 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Energy Cost of Reasoning: Analyzing Energy Usage in LLMs with Test-time Compute
May 20, 2025Scaling large language models (LLMs) has driven significant advancements, yet it faces diminishing returns and escalating energy demands. This work introduces test-time compute (TTC)-allocating additional computational resources during inference-as a compelling complement to conventional scaling strategies. Specifically, we investigate whether employing TTC can achieve superior accuracy-energy trade-offs compared to simply increasing model size. Our empirical analysis reveals that TTC surpasses traditional model scaling in accuracy/energy efficiency, with notable gains in tasks demanding complex reasoning rather than mere factual recall. Further, we identify a critical interaction between TTC performance and output sequence length, demonstrating that strategically adjusting compute resources at inference time according to query complexity can substantially enhance efficiency. Our findings advocate for TTC as a promising direction, enabling more sustainable, accurate, and adaptable deployment of future language models without incurring additional pretraining costs.
FlexQuant: Elastic Quantization Framework for Locally Hosted LLM on Edge Devices
Jan 13, 2025



Deploying LLMs on edge devices presents serious technical challenges. Memory elasticity is crucial for edge devices with unified memory, where memory is shared and fluctuates dynamically. Existing solutions suffer from either poor transition granularity or high storage costs. We propose FlexQuant, a novel elasticity framework that generates an ensemble of quantized models, providing an elastic hosting solution with 15x granularity improvement and 10x storage reduction compared to SoTA methods. FlexQuant works with most quantization methods and creates a family of trade-off options under various storage limits through our pruning method. It brings great performance and flexibility to the edge deployment of LLMs.
Nanoscaling Floating-Point (NxFP): NanoMantissa, Adaptive Microexponents, and Code Recycling for Direct-Cast Compression of Large Language Models
Dec 15, 2024



