 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Master Key Hypothesis: Unlocking Cross-Model Capability Transfer via Linear Subspace Alignment
Apr 07, 2026We investigate whether post-trained capabilities can be transferred across models without retraining, with a focus on transfer across different model scales. We propose the Master Key Hypothesis, which states that model capabilities correspond to directions in a low-dimensional latent subspace that induce specific behaviors and are transferable across models through linear alignment. Based on this hypothesis, we introduce UNLOCK, a training-free and label-free framework that extracts a capability direction by contrasting activations between capability-present and capability-absent Source variants, aligns it with a Target model through a low-rank linear transformation, and applies it at inference time to elicit the behavior. Experiments on reasoning behaviors, including Chain-of-Thought (CoT) and mathematical reasoning, demonstrate substantial improvements across model scales without training. For example, transferring CoT reasoning from Qwen1.5-14B to Qwen1.5-7B yields an accuracy gain of 12.1% on MATH, and transferring a mathematical reasoning direction from Qwen3-4B-Base to Qwen3-14B-Base improves AGIEval Math accuracy from 61.1% to 71.3%, surpassing the 67.8% achieved by the 14B post-trained model. Our analysis shows that the success of transfer depends on the capabilities learned during pre-training, and that our intervention amplifies latent capabilities by sharpening the output distribution toward successful reasoning trajectories.
OckBench: Measuring the Efficiency of LLM Reasoning
Nov 07, 2025Large language models such as GPT-4, Claude 3, and the Gemini series have improved automated reasoning and code generation. However, existing benchmarks mainly focus on accuracy and output quality, and they ignore an important factor: decoding token efficiency. In real systems, generating 10,000 tokens versus 100,000 tokens leads to large differences in latency, cost, and energy. In this work, we introduce OckBench, a model-agnostic and hardware-agnostic benchmark that evaluates both accuracy and token count for reasoning and coding tasks. Through experiments comparing multiple open- and closed-source models, we uncover that many models with comparable accuracy differ wildly in token consumption, revealing that efficiency variance is a neglected but significant axis of differentiation. We further demonstrate Pareto frontiers over the accuracy-efficiency plane and argue for an evaluation paradigm shift: we should no longer treat tokens as "free" to multiply. OckBench provides a unified platform for measuring, comparing, and guiding research in token-efficient reasoning. Our benchmarks are available at https://ockbench.github.io/ .
MixGCN: Scalable GCN Training by Mixture of Parallelism and Mixture of Accelerators
Jan 06, 2025



Graph convolutional networks (GCNs) have demonstrated superiority in graph-based learning tasks. However, training GCNs on full graphs is particularly challenging, due to the following two challenges: (1) the associated feature tensors can easily explode the memory and block the communication bandwidth of modern accelerators, and (2) the computation workflow in training GCNs alternates between sparse and dense matrix operations, complicating the efficient utilization of computational resources. Existing solutions for scalable distributed full-graph GCN training mostly adopt partition parallelism, which is unsatisfactory as they only partially address the first challenge while incurring scaled-out communication volume. To this end, we propose MixGCN aiming to simultaneously address both the aforementioned challenges towards GCN training. To tackle the first challenge, MixGCN integrates mixture of parallelism. Both theoretical and empirical analysis verify its constant communication volumes and enhanced balanced workload; For handling the second challenge, we consider mixture of accelerators (i.e., sparse and dense accelerators) with a dedicated accelerator for GCN training and a fine-grain pipeline. Extensive experiments show that MixGCN achieves boosted training efficiency and scalability.
Efficient Toxic Content Detection by Bootstrapping and Distilling Large Language Models
Dec 13, 2023Toxic content detection is crucial for online services to remove inappropriate content that violates community standards. To automate the detection process, prior works have proposed varieties of machine learning (ML) approaches to train Language Models (LMs) for toxic content detection. However, both their accuracy and transferability across datasets are limited. Recently, Large Language Models (LLMs) have shown promise in toxic content detection due to their superior zero-shot and few-shot in-context learning ability as well as broad transferability on ML tasks. However, efficiently designing prompts for LLMs remains challenging. Moreover, the high run-time cost of LLMs may hinder their deployments in production. To address these challenges, in this work, we propose BD-LLM, a novel and efficient approach to Bootstrapping and Distilling LLMs for toxic content detection. Specifically, we design a novel prompting method named Decision-Tree-of-Thought (DToT) to bootstrap LLMs' detection performance and extract high-quality rationales. DToT can automatically select more fine-grained context to re-prompt LLMs when their responses lack confidence. Additionally, we use the rationales extracted via DToT to fine-tune student LMs. Our experimental results on various datasets demonstrate that DToT can improve the accuracy of LLMs by up to 4.6%. Furthermore, student LMs fine-tuned with rationales extracted via DToT outperform baselines on all datasets with up to 16.9\% accuracy improvement, while being more than 60x smaller than conventional LLMs. Finally, we observe that student LMs fine-tuned with rationales exhibit better cross-dataset transferability.
Human Transcription Quality Improvement
Sep 24, 2023High quality transcription data is crucial for training automatic speech recognition (ASR) systems. However, the existing industry-level data collection pipelines are expensive to researchers, while the quality of crowdsourced transcription is low. In this paper, we propose a reliable method to collect speech transcriptions. We introduce two mechanisms to improve transcription quality: confidence estimation based reprocessing at labeling stage, and automatic word error correction at post-labeling stage. We collect and release LibriCrowd - a large-scale crowdsourced dataset of audio transcriptions on 100 hours of English speech. Experiment shows the Transcription WER is reduced by over 50%. We further investigate the impact of transcription error on ASR model performance and found a strong correlation. The transcription quality improvement provides over 10% relative WER reduction for ASR models. We release the dataset and code to benefit the research community.
* 5 pages, 3 figures, 5 tables, INTERSPEECH 2023
HTEC: Human Transcription Error Correction
Sep 18, 2023



