without improving accuracy. Prior reinforcement learning approaches typically rely on a single outcome reward with trajectory-level length penalties, which cannot distinguish essential from redundant reasoning steps and therefore yield blunt compression. Although recent work incorporates step-level signals, such as offline pruning, supervised data construction, or verifier-based intermediate rewards, reasoning length is rarely treated as an explicit step-level optimization objective during RL. We propose Step-wise Adaptive Penalization (SWAP), a fine-grained framework that allocates length reduction across steps based on intrinsic contribution. We estimate step importance from the model's on-policy log-probability improvement toward the correct answer, then treat excess length as a penalty mass redistributed to penalize low-importance steps more heavily while preserving high-importance reasoning. We optimize with a unified outcome-process advantage within group-relative policy optimization. Extensive experiments demonstrate that SWAP reduces reasoning length by 64.3% on average while improving accuracy by 5.7% relative to the base model.
Wizard of Shopping: Target-Oriented E-commerce Dialogue Generation with Decision Tree Branching
Feb 03, 2025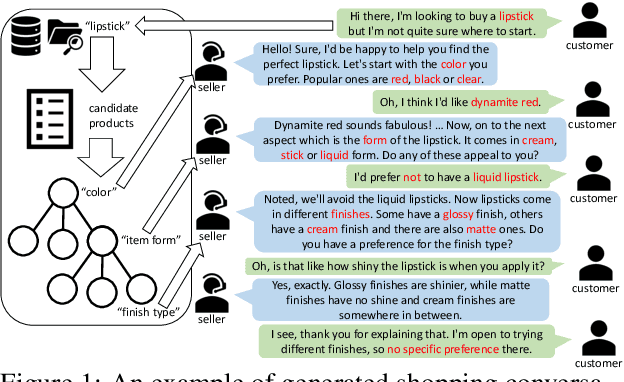

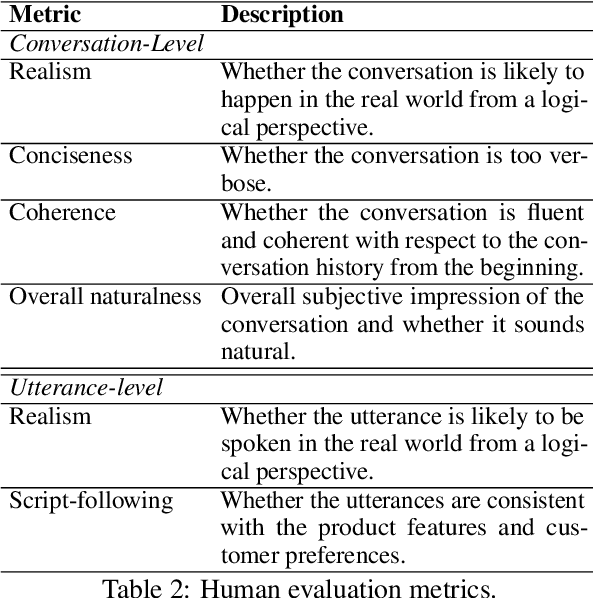
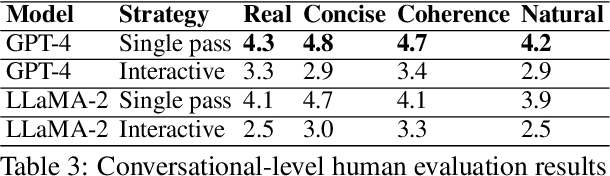
The goal of conversational product search (CPS) is to develop an intelligent, chat-based shopping assistant that can directly interact with customers to understand shopping intents, ask clarification questions, and find relevant products. However, training such assistants is hindered mainly due to the lack of reliable and large-scale datasets. Prior human-annotated CPS datasets are extremely small in size and lack integration with real-world product search systems. We propose a novel approach, TRACER, which leverages large language models (LLMs) to generate realistic and natural conversations for different shopping domains. TRACER's novelty lies in grounding the generation to dialogue plans, which are product search trajectories predicted from a decision tree model, that guarantees relevant product discovery in the shortest number of search conditions. We also release the first target-oriented CPS dataset Wizard of Shopping (WoS), containing highly natural and coherent conversations (3.6k) from three shopping domains. Finally, we demonstrate the quality and effectiveness of WoS via human evaluations and downstream tasks.
