 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAI for Systems: Recurring Challenges and Design Principles from Software to Silicon
Feb 16, 2026Generative AI is reshaping how computing systems are designed, optimized, and built, yet research remains fragmented across software, architecture, and chip design communities. This paper takes a cross-stack perspective, examining how generative models are being applied from code generation and distributed runtimes through hardware design space exploration to RTL synthesis, physical layout, and verification. Rather than reviewing each layer in isolation, we analyze how the same structural difficulties and effective responses recur across the stack. Our central finding is one of convergence. Despite the diversity of domains and tools, the field keeps encountering five recurring challenges (the feedback loop crisis, the tacit knowledge problem, trust and validation, co-design across boundaries, and the shift from determinism to dynamism) and keeps arriving at five design principles that independently emerge as effective responses (embracing hybrid approaches, designing for continuous feedback, separating concerns by role, matching methods to problem structure, and building on decades of systems knowledge). We organize these into a challenge--principle map that serves as a diagnostic and design aid, showing which principles have proven effective for which challenges across layers. Through concrete cross-stack examples, we show how systems navigate this map as they mature, and argue that the field needs shared engineering methodology, including common vocabularies, cross-layer benchmarks, and systematic design practices, so that progress compounds across communities rather than being rediscovered in each one. Our analysis covers more than 275 papers spanning eleven application areas across three layers of the computing stack, and distills open research questions that become visible only from a cross-layer vantage point.
REASON: Accelerating Probabilistic Logical Reasoning for Scalable Neuro-Symbolic Intelligence
Jan 28, 2026Neuro-symbolic AI systems integrate neural perception with symbolic reasoning to enable data-efficient, interpretable, and robust intelligence beyond purely neural models. Although this compositional paradigm has shown superior performance in domains such as reasoning, planning, and verification, its deployment remains challenging due to severe inefficiencies in symbolic and probabilistic inference. Through systematic analysis of representative neuro-symbolic workloads, we identify probabilistic logical reasoning as the inefficiency bottleneck, characterized by irregular control flow, low arithmetic intensity, uncoalesced memory accesses, and poor hardware utilization on CPUs and GPUs. This paper presents REASON, an integrated acceleration framework for probabilistic logical reasoning in neuro-symbolic AI. REASON introduces a unified directed acyclic graph representation that captures common structure across symbolic and probabilistic models, coupled with adaptive pruning and regularization. At the architecture level, REASON features a reconfigurable, tree-based processing fabric optimized for irregular traversal, symbolic deduction, and probabilistic aggregation. At the system level, REASON is tightly integrated with GPU streaming multiprocessors through a programmable interface and multi-level pipeline that efficiently orchestrates compositional execution. Evaluated across six neuro-symbolic workloads, REASON achieves 12-50x speedup and 310-681x energy efficiency over desktop and edge GPUs under TSMC 28 nm node. REASON enables real-time probabilistic logical reasoning, completing end-to-end tasks in 0.8 s with 6 mm2 area and 2.12 W power, demonstrating that targeted acceleration of probabilistic logical reasoning is critical for practical and scalable neuro-symbolic AI and positioning REASON as a foundational system architecture for next-generation cognitive intelligence.
Efficient Mixture-of-Agents Serving via Tree-Structured Routing, Adaptive Pruning, and Dependency-Aware Prefill-Decode Overlap
Dec 19, 2025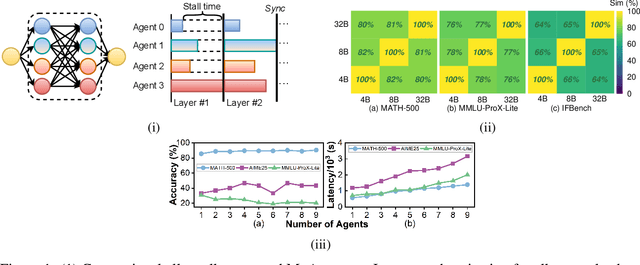
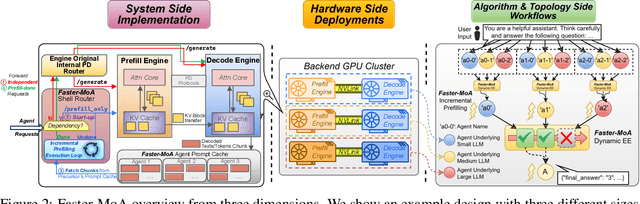
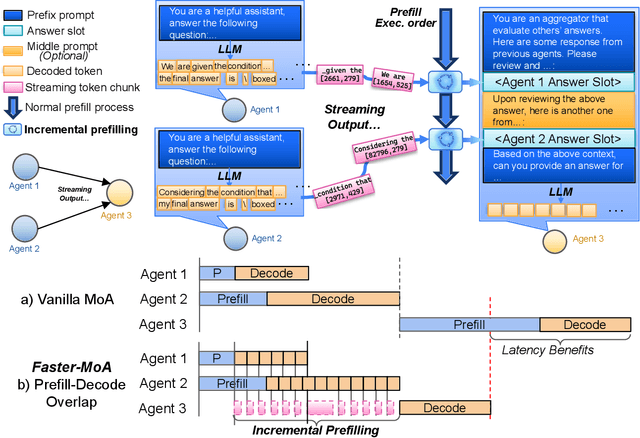
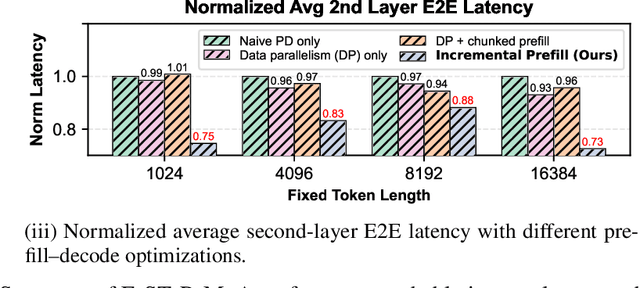