As cutting-edge large language models (LLMs) continue to transform various industries, their fast-growing model size and sequence length have led to memory traffic and capacity challenges. Recently, AMD, Arm, Intel, Meta, Microsoft, NVIDIA, and Qualcomm have proposed a Microscaling standard (Mx), which augments block floating-point with microexponents to achieve promising perplexity-to-footprint trade-offs. However, the Microscaling suffers from significant perplexity degradation on modern LLMs with less than six bits. This paper profiles modern LLMs and identifies three main challenges of low-bit Microscaling format, i.e., inaccurate tracking of outliers, vacant quantization levels, and wasted binary code. In response, Nanoscaling (NxFP) proposes three techniques, i.e., NanoMantissa, Adaptive Microexponent, and Code Recycling to enable better accuracy and smaller memory footprint than state-of-the-art MxFP. Experimental results on direct-cast inference across various modern LLMs demonstrate that our proposed methods outperform state-of-the-art MxFP by up to 0.64 in perplexity and by up to 30% in accuracy on MMLU benchmarks. Furthermore, NxFP reduces memory footprint by up to 16% while achieving comparable perplexity as MxFP.
Carbon Connect: An Ecosystem for Sustainable Computing
May 22, 2024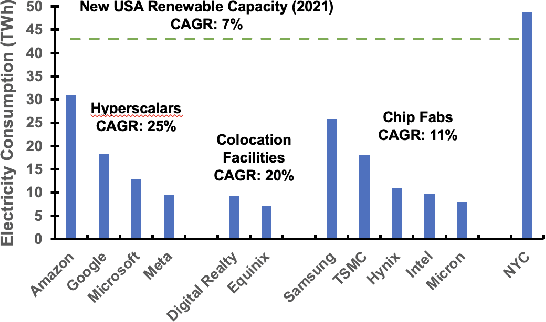
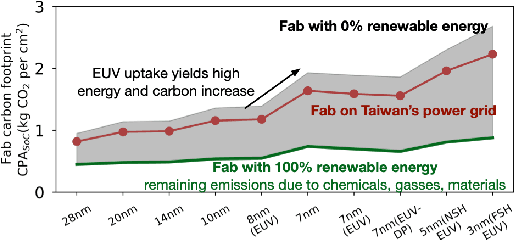
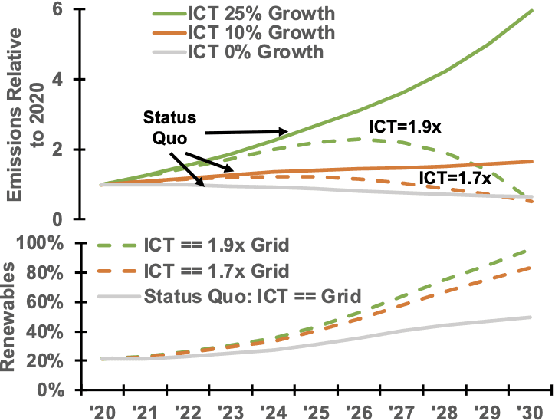
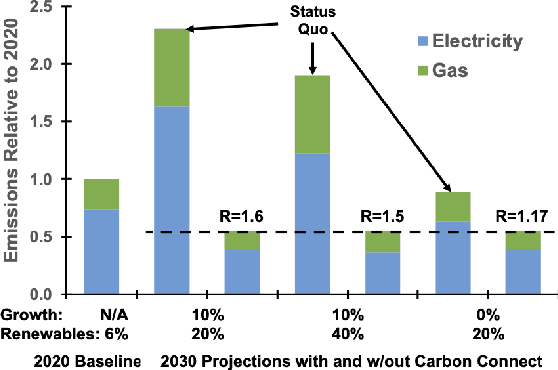
Computing is at a moment of profound opportunity. Emerging applications -- such as capable artificial intelligence, immersive virtual realities, and pervasive sensor systems -- drive unprecedented demand for computer. Despite recent advances toward net zero carbon emissions, the computing industry's gross energy usage continues to rise at an alarming rate, outpacing the growth of new energy installations and renewable energy deployments. A shift towards sustainability is needed to spark a transformation in how computer systems are manufactured, allocated, and consumed. Carbon Connect envisions coordinated research thrusts that produce design and management strategies for sustainable, next-generation computer systems. These strategies must flatten and then reverse growth trajectories for computing power and carbon for society's most rapidly growing applications such as artificial intelligence and virtual spaces. We will require accurate models for carbon accounting in computing technology. For embodied carbon, we must re-think conventional design strategies -- over-provisioned monolithic servers, frequent hardware refresh cycles, custom silicon -- and adopt life-cycle design strategies that more effectively reduce, reuse and recycle hardware at scale. For operational carbon, we must not only embrace renewable energy but also design systems to use that energy more efficiently. Finally, new hardware design and management strategies must be cognizant of economic policy and regulatory landscape, aligning private initiatives with societal goals. Many of these broader goals will require computer scientists to develop deep, enduring collaborations with researchers in economics, law, and industrial ecology to spark change in broader practice.
Is Flash Attention Stable?
May 05, 2024



Training large-scale machine learning models poses distinct system challenges, given both the size and complexity of today's workloads. Recently, many organizations training state-of-the-art Generative AI models have reported cases of instability during training, often taking the form of loss spikes. Numeric deviation has emerged as a potential cause of this training instability, although quantifying this is especially challenging given the costly nature of training runs. In this work, we develop a principled approach to understanding the effects of numeric deviation, and construct proxies to put observations into context when downstream effects are difficult to quantify. As a case study, we apply this framework to analyze the widely-adopted Flash Attention optimization. We find that Flash Attention sees roughly an order of magnitude more numeric deviation as compared to Baseline Attention at BF16 when measured during an isolated forward pass. We then use a data-driven analysis based on the Wasserstein Distance to provide upper bounds on how this numeric deviation impacts model weights during training, finding that the numerical deviation present in Flash Attention is 2-5 times less significant than low-precision training.
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Dec 22, 2023



As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
Hardware Resilience Properties of Text-Guided Image Classifiers
Dec 05, 2023