Identifying High Consideration E-Commerce Search Queries
Oct 17, 2024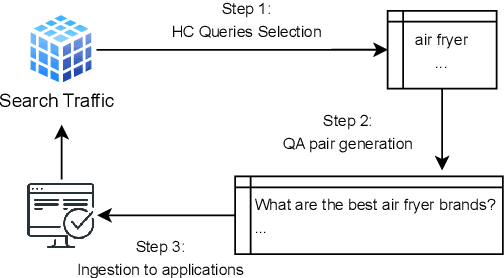
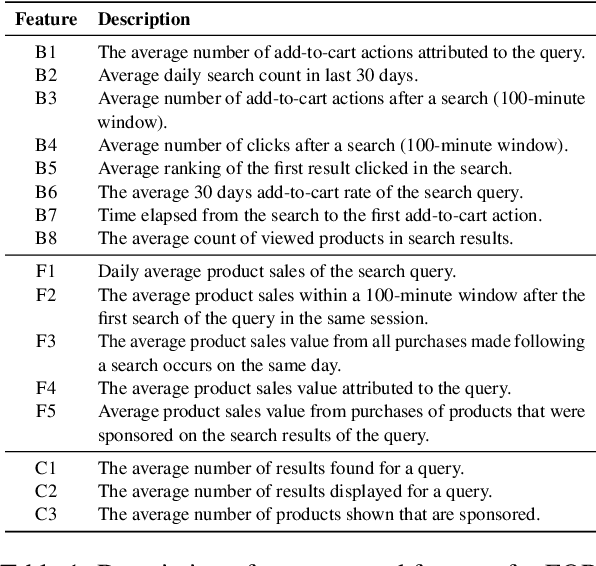
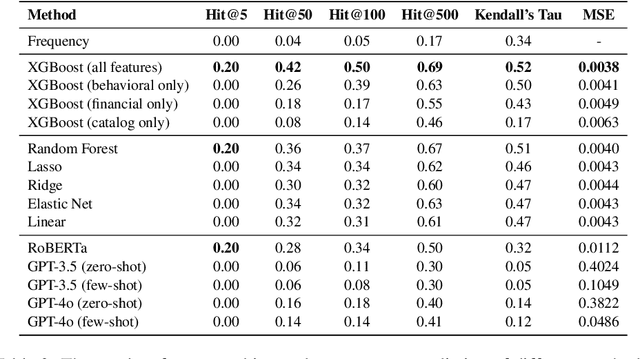
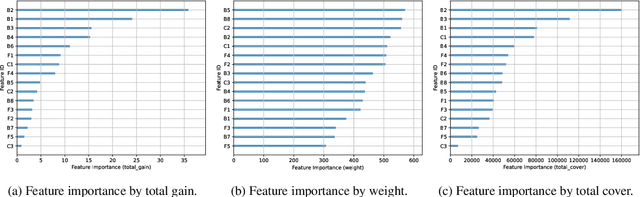
In e-commerce, high consideration search missions typically require careful and elaborate decision making, and involve a substantial research investment from customers. We consider the task of identifying High Consideration (HC) queries. Identifying such queries enables e-commerce sites to better serve user needs using targeted experiences such as curated QA widgets that help users reach purchase decisions. We explore the task by proposing an Engagement-based Query Ranking (EQR) approach, focusing on query ranking to indicate potential engagement levels with query-related shopping knowledge content during product search. Unlike previous studies on predicting trends, EQR prioritizes query-level features related to customer behavior, finance, and catalog information rather than popularity signals. We introduce an accurate and scalable method for EQR and present experimental results demonstrating its effectiveness. Offline experiments show strong ranking performance. Human evaluation shows a precision of 96% for HC queries identified by our model. The model was commercially deployed, and shown to outperform human-selected queries in terms of downstream customer impact, as measured through engagement.