Mixture-of-Agents (MoA) inference can suffer from dense inter-agent communication and low hardware utilization, which jointly inflate serving latency. We present a serving design that targets these bottlenecks through an algorithm-system co-design. First, we replace dense agent interaction graphs with a hierarchical tree topology that induces structured sparsity in inter-agent communication. Second, we introduce a runtime adaptive mechanism that selectively terminates or skips downstream agent invocations using semantic agreement and confidence signals from intermediate outputs. Third, we pipeline agent execution by overlapping incremental prefilling with decoding across dependency-related agents, improving utilization and reducing inference latency. Across representative tasks, this approach substantially reduces end-to-end latency (up to 90%) while maintaining comparable accuracy (within $\pm$1%) relative to dense-connectivity MoA baselines, and can improve accuracy in certain settings.
Slm-mux: Orchestrating small language models for reasoning
Oct 06, 2025With the rapid development of language models, the number of small language models (SLMs) has grown significantly. Although they do not achieve state-of-the-art accuracy, they are more efficient and often excel at specific tasks. This raises a natural question: can multiple SLMs be orchestrated into a system where each contributes effectively, achieving higher accuracy than any individual model? Existing orchestration methods have primarily targeted frontier models (e.g., GPT-4) and perform suboptimally when applied to SLMs. To address this gap, we propose a three-stage approach for orchestrating SLMs. First, we introduce SLM-MUX, a multi-model architecture that effectively coordinates multiple SLMs. Building on this, we develop two optimization strategies: (i) a model selection search that identifies the most complementary SLMs from a given pool, and (ii) test-time scaling tailored to SLM-MUX. Our approach delivers strong results: Compared to existing orchestration methods, our approach achieves up to 13.4% improvement on MATH, 8.8% on GPQA, and 7.0% on GSM8K. With just two SLMS, SLM-MUX outperforms Qwen 2.5 72B on GPQA and GSM8K, and matches its performance on MATH. We further provide theoretical analyses to substantiate the advantages of our method. In summary, we demonstrate that SLMs can be effectively orchestrated into more accurate and efficient systems through the proposed approach.
ANNIE: Be Careful of Your Robots
Sep 03, 2025



The integration of vision-language-action (VLA) models into embodied AI (EAI) robots is rapidly advancing their ability to perform complex, long-horizon tasks in humancentric environments. However, EAI systems introduce critical security risks: a compromised VLA model can directly translate adversarial perturbations on sensory input into unsafe physical actions. Traditional safety definitions and methodologies from the machine learning community are no longer sufficient. EAI systems raise new questions, such as what constitutes safety, how to measure it, and how to design effective attack and defense mechanisms in physically grounded, interactive settings. In this work, we present the first systematic study of adversarial safety attacks on embodied AI systems, grounded in ISO standards for human-robot interactions. We (1) formalize a principled taxonomy of safety violations (critical, dangerous, risky) based on physical constraints such as separation distance, velocity, and collision boundaries; (2) introduce ANNIEBench, a benchmark of nine safety-critical scenarios with 2,400 video-action sequences for evaluating embodied safety; and (3) ANNIE-Attack, a task-aware adversarial framework with an attack leader model that decomposes long-horizon goals into frame-level perturbations. Our evaluation across representative EAI models shows attack success rates exceeding 50% across all safety categories. We further demonstrate sparse and adaptive attack strategies and validate the real-world impact through physical robot experiments. These results expose a previously underexplored but highly consequential attack surface in embodied AI systems, highlighting the urgent need for security-driven defenses in the physical AI era. Code is available at https://github.com/RLCLab/Annie.
