 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI in Embodied Systems: System-Level Analysis of Performance, Efficiency and Scalability
Apr 26, 2025Embodied systems, where generative autonomous agents engage with the physical world through integrated perception, cognition, action, and advanced reasoning powered by large language models (LLMs), hold immense potential for addressing complex, long-horizon, multi-objective tasks in real-world environments. However, deploying these systems remains challenging due to prolonged runtime latency, limited scalability, and heightened sensitivity, leading to significant system inefficiencies. In this paper, we aim to understand the workload characteristics of embodied agent systems and explore optimization solutions. We systematically categorize these systems into four paradigms and conduct benchmarking studies to evaluate their task performance and system efficiency across various modules, agent scales, and embodied tasks. Our benchmarking studies uncover critical challenges, such as prolonged planning and communication latency, redundant agent interactions, complex low-level control mechanisms, memory inconsistencies, exploding prompt lengths, sensitivity to self-correction and execution, sharp declines in success rates, and reduced collaboration efficiency as agent numbers increase. Leveraging these profiling insights, we suggest system optimization strategies to improve the performance, efficiency, and scalability of embodied agents across different paradigms. This paper presents the first system-level analysis of embodied AI agents, and explores opportunities for advancing future embodied system design.
MixGCN: Scalable GCN Training by Mixture of Parallelism and Mixture of Accelerators
Jan 06, 2025



Graph convolutional networks (GCNs) have demonstrated superiority in graph-based learning tasks. However, training GCNs on full graphs is particularly challenging, due to the following two challenges: (1) the associated feature tensors can easily explode the memory and block the communication bandwidth of modern accelerators, and (2) the computation workflow in training GCNs alternates between sparse and dense matrix operations, complicating the efficient utilization of computational resources. Existing solutions for scalable distributed full-graph GCN training mostly adopt partition parallelism, which is unsatisfactory as they only partially address the first challenge while incurring scaled-out communication volume. To this end, we propose MixGCN aiming to simultaneously address both the aforementioned challenges towards GCN training. To tackle the first challenge, MixGCN integrates mixture of parallelism. Both theoretical and empirical analysis verify its constant communication volumes and enhanced balanced workload; For handling the second challenge, we consider mixture of accelerators (i.e., sparse and dense accelerators) with a dedicated accelerator for GCN training and a fine-grain pipeline. Extensive experiments show that MixGCN achieves boosted training efficiency and scalability.
EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge Devices via Layerwise Unified Compression and Adaptive Layer Tuning and Voting
Jun 22, 2024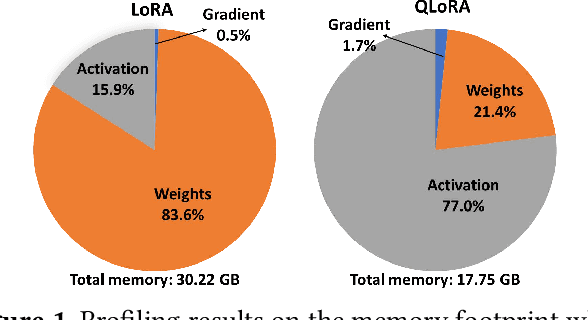
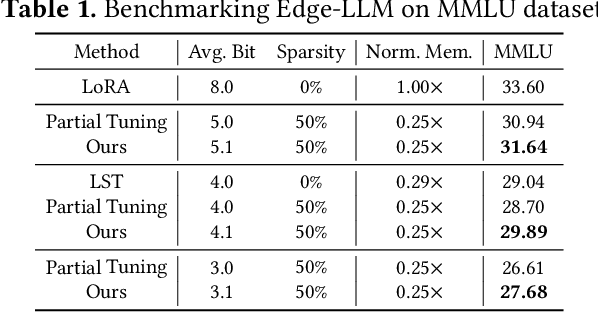
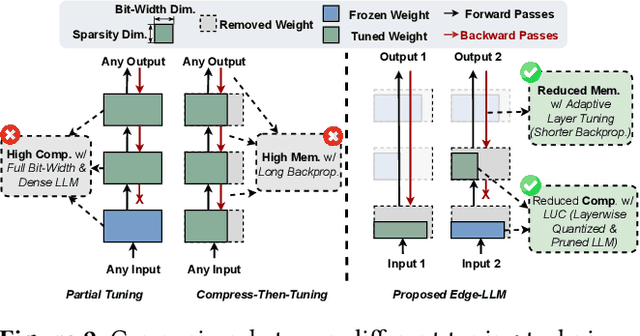
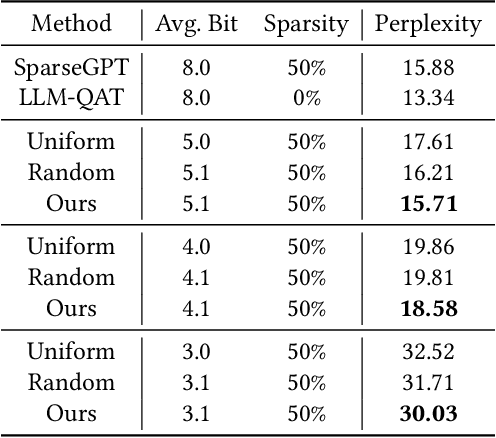
Efficient adaption of large language models (LLMs) on edge devices is essential for applications requiring continuous and privacy-preserving adaptation and inference. However, existing tuning techniques fall short because of the high computation and memory overheads. To this end, we introduce a computation- and memory-efficient LLM tuning framework, called Edge-LLM, to facilitate affordable and effective LLM adaptation on edge devices. Specifically, Edge-LLM features three core components: (1) a layer-wise unified compression (LUC) technique to reduce the computation overhead by generating layer-wise pruning sparsity and quantization bit-width policies, (2) an adaptive layer tuning and voting scheme to reduce the memory overhead by reducing the backpropagation depth, and (3) a complementary hardware scheduling strategy to handle the irregular computation patterns introduced by LUC and adaptive layer tuning, thereby achieving efficient computation and data movements. Extensive experiments demonstrate that Edge-LLM achieves a 2.92x speed up and a 4x memory overhead reduction as compared to vanilla tuning methods with comparable task accuracy. Our code is available at https://github.com/GATECH-EIC/Edge-LLM