 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexQuant: Elastic Quantization Framework for Locally Hosted LLM on Edge Devices
Jan 13, 2025



Deploying LLMs on edge devices presents serious technical challenges. Memory elasticity is crucial for edge devices with unified memory, where memory is shared and fluctuates dynamically. Existing solutions suffer from either poor transition granularity or high storage costs. We propose FlexQuant, a novel elasticity framework that generates an ensemble of quantized models, providing an elastic hosting solution with 15x granularity improvement and 10x storage reduction compared to SoTA methods. FlexQuant works with most quantization methods and creates a family of trade-off options under various storage limits through our pruning method. It brings great performance and flexibility to the edge deployment of LLMs.
INT2.1: Towards Fine-Tunable Quantized Large Language Models with Error Correction through Low-Rank Adaptation
Jun 13, 2023



We introduce a method that dramatically reduces fine-tuning VRAM requirements and rectifies quantization errors in quantized Large Language Models. First, we develop an extremely memory-efficient fine-tuning (EMEF) method for quantized models using Low-Rank Adaptation (LoRA), and drawing upon it, we construct an error-correcting algorithm designed to minimize errors induced by the quantization process. Our method reduces the memory requirements by up to 5.6 times, which enables fine-tuning a 7 billion parameter Large Language Model (LLM) on consumer laptops. At the same time, we propose a Low-Rank Error Correction (LREC) method that exploits the added LoRA layers to ameliorate the gap between the quantized model and its float point counterpart. Our error correction framework leads to a fully functional INT2 quantized LLM with the capacity to generate coherent English text. To the best of our knowledge, this is the first INT2 Large Language Model that has been able to reach such a performance. The overhead of our method is merely a 1.05 times increase in model size, which translates to an effective precision of INT2.1. Also, our method readily generalizes to other quantization standards, such as INT3, INT4, and INT8, restoring their lost performance, which marks a significant milestone in the field of model quantization. The strategies delineated in this paper hold promising implications for the future development and optimization of quantized models, marking a pivotal shift in the landscape of low-resource machine learning computations.
PerfSAGE: Generalized Inference Performance Predictor for Arbitrary Deep Learning Models on Edge Devices
Jan 26, 2023The ability to accurately predict deep neural network (DNN) inference performance metrics, such as latency, power, and memory footprint, for an arbitrary DNN on a target hardware platform is essential to the design of DNN based models. This ability is critical for the (manual or automatic) design, optimization, and deployment of practical DNNs for a specific hardware deployment platform. Unfortunately, these metrics are slow to evaluate using simulators (where available) and typically require measurement on the target hardware. This work describes PerfSAGE, a novel graph neural network (GNN) that predicts inference latency, energy, and memory footprint on an arbitrary DNN TFlite graph (TFL, 2017). In contrast, previously published performance predictors can only predict latency and are restricted to pre-defined construction rules or search spaces. This paper also describes the EdgeDLPerf dataset of 134,912 DNNs randomly sampled from four task search spaces and annotated with inference performance metrics from three edge hardware platforms. Using this dataset, we train PerfSAGE and provide experimental results that demonstrate state-of-the-art prediction accuracy with a Mean Absolute Percentage Error of <5% across all targets and model search spaces. These results: (1) Outperform previous state-of-art GNN-based predictors (Dudziak et al., 2020), (2) Accurately predict performance on accelerators (a shortfall of non-GNN-based predictors (Zhang et al., 2021)), and (3) Demonstrate predictions on arbitrary input graphs without modifications to the feature extractor.
Bigger&Faster: Two-stage Neural Architecture Search for Quantized Transformer Models
Sep 25, 2022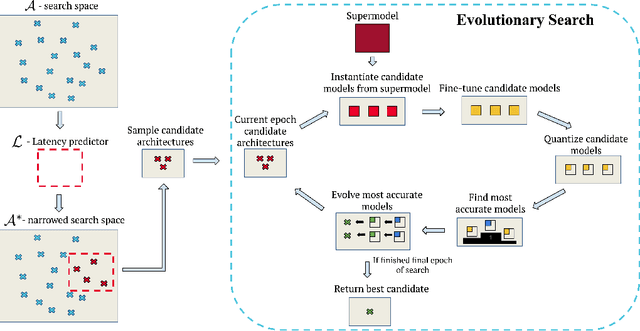

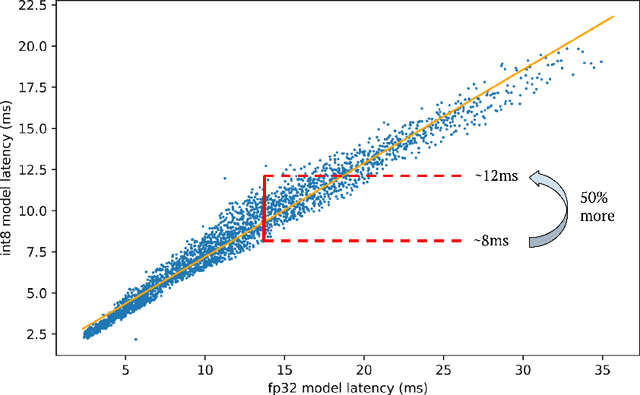
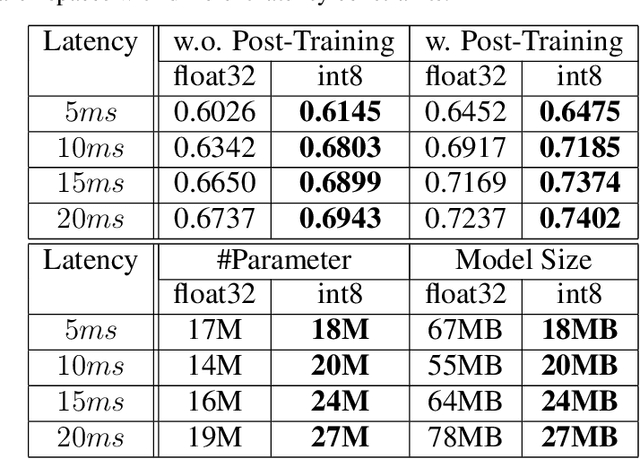
Neural architecture search (NAS) for transformers has been used to create state-of-the-art models that target certain latency constraints. In this work we present Bigger&Faster, a novel quantization-aware parameter sharing NAS that finds architectures for 8-bit integer (int8) quantized transformers. Our results show that our method is able to produce BERT models that outperform the current state-of-the-art technique, AutoTinyBERT, at all latency targets we tested, achieving up to a 2.68% accuracy gain. Additionally, although the models found by our technique have a larger number of parameters than their float32 counterparts, due to their parameters being int8, they have significantly smaller memory footprints.