NSFlow: An End-to-End FPGA Framework with Scalable Dataflow Architecture for Neuro-Symbolic AI
Apr 29, 2025Neuro-Symbolic AI (NSAI) is an emerging paradigm that integrates neural networks with symbolic reasoning to enhance the transparency, reasoning capabilities, and data efficiency of AI systems. Recent NSAI systems have gained traction due to their exceptional performance in reasoning tasks and human-AI collaborative scenarios. Despite these algorithmic advancements, executing NSAI tasks on existing hardware (e.g., CPUs, GPUs, TPUs) remains challenging, due to their heterogeneous computing kernels, high memory intensity, and unique memory access patterns. Moreover, current NSAI algorithms exhibit significant variation in operation types and scales, making them incompatible with existing ML accelerators. These challenges highlight the need for a versatile and flexible acceleration framework tailored to NSAI workloads. In this paper, we propose NSFlow, an FPGA-based acceleration framework designed to achieve high efficiency, scalability, and versatility across NSAI systems. NSFlow features a design architecture generator that identifies workload data dependencies and creates optimized dataflow architectures, as well as a reconfigurable array with flexible compute units, re-organizable memory, and mixed-precision capabilities. Evaluating across NSAI workloads, NSFlow achieves 31x speedup over Jetson TX2, more than 2x over GPU, 8x speedup over TPU-like systolic array, and more than 3x over Xilinx DPU. NSFlow also demonstrates enhanced scalability, with only 4x runtime increase when symbolic workloads scale by 150x. To the best of our knowledge, NSFlow is the first framework to enable real-time generalizable NSAI algorithms acceleration, demonstrating a promising solution for next-generation cognitive systems.
Generative AI in Embodied Systems: System-Level Analysis of Performance, Efficiency and Scalability
Apr 26, 2025Embodied systems, where generative autonomous agents engage with the physical world through integrated perception, cognition, action, and advanced reasoning powered by large language models (LLMs), hold immense potential for addressing complex, long-horizon, multi-objective tasks in real-world environments. However, deploying these systems remains challenging due to prolonged runtime latency, limited scalability, and heightened sensitivity, leading to significant system inefficiencies. In this paper, we aim to understand the workload characteristics of embodied agent systems and explore optimization solutions. We systematically categorize these systems into four paradigms and conduct benchmarking studies to evaluate their task performance and system efficiency across various modules, agent scales, and embodied tasks. Our benchmarking studies uncover critical challenges, such as prolonged planning and communication latency, redundant agent interactions, complex low-level control mechanisms, memory inconsistencies, exploding prompt lengths, sensitivity to self-correction and execution, sharp declines in success rates, and reduced collaboration efficiency as agent numbers increase. Leveraging these profiling insights, we suggest system optimization strategies to improve the performance, efficiency, and scalability of embodied agents across different paradigms. This paper presents the first system-level analysis of embodied AI agents, and explores opportunities for advancing future embodied system design.
ADDT -- A Digital Twin Framework for Proactive Safety Validation in Autonomous Driving Systems
Apr 13, 2025Autonomous driving systems continue to face safety-critical failures, often triggered by rare and unpredictable corner cases that evade conventional testing. We present the Autonomous Driving Digital Twin (ADDT) framework, a high-fidelity simulation platform designed to proactively identify hidden faults, evaluate real-time performance, and validate safety before deployment. ADDT combines realistic digital models of driving environments, vehicle dynamics, sensor behavior, and fault conditions to enable scalable, scenario-rich stress-testing under diverse and adverse conditions. It supports adaptive exploration of edge cases using reinforcement-driven techniques, uncovering failure modes that physical road testing often misses. By shifting from reactive debugging to proactive simulation-driven validation, ADDT enables a more rigorous and transparent approach to autonomous vehicle safety engineering. To accelerate adoption and facilitate industry-wide safety improvements, the entire ADDT framework has been released as open-source software, providing developers with an accessible and extensible tool for comprehensive safety testing at scale.
