 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithm-Hardware Co-Design of Distribution-Aware Logarithmic-Posit Encodings for Efficient DNN Inference
Paper and Code
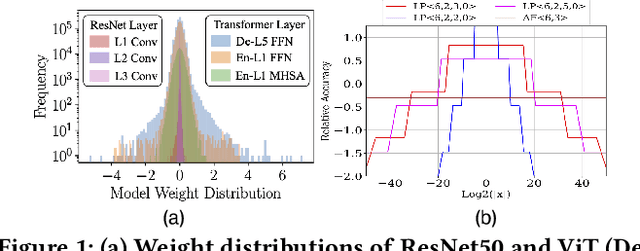

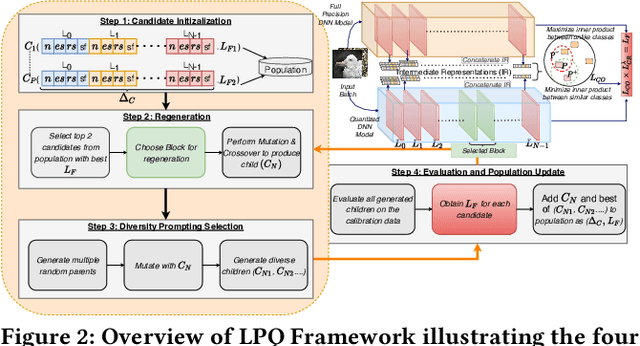
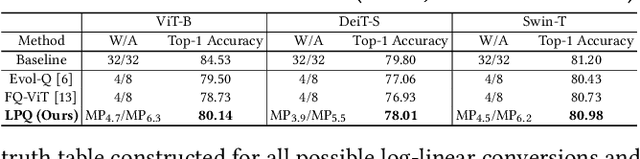
Traditional Deep Neural Network (DNN) quantization methods using integer, fixed-point, or floating-point data types struggle to capture diverse DNN parameter distributions at low precision, and often require large silicon overhead and intensive quantization-aware training. In this study, we introduce Logarithmic Posits (LP), an adaptive, hardware-friendly data type inspired by posits that dynamically adapts to DNN weight/activation distributions by parameterizing LP bit fields. We also develop a novel genetic-algorithm based framework, LP Quantization (LPQ), to find optimal layer-wise LP parameters while reducing representational divergence between quantized and full-precision models through a novel global-local contrastive objective. Additionally, we design a unified mixed-precision LP accelerator (LPA) architecture comprising of processing elements (PEs) incorporating LP in the computational datapath. Our algorithm-hardware co-design demonstrates on average <1% drop in top-1 accuracy across various CNN and ViT models. It also achieves ~ 2x improvements in performance per unit area and 2.2x gains in energy efficiency compared to state-of-the-art quantization accelerators using different data types.