 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Master Key Hypothesis: Unlocking Cross-Model Capability Transfer via Linear Subspace Alignment
Apr 07, 2026We investigate whether post-trained capabilities can be transferred across models without retraining, with a focus on transfer across different model scales. We propose the Master Key Hypothesis, which states that model capabilities correspond to directions in a low-dimensional latent subspace that induce specific behaviors and are transferable across models through linear alignment. Based on this hypothesis, we introduce UNLOCK, a training-free and label-free framework that extracts a capability direction by contrasting activations between capability-present and capability-absent Source variants, aligns it with a Target model through a low-rank linear transformation, and applies it at inference time to elicit the behavior. Experiments on reasoning behaviors, including Chain-of-Thought (CoT) and mathematical reasoning, demonstrate substantial improvements across model scales without training. For example, transferring CoT reasoning from Qwen1.5-14B to Qwen1.5-7B yields an accuracy gain of 12.1% on MATH, and transferring a mathematical reasoning direction from Qwen3-4B-Base to Qwen3-14B-Base improves AGIEval Math accuracy from 61.1% to 71.3%, surpassing the 67.8% achieved by the 14B post-trained model. Our analysis shows that the success of transfer depends on the capabilities learned during pre-training, and that our intervention amplifies latent capabilities by sharpening the output distribution toward successful reasoning trajectories.
Follow-on Question Suggestion via Voice Hints for Voice Assistants
Oct 25, 2023The adoption of voice assistants like Alexa or Siri has grown rapidly, allowing users to instantly access information via voice search. Query suggestion is a standard feature of screen-based search experiences, allowing users to explore additional topics. However, this is not trivial to implement in voice-based settings. To enable this, we tackle the novel task of suggesting questions with compact and natural voice hints to allow users to ask follow-up questions. We define the task, ground it in syntactic theory and outline linguistic desiderata for spoken hints. We propose baselines and an approach using sequence-to-sequence Transformers to generate spoken hints from a list of questions. Using a new dataset of 6681 input questions and human written hints, we evaluated the models with automatic metrics and human evaluation. Results show that a naive approach of concatenating suggested questions creates poor voice hints. Our approach, which applies a linguistically-motivated pretraining task was strongly preferred by humans for producing the most natural hints.
HTEC: Human Transcription Error Correction
Sep 18, 2023



High-quality human transcription is essential for training and improving Automatic Speech Recognition (ASR) models. Recent study~\cite{libricrowd} has found that every 1% worse transcription Word Error Rate (WER) increases approximately 2% ASR WER by using the transcriptions to train ASR models. Transcription errors are inevitable for even highly-trained annotators. However, few studies have explored human transcription correction. Error correction methods for other problems, such as ASR error correction and grammatical error correction, do not perform sufficiently for this problem. Therefore, we propose HTEC for Human Transcription Error Correction. HTEC consists of two stages: Trans-Checker, an error detection model that predicts and masks erroneous words, and Trans-Filler, a sequence-to-sequence generative model that fills masked positions. We propose a holistic list of correction operations, including four novel operations handling deletion errors. We further propose a variant of embeddings that incorporates phoneme information into the input of the transformer. HTEC outperforms other methods by a large margin and surpasses human annotators by 2.2% to 4.5% in WER. Finally, we deployed HTEC to assist human annotators and showed HTEC is particularly effective as a co-pilot, which improves transcription quality by 15.1% without sacrificing transcription velocity.
Reinforced Question Rewriting for Conversational Question Answering
Oct 31, 2022Conversational Question Answering (CQA) aims to answer questions contained within dialogues, which are not easily interpretable without context. Developing a model to rewrite conversational questions into self-contained ones is an emerging solution in industry settings as it allows using existing single-turn QA systems to avoid training a CQA model from scratch. Previous work trains rewriting models using human rewrites as supervision. However, such objectives are disconnected with QA models and therefore more human-like rewrites do not guarantee better QA performance. In this paper we propose using QA feedback to supervise the rewriting model with reinforcement learning. Experiments show that our approach can effectively improve QA performance over baselines for both extractive and retrieval QA. Furthermore, human evaluation shows that our method can generate more accurate and detailed rewrites when compared to human annotations.
MultiCoNER: A Large-scale Multilingual dataset for Complex Named Entity Recognition
Aug 30, 2022


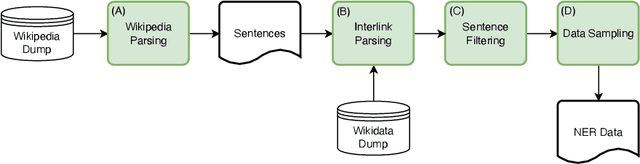
We present MultiCoNER, a large multilingual dataset for Named Entity Recognition that covers 3 domains (Wiki sentences, questions, and search queries) across 11 languages, as well as multilingual and code-mixing subsets. This dataset is designed to represent contemporary challenges in NER, including low-context scenarios (short and uncased text), syntactically complex entities like movie titles, and long-tail entity distributions. The 26M token dataset is compiled from public resources using techniques such as heuristic-based sentence sampling, template extraction and slotting, and machine translation. We applied two NER models on our dataset: a baseline XLM-RoBERTa model, and a state-of-the-art GEMNET model that leverages gazetteers. The baseline achieves moderate performance (macro-F1=54%), highlighting the difficulty of our data. GEMNET, which uses gazetteers, improvement significantly (average improvement of macro-F1=+30%). MultiCoNER poses challenges even for large pre-trained language models, and we believe that it can help further research in building robust NER systems. MultiCoNER is publicly available at https://registry.opendata.aws/multiconer/ and we hope that this resource will help advance research in various aspects of NER.