 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePQV-Mobile: A Combined Pruning and Quantization Toolkit to Optimize Vision Transformers for Mobile Applications
Aug 15, 2024While Vision Transformers (ViTs) are extremely effective at computer vision tasks and are replacing convolutional neural networks as the new state-of-the-art, they are complex and memory-intensive models. In order to effectively run these models on resource-constrained mobile/edge systems, there is a need to not only compress these models but also to optimize them and convert them into deployment-friendly formats. To this end, this paper presents a combined pruning and quantization tool, called PQV-Mobile, to optimize vision transformers for mobile applications. The tool is able to support different types of structured pruning based on magnitude importance, Taylor importance, and Hessian importance. It also supports quantization from FP32 to FP16 and int8, targeting different mobile hardware backends. We demonstrate the capabilities of our tool and show important latency-memory-accuracy trade-offs for different amounts of pruning and int8 quantization with Facebook Data Efficient Image Transformer (DeiT) models. Our results show that even pruning a DeiT model by 9.375% and quantizing it to int8 from FP32 followed by optimizing for mobile applications, we find a latency reduction by 7.18X with a small accuracy loss of 2.24%. The tool is open source.
Scaling Compute Is Not All You Need for Adversarial Robustness
Dec 20, 2023The last six years have witnessed significant progress in adversarially robust deep learning. As evidenced by the CIFAR-10 dataset category in RobustBench benchmark, the accuracy under $\ell_\infty$ adversarial perturbations improved from 44\% in \citet{Madry2018Towards} to 71\% in \citet{peng2023robust}. Although impressive, existing state-of-the-art is still far from satisfactory. It is further observed that best-performing models are often very large models adversarially trained by industrial labs with significant computational budgets. In this paper, we aim to understand: ``how much longer can computing power drive adversarial robustness advances?" To answer this question, we derive \emph{scaling laws for adversarial robustness} which can be extrapolated in the future to provide an estimate of how much cost we would need to pay to reach a desired level of robustness. We show that increasing the FLOPs needed for adversarial training does not bring as much advantage as it does for standard training in terms of performance improvements. Moreover, we find that some of the top-performing techniques are difficult to exactly reproduce, suggesting that they are not robust enough for minor changes in the training setup. Our analysis also uncovers potentially worthwhile directions to pursue in future research. Finally, we make our benchmarking framework (built on top of \texttt{timm}~\citep{rw2019timm}) publicly available to facilitate future analysis in efficient robust deep learning.
Machine Learning-Enhanced Prediction of Surface Smoothness for Inertial Confinement Fusion Target Polishing Using Limited Data
Dec 16, 2023In Inertial Confinement Fusion (ICF) process, roughly a 2mm spherical shell made of high density carbon is used as target for laser beams, which compress and heat it to energy levels needed for high fusion yield. These shells are polished meticulously to meet the standards for a fusion shot. However, the polishing of these shells involves multiple stages, with each stage taking several hours. To make sure that the polishing process is advancing in the right direction, we are able to measure the shell surface roughness. This measurement, however, is very labor-intensive, time-consuming, and requires a human operator. We propose to use machine learning models that can predict surface roughness based on the data collected from a vibration sensor that is connected to the polisher. Such models can generate surface roughness of the shells in real-time, allowing the operator to make any necessary changes to the polishing for optimal result.
Real-Time Fully Unsupervised Domain Adaptation for Lane Detection in Autonomous Driving
Jun 29, 2023

While deep neural networks are being utilized heavily for autonomous driving, they need to be adapted to new unseen environmental conditions for which they were not trained. We focus on a safety critical application of lane detection, and propose a lightweight, fully unsupervised, real-time adaptation approach that only adapts the batch-normalization parameters of the model. We demonstrate that our technique can perform inference, followed by on-device adaptation, under a tight constraint of 30 FPS on Nvidia Jetson Orin. It shows similar accuracy (avg. of 92.19%) as a state-of-the-art semi-supervised adaptation algorithm but which does not support real-time adaptation.