Generative Explore-Exploit: Training-free Optimization of Generative Recommender Systems using LLM Optimizers
Jun 07, 2024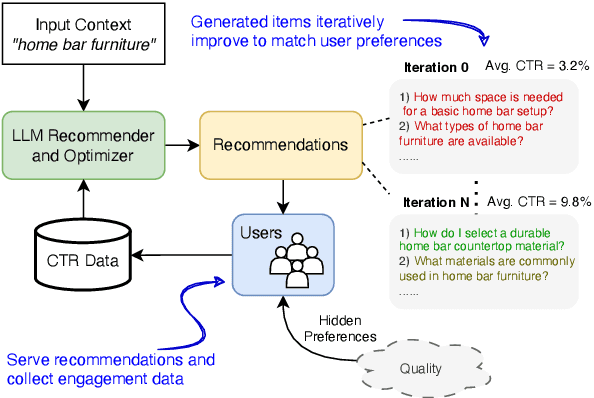



Recommender systems are widely used to suggest engaging content, and Large Language Models (LLMs) have given rise to generative recommenders. Such systems can directly generate items, including for open-set tasks like question suggestion. While the world knowledge of LLMs enable good recommendations, improving the generated content through user feedback is challenging as continuously fine-tuning LLMs is prohibitively expensive. We present a training-free approach for optimizing generative recommenders by connecting user feedback loops to LLM-based optimizers. We propose a generative explore-exploit method that can not only exploit generated items with known high engagement, but also actively explore and discover hidden population preferences to improve recommendation quality. We evaluate our approach on question generation in two domains (e-commerce and general knowledge), and model user feedback with Click Through Rate (CTR). Experiments show our LLM-based explore-exploit approach can iteratively improve recommendations, and consistently increase CTR. Ablation analysis shows that generative exploration is key to learning user preferences, avoiding the pitfalls of greedy exploit-only approaches. A human evaluation strongly supports our quantitative findings.
Identifying Shopping Intent in Product QA for Proactive Recommendations
Apr 09, 2024


Voice assistants have become ubiquitous in smart devices allowing users to instantly access information via voice questions. While extensive research has been conducted in question answering for voice search, little attention has been paid on how to enable proactive recommendations from a voice assistant to its users. This is a highly challenging problem that often leads to user friction, mainly due to recommendations provided to the users at the wrong time. We focus on the domain of e-commerce, namely in identifying Shopping Product Questions (SPQs), where the user asking a product-related question may have an underlying shopping need. Identifying a user's shopping need allows voice assistants to enhance shopping experience by determining when to provide recommendations, such as product or deal recommendations, or proactive shopping actions recommendation. Identifying SPQs is a challenging problem and cannot be done from question text alone, and thus requires to infer latent user behavior patterns inferred from user's past shopping history. We propose features that capture the user's latent shopping behavior from their purchase history, and combine them using a novel Mixture-of-Experts (MoE) model. Our evaluation shows that the proposed approach is able to identify SPQs with a high score of F1=0.91. Furthermore, based on an online evaluation with real voice assistant users, we identify SPQs in real-time and recommend shopping actions to users to add the queried product into their shopping list. We demonstrate that we are able to accurately identify SPQs, as indicated by the significantly higher rate of added products to users' shopping lists when being prompted after SPQs vs random PQs.
