 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINT2.1: Towards Fine-Tunable Quantized Large Language Models with Error Correction through Low-Rank Adaptation
Jun 13, 2023



We introduce a method that dramatically reduces fine-tuning VRAM requirements and rectifies quantization errors in quantized Large Language Models. First, we develop an extremely memory-efficient fine-tuning (EMEF) method for quantized models using Low-Rank Adaptation (LoRA), and drawing upon it, we construct an error-correcting algorithm designed to minimize errors induced by the quantization process. Our method reduces the memory requirements by up to 5.6 times, which enables fine-tuning a 7 billion parameter Large Language Model (LLM) on consumer laptops. At the same time, we propose a Low-Rank Error Correction (LREC) method that exploits the added LoRA layers to ameliorate the gap between the quantized model and its float point counterpart. Our error correction framework leads to a fully functional INT2 quantized LLM with the capacity to generate coherent English text. To the best of our knowledge, this is the first INT2 Large Language Model that has been able to reach such a performance. The overhead of our method is merely a 1.05 times increase in model size, which translates to an effective precision of INT2.1. Also, our method readily generalizes to other quantization standards, such as INT3, INT4, and INT8, restoring their lost performance, which marks a significant milestone in the field of model quantization. The strategies delineated in this paper hold promising implications for the future development and optimization of quantized models, marking a pivotal shift in the landscape of low-resource machine learning computations.
Bigger&Faster: Two-stage Neural Architecture Search for Quantized Transformer Models
Sep 25, 2022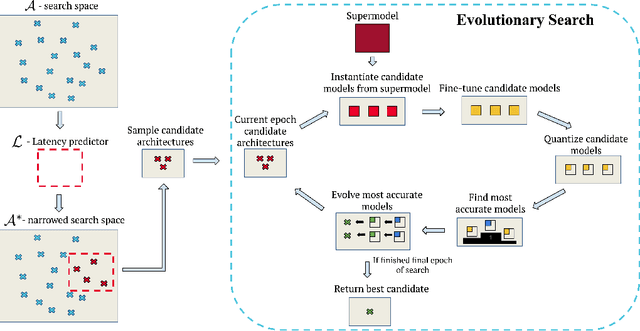

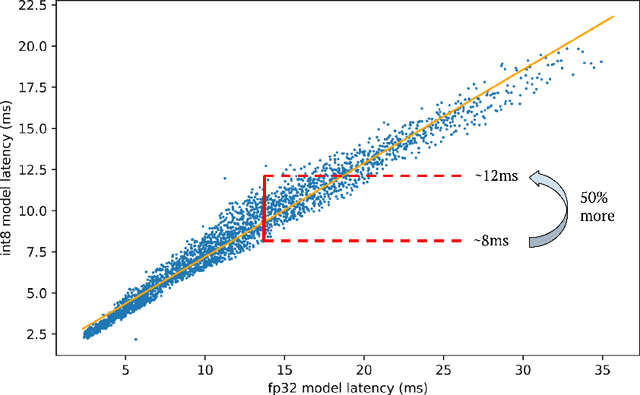
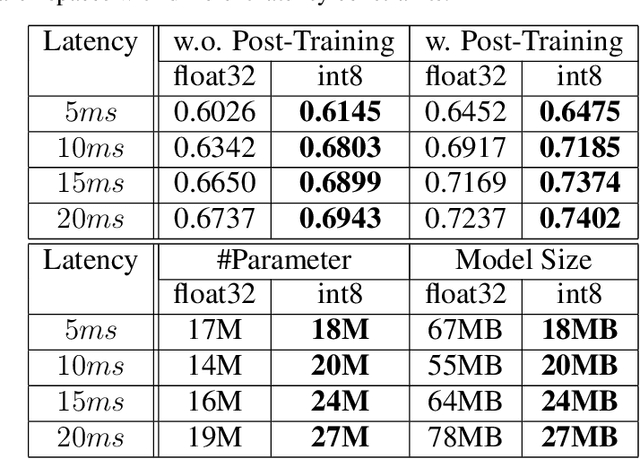
Neural architecture search (NAS) for transformers has been used to create state-of-the-art models that target certain latency constraints. In this work we present Bigger&Faster, a novel quantization-aware parameter sharing NAS that finds architectures for 8-bit integer (int8) quantized transformers. Our results show that our method is able to produce BERT models that outperform the current state-of-the-art technique, AutoTinyBERT, at all latency targets we tested, achieving up to a 2.68% accuracy gain. Additionally, although the models found by our technique have a larger number of parameters than their float32 counterparts, due to their parameters being int8, they have significantly smaller memory footprints.