Roofline Model for UAVs: A Bottleneck Analysis Tool for Onboard Compute Characterization of Autonomous Unmanned Aerial Vehicles
Apr 22, 2022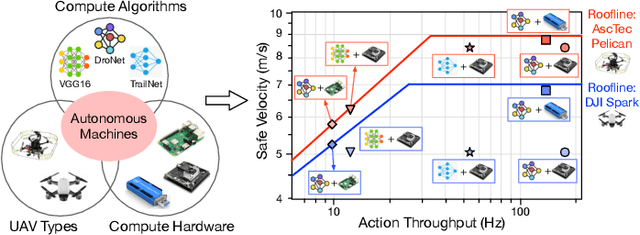
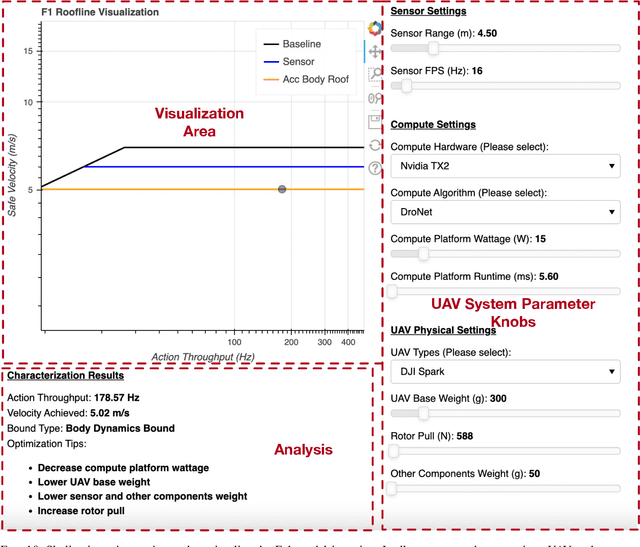
We introduce an early-phase bottleneck analysis and characterization model called the F-1 for designing computing systems that target autonomous Unmanned Aerial Vehicles (UAVs). The model provides insights by exploiting the fundamental relationships between various components in the autonomous UAV, such as sensor, compute, and body dynamics. To guarantee safe operation while maximizing the performance (e.g., velocity) of the UAV, the compute, sensor, and other mechanical properties must be carefully selected or designed. The F-1 model provides visual insights that can aid a system architect in understanding the optimal compute design or selection for autonomous UAVs. The model is experimentally validated using real UAVs, and the error is between 5.1\% to 9.5\% compared to real-world flight tests. An interactive web-based tool for the F-1 model called Skyline is available for free of cost use at: ~\url{https://bit.ly/skyline-tool}
Benchmarking Test-Time Unsupervised Deep Neural Network Adaptation on Edge Devices
Mar 21, 2022
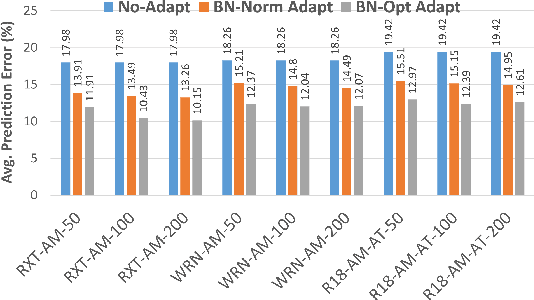
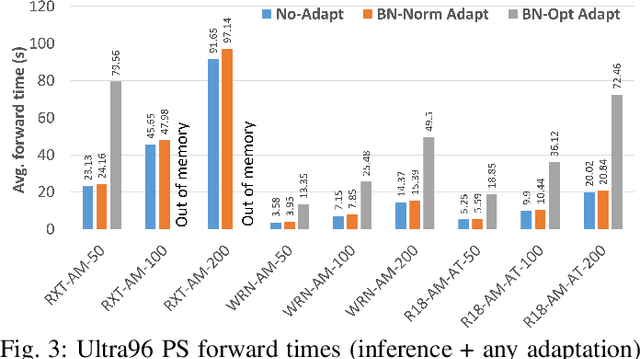
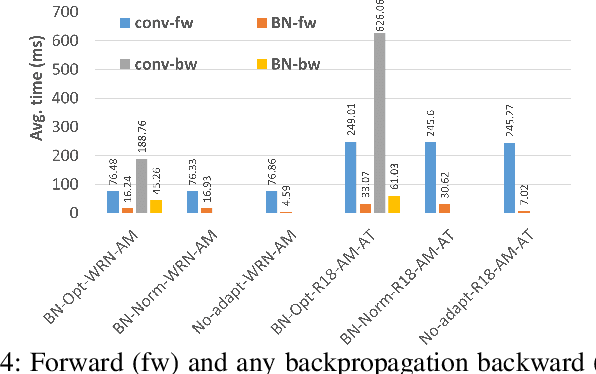