Instant Answering in E-Commerce Buyer-Seller Messaging using Message-to-Question Reformulation
Jan 30, 2024
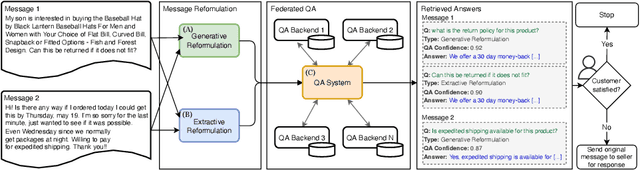
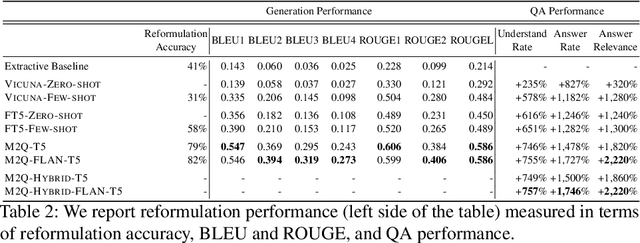
E-commerce customers frequently seek detailed product information for purchase decisions, commonly contacting sellers directly with extended queries. This manual response requirement imposes additional costs and disrupts buyer's shopping experience with response time fluctuations ranging from hours to days. We seek to automate buyer inquiries to sellers in a leading e-commerce store using a domain-specific federated Question Answering (QA) system. The main challenge is adapting current QA systems, designed for single questions, to address detailed customer queries. We address this with a low-latency, sequence-to-sequence approach, MESSAGE-TO-QUESTION ( M2Q ). It reformulates buyer messages into succinct questions by identifying and extracting the most salient information from a message. Evaluation against baselines shows that M2Q yields relative increases of 757% in question understanding, and 1,746% in answering rate from the federated QA system. Live deployment shows that automatic answering saves sellers from manually responding to millions of messages per year, and also accelerates customer purchase decisions by eliminating the need for buyers to wait for a reply
Controllable Decontextualization of Yes/No Question and Answers into Factual Statements
Jan 18, 2024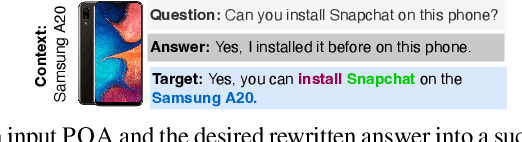


Yes/No or polar questions represent one of the main linguistic question categories. They consist of a main interrogative clause, for which the answer is binary (assertion or negation). Polar questions and answers (PQA) represent a valuable knowledge resource present in many community and other curated QA sources, such as forums or e-commerce applications. Using answers to polar questions alone in other contexts is not trivial. Answers are contextualized, and presume that the interrogative question clause and any shared knowledge between the asker and answerer are provided. We address the problem of controllable rewriting of answers to polar questions into decontextualized and succinct factual statements. We propose a Transformer sequence to sequence model that utilizes soft-constraints to ensure controllable rewriting, such that the output statement is semantically equivalent to its PQA input. Evaluation on three separate PQA datasets as measured through automated and human evaluation metrics show that our proposed approach achieves the best performance when compared to existing baselines.
InstructPTS: Instruction-Tuning LLMs for Product Title Summarization
Oct 25, 2023



E-commerce product catalogs contain billions of items. Most products have lengthy titles, as sellers pack them with product attributes to improve retrieval, and highlight key product aspects. This results in a gap between such unnatural products titles, and how customers refer to them. It also limits how e-commerce stores can use these seller-provided titles for recommendation, QA, or review summarization. Inspired by recent work on instruction-tuned LLMs, we present InstructPTS, a controllable approach for the task of Product Title Summarization (PTS). Trained using a novel instruction fine-tuning strategy, our approach is able to summarize product titles according to various criteria (e.g. number of words in a summary, inclusion of specific phrases, etc.). Extensive evaluation on a real-world e-commerce catalog shows that compared to simple fine-tuning of LLMs, our proposed approach can generate more accurate product name summaries, with an improvement of over 14 and 8 BLEU and ROUGE points, respectively.
Follow-on Question Suggestion via Voice Hints for Voice Assistants
Oct 25, 2023The adoption of voice assistants like Alexa or Siri has grown rapidly, allowing users to instantly access information via voice search. Query suggestion is a standard feature of screen-based search experiences, allowing users to explore additional topics. However, this is not trivial to implement in voice-based settings. To enable this, we tackle the novel task of suggesting questions with compact and natural voice hints to allow users to ask follow-up questions. We define the task, ground it in syntactic theory and outline linguistic desiderata for spoken hints. We propose baselines and an approach using sequence-to-sequence Transformers to generate spoken hints from a list of questions. Using a new dataset of 6681 input questions and human written hints, we evaluated the models with automatic metrics and human evaluation. Results show that a naive approach of concatenating suggested questions creates poor voice hints. Our approach, which applies a linguistically-motivated pretraining task was strongly preferred by humans for producing the most natural hints.