High-quality human transcription is essential for training and improving Automatic Speech Recognition (ASR) models. Recent study~\cite{libricrowd} has found that every 1% worse transcription Word Error Rate (WER) increases approximately 2% ASR WER by using the transcriptions to train ASR models. Transcription errors are inevitable for even highly-trained annotators. However, few studies have explored human transcription correction. Error correction methods for other problems, such as ASR error correction and grammatical error correction, do not perform sufficiently for this problem. Therefore, we propose HTEC for Human Transcription Error Correction. HTEC consists of two stages: Trans-Checker, an error detection model that predicts and masks erroneous words, and Trans-Filler, a sequence-to-sequence generative model that fills masked positions. We propose a holistic list of correction operations, including four novel operations handling deletion errors. We further propose a variant of embeddings that incorporates phoneme information into the input of the transformer. HTEC outperforms other methods by a large margin and surpasses human annotators by 2.2% to 4.5% in WER. Finally, we deployed HTEC to assist human annotators and showed HTEC is particularly effective as a co-pilot, which improves transcription quality by 15.1% without sacrificing transcription velocity.
APAM: Adaptive Pre-training and Adaptive Meta Learning in Language Model for Noisy Labels and Long-tailed Learning
Feb 06, 2023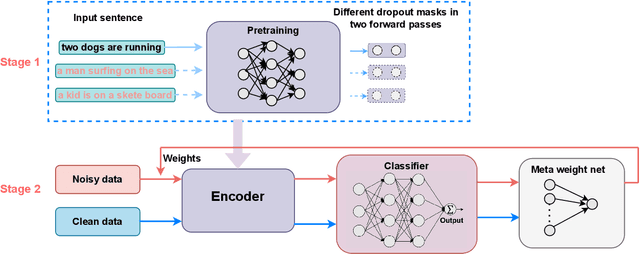



Practical natural language processing (NLP) tasks are commonly long-tailed with noisy labels. Those problems challenge the generalization and robustness of complex models such as Deep Neural Networks (DNNs). Some commonly used resampling techniques, such as oversampling or undersampling, could easily lead to overfitting. It is growing popular to learn the data weights leveraging a small amount of metadata. Besides, recent studies have shown the advantages of self-supervised pre-training, particularly to the under-represented data. In this work, we propose a general framework to handle the problem of both long-tail and noisy labels. The model is adapted to the domain of problems in a contrastive learning manner. The re-weighting module is a feed-forward network that learns explicit weighting functions and adapts weights according to metadata. The framework further adapts weights of terms in the loss function through a combination of the polynomial expansion of cross-entropy loss and focal loss. Our extensive experiments show that the proposed framework consistently outperforms baseline methods. Lastly, our sensitive analysis emphasizes the capability of the proposed framework to handle the long-tailed problem and mitigate the negative impact of noisy labels.