This paper presents a novel method to enhance the reliability of image classification models during deployment in the face of transient hardware errors. By utilizing enriched text embeddings derived from GPT-3 with question prompts per class and CLIP pretrained text encoder, we investigate their impact as an initialization for the classification layer. Our approach achieves a remarkable $5.5\times$ average increase in hardware reliability (and up to $14\times$) across various architectures in the most critical layer, with minimal accuracy drop ($0.3\%$ on average) compared to baseline PyTorch models. Furthermore, our method seamlessly integrates with any image classification backbone, showcases results across various network architectures, decreases parameter and FLOPs overhead, and follows a consistent training recipe. This research offers a practical and efficient solution to bolster the robustness of image classification models against hardware failures, with potential implications for future studies in this domain. Our code and models are released at https://github.com/TalalWasim/TextGuidedResilience.
MAD Max Beyond Single-Node: Enabling Large Machine Learning Model Acceleration on Distributed Systems
Oct 18, 2023Training and deploying large machine learning (ML) models is time-consuming and requires significant distributed computing infrastructures. Based on real-world large model training on datacenter-scale infrastructures, we show 14~32% of all GPU hours are spent on communication with no overlapping computation. To minimize the outstanding communication latency, in this work, we develop an agile performance modeling framework to guide parallelization and hardware-software co-design strategies. Using the suite of real-world large ML models on state-of-the-art GPU training hardware, we demonstrate 2.24x and 5.27x throughput improvement potential for pre-training and inference scenarios, respectively.
Guess & Sketch: Language Model Guided Transpilation
Sep 25, 2023



Maintaining legacy software requires many software and systems engineering hours. Assembly code programs, which demand low-level control over the computer machine state and have no variable names, are particularly difficult for humans to analyze. Existing conventional program translators guarantee correctness, but are hand-engineered for the source and target programming languages in question. Learned transpilation, i.e. automatic translation of code, offers an alternative to manual re-writing and engineering efforts. Automated symbolic program translation approaches guarantee correctness but struggle to scale to longer programs due to the exponentially large search space. Their rigid rule-based systems also limit their expressivity, so they can only reason about a reduced space of programs. Probabilistic neural language models (LMs) produce plausible outputs for every input, but do so at the cost of guaranteed correctness. In this work, we leverage the strengths of LMs and symbolic solvers in a neurosymbolic approach to learned transpilation for assembly code. Assembly code is an appropriate setting for a neurosymbolic approach, since assembly code can be divided into shorter non-branching basic blocks amenable to the use of symbolic methods. Guess & Sketch extracts alignment and confidence information from features of the LM then passes it to a symbolic solver to resolve semantic equivalence of the transpilation input and output. We test Guess & Sketch on three different test sets of assembly transpilation tasks, varying in difficulty, and show that it successfully transpiles 57.6% more examples than GPT-4 and 39.6% more examples than an engineered transpiler. We also share a training and evaluation dataset for this task.
Local primordial non-Gaussianity from the large-scale clustering of photometric DESI luminous red galaxies
Jul 04, 2023We use angular clustering of luminous red galaxies from the Dark Energy Spectroscopic Instrument (DESI) imaging surveys to constrain the local primordial non-Gaussianity parameter fNL. Our sample comprises over 12 million targets, covering 14,000 square degrees of the sky, with redshifts in the range 0.2< z < 1.35. We identify Galactic extinction, survey depth, and astronomical seeing as the primary sources of systematic error, and employ linear regression and artificial neural networks to alleviate non-cosmological excess clustering on large scales. Our methods are tested against log-normal simulations with and without fNL and systematics, showing superior performance of the neural network treatment in reducing remaining systematics. Assuming the universality relation, we find fNL $= 47^{+14(+29)}_{-11(-22)}$ at 68\%(95\%) confidence. With a more aggressive treatment, including regression against the full set of imaging maps, our maximum likelihood value shifts slightly to fNL$ \sim 50$ and the uncertainty on fNL increases due to the removal of large-scale clustering information. We apply a series of robustness tests (e.g., cuts on imaging, declination, or scales used) that show consistency in the obtained constraints. Despite extensive efforts to mitigate systematics, our measurements indicate fNL > 0 with a 99.9 percent confidence level. This outcome raises concerns as it could be attributed to unforeseen systematics, including calibration errors or uncertainties associated with low-\ell systematics in the extinction template. Alternatively, it could suggest a scale-dependent fNL model--causing significant non-Gaussianity around large-scale structure while leaving cosmic microwave background scales unaffected. Our results encourage further studies of fNL with DESI spectroscopic samples, where the inclusion of 3D clustering modes should help separate imaging systematics.