VAP: The Vulnerability-Adaptive Protection Paradigm Toward Reliable Autonomous Machines
Sep 30, 2024



The next ubiquitous computing platform, following personal computers and smartphones, is poised to be inherently autonomous, encompassing technologies like drones, robots, and self-driving cars. Ensuring reliability for these autonomous machines is critical. However, current resiliency solutions make fundamental trade-offs between reliability and cost, resulting in significant overhead in performance, energy consumption, and chip area. This is due to the "one-size-fits-all" approach commonly used, where the same protection scheme is applied throughout the entire software computing stack. This paper presents the key insight that to achieve high protection coverage with minimal cost, we must leverage the inherent variations in robustness across different layers of the autonomous machine software stack. Specifically, we demonstrate that various nodes in this complex stack exhibit different levels of robustness against hardware faults. Our findings reveal that the front-end of an autonomous machine's software stack tends to be more robust, whereas the back-end is generally more vulnerable. Building on these inherent robustness differences, we propose a Vulnerability-Adaptive Protection (VAP) design paradigm. In this paradigm, the allocation of protection resources - whether spatially (e.g., through modular redundancy) or temporally (e.g., via re-execution) - is made inversely proportional to the inherent robustness of tasks or algorithms within the autonomous machine system. Experimental results show that VAP provides high protection coverage while maintaining low overhead in both autonomous vehicle and drone systems.
H3DFact: Heterogeneous 3D Integrated CIM for Factorization with Holographic Perceptual Representations
Apr 05, 2024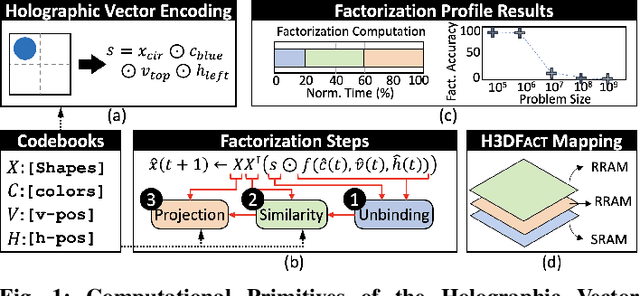
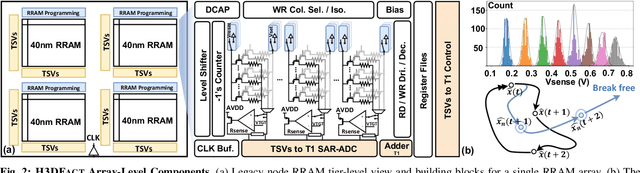
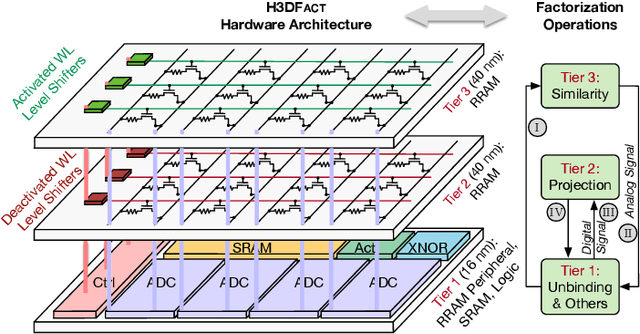
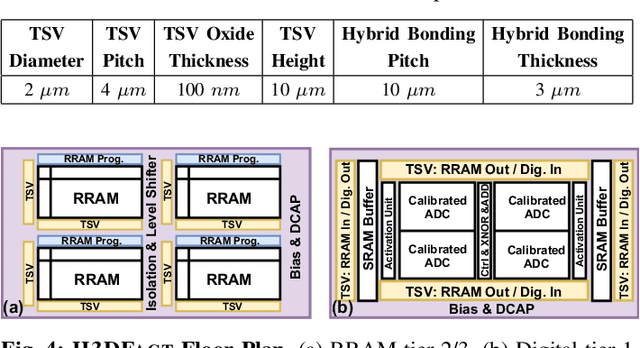
Disentangling attributes of various sensory signals is central to human-like perception and reasoning and a critical task for higher-order cognitive and neuro-symbolic AI systems. An elegant approach to represent this intricate factorization is via high-dimensional holographic vectors drawing on brain-inspired vector symbolic architectures. However, holographic factorization involves iterative computation with high-dimensional matrix-vector multiplications and suffers from non-convergence problems. In this paper, we present H3DFact, a heterogeneous 3D integrated in-memory compute engine capable of efficiently factorizing high-dimensional holographic representations. H3DFact exploits the computation-in-superposition capability of holographic vectors and the intrinsic stochasticity associated with memristive-based 3D compute-in-memory. Evaluated on large-scale factorization and perceptual problems, H3DFact demonstrates superior capability in factorization accuracy and operational capacity by up to five orders of magnitude, with 5.5x compute density, 1.2x energy efficiency improvements, and 5.9x less silicon footprint compared to iso-capacity 2D designs.