The prediction accuracy of the deep neural networks (DNNs) after deployment at the edge can suffer with time due to shifts in the distribution of the new data. To improve robustness of DNNs, they must be able to update themselves to enhance their prediction accuracy. This adaptation at the resource-constrained edge is challenging as: (i) new labeled data may not be present; (ii) adaptation needs to be on device as connections to cloud may not be available; and (iii) the process must not only be fast but also memory- and energy-efficient. Recently, lightweight prediction-time unsupervised DNN adaptation techniques have been introduced that improve prediction accuracy of the models for noisy data by re-tuning the batch normalization (BN) parameters. This paper, for the first time, performs a comprehensive measurement study of such techniques to quantify their performance and energy on various edge devices as well as find bottlenecks and propose optimization opportunities. In particular, this study considers CIFAR-10-C image classification dataset with corruptions, three robust DNNs (ResNeXt, Wide-ResNet, ResNet-18), two BN adaptation algorithms (one that updates normalization statistics and the other that also optimizes transformation parameters), and three edge devices (FPGA, Raspberry-Pi, and Nvidia Xavier NX). We find that the approach that only updates the normalization parameters with Wide-ResNet, running on Xavier GPU, to be overall effective in terms of balancing multiple cost metrics. However, the adaptation overhead can still be significant (around 213 ms). The results strongly motivate the need for algorithm-hardware co-design for efficient on-device DNN adaptation.
Roofline Model for UAVs:A Bottleneck Analysis Tool for Designing Compute Systems for Autonomous Drones
Nov 13, 2021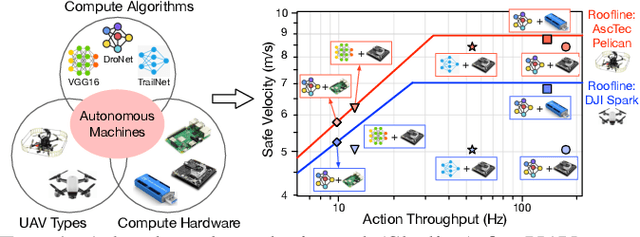
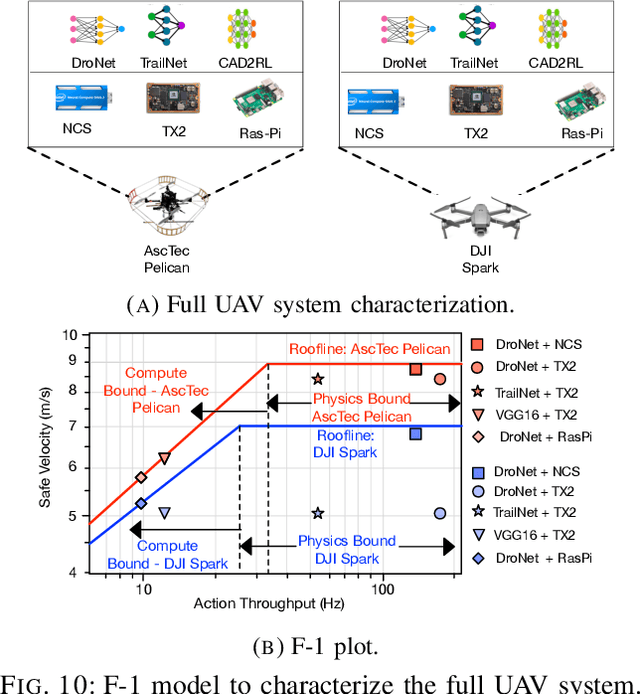


We present a bottleneck analysis tool for designing compute systems for autonomous Unmanned Aerial Vehicles (UAV). The tool provides insights by exploiting the fundamental relationships between various components in the autonomous UAV such as sensor, compute, body dynamics. To guarantee safe operation while maximizing the performance (e.g., velocity) of the UAV, the compute, sensor, and other mechanical properties must be carefully designed (or selected). The goal of our proposed tool is to provide a visual model which aids system architects to understand optimal compute design (or selection) for autonomous UAVs. The tool is available here:~\url{https://bit.ly/skyline-tool}
Semi-supervised on-device neural network adaptation for remote and portable laser-induced breakdown spectroscopy
Apr 08, 2021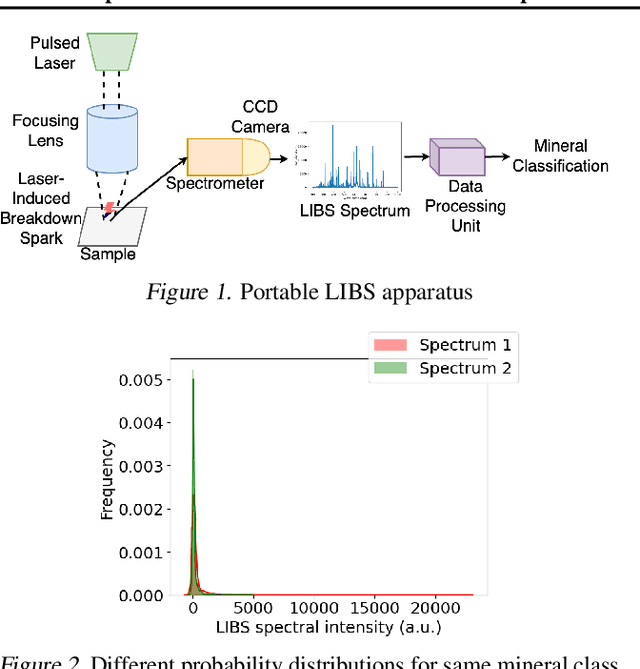
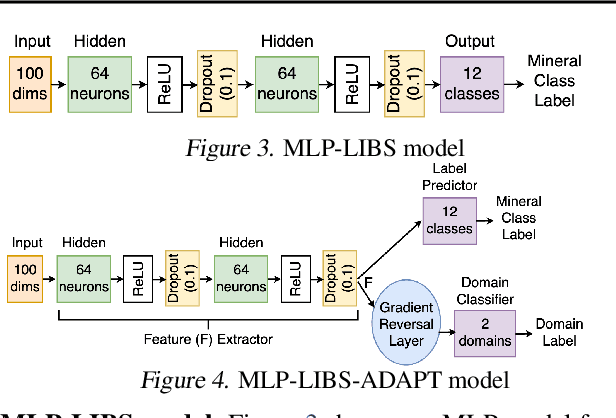
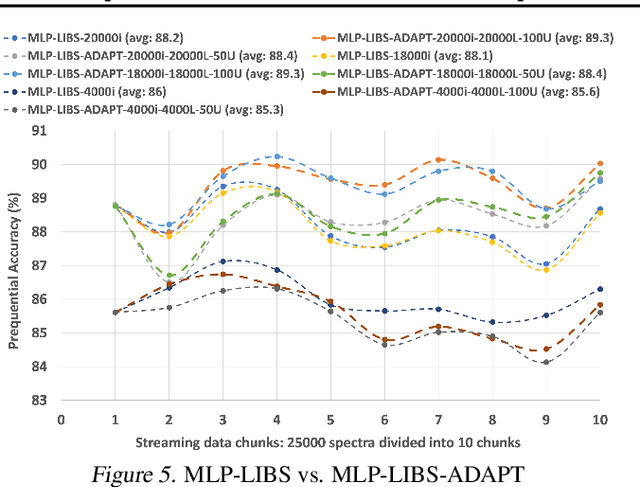
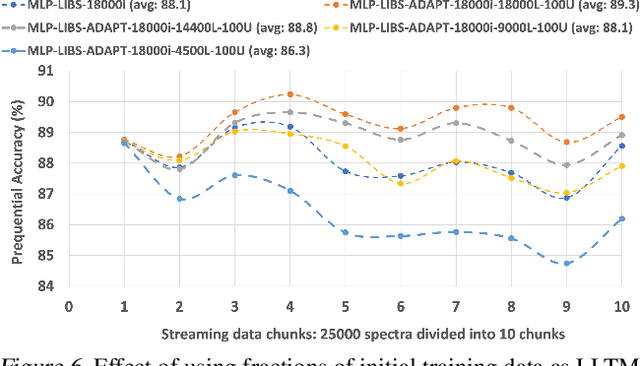
Laser-induced breakdown spectroscopy (LIBS) is a popular, fast elemental analysis technique used to determine the chemical composition of target samples, such as in industrial analysis of metals or in space exploration. Recently, there has been a rise in the use of machine learning (ML) techniques for LIBS data processing. However, ML for LIBS is challenging as: (i) the predictive models must be lightweight since they need to be deployed in highly resource-constrained and battery-operated portable LIBS systems; and (ii) since these systems can be remote, the models must be able to self-adapt to any domain shift in input distributions which could be due to the lack of different types of inputs in training data or dynamic environmental/sensor noise. This on-device retraining of model should not only be fast but also unsupervised due to the absence of new labeled data in remote LIBS systems. We introduce a lightweight multi-layer perceptron (MLP) model for LIBS that can be adapted on-device without requiring labels for new input data. It shows 89.3% average accuracy during data streaming, and up to 2.1% better accuracy compared to an MLP model that does not support adaptation. Finally, we also characterize the inference and retraining performance of our model on Google Pixel2 phone.
SMAUG: End-to-End Full-Stack Simulation Infrastructure for Deep Learning Workloads
Dec 11, 2019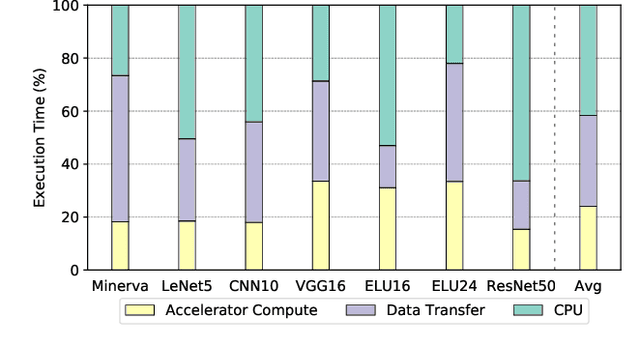
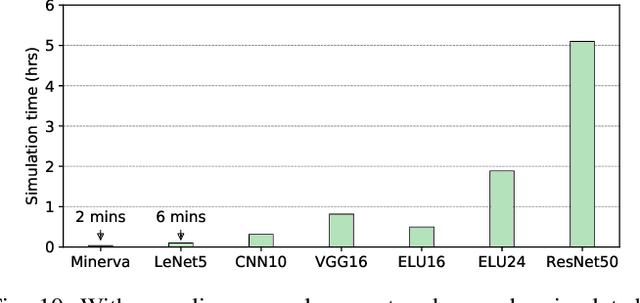
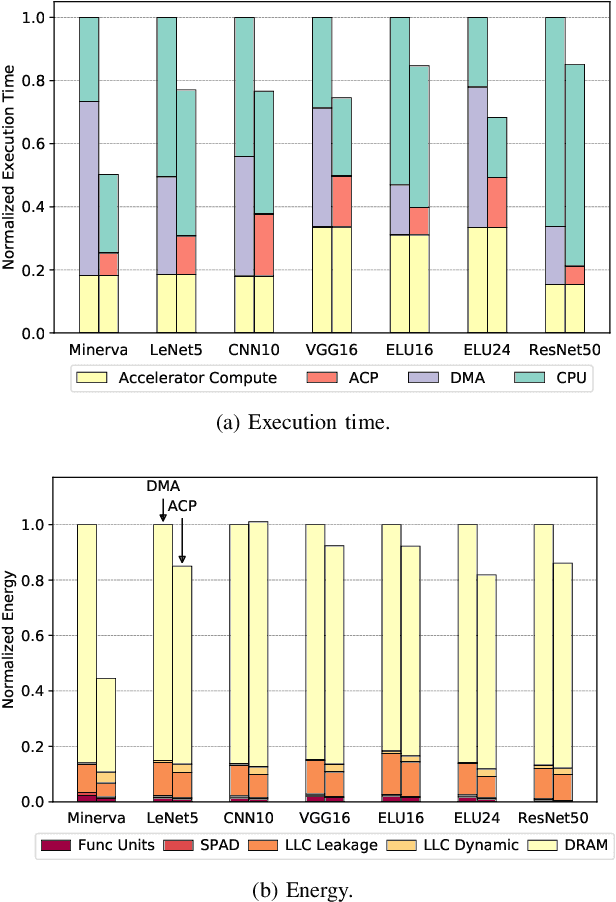
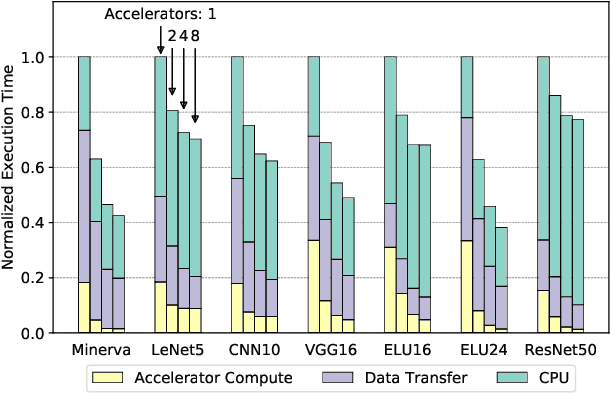
In recent years, there has been tremendous advances in hardware acceleration of deep neural networks. However, most of the research has focused on optimizing accelerator microarchitecture for higher performance and energy efficiency on a per-layer basis. We find that for overall single-batch inference latency, the accelerator may only make up 25-40%, with the rest spent on data movement and in the deep learning software framework. Thus far, it has been very difficult to study end-to-end DNN performance during early stage design (before RTL is available) because there are no existing DNN frameworks that support end-to-end simulation with easy custom hardware accelerator integration. To address this gap in research infrastructure, we present SMAUG, the first DNN framework that is purpose-built for simulation of end-to-end deep learning applications. SMAUG offers researchers a wide range of capabilities for evaluating DNN workloads, from diverse network topologies to easy accelerator modeling and SoC integration. To demonstrate the power and value of SMAUG, we present case studies that show how we can optimize overall performance and energy efficiency for up to 1.8-5x speedup over a baseline system, without changing any part of the accelerator microarchitecture, as well as show how SMAUG can tune an SoC for a camera-powered deep learning pipeline.