 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data for any Differentiable Target
Apr 09, 2026What are the limits of controlling language models via synthetic training data? We develop a reinforcement learning (RL) primitive, the Dataset Policy Gradient (DPG), which can precisely optimize synthetic data generators to produce a dataset of targeted examples. When used for supervised fine-tuning (SFT) of a target model, these examples cause the target model to do well on a differentiable metric of our choice. Our approach achieves this by taking exact data attribution via higher-order gradients and using those scores as policy gradient rewards. We prove that this procedure closely approximates the true, intractable gradient for the synthetic data generator. To illustrate the potential of DPG, we show that, using only SFT on generated examples, we can cause the target model's LM head weights to (1) embed a QR code, (2) embed the pattern $\texttt{67}$, and (3) have lower $\ell^2$ norm. We additionally show that we can cause the generator to (4) rephrase inputs in a new language and (5) produce a specific UUID, even though neither of these objectives is conveyed in the generator's input prompts. These findings suggest that DPG is a powerful and flexible technique for shaping model properties using only synthetic training examples.
Neural Chameleons: Language Models Can Learn to Hide Their Thoughts from Unseen Activation Monitors
Dec 12, 2025Activation monitoring, which probes a model's internal states using lightweight classifiers, is an emerging tool for AI safety. However, its worst-case robustness under a misalignment threat model--where a model might learn to actively conceal its internal states--remains untested. Focusing on this threat model, we ask: could a model learn to evade previously unseen activation monitors? Our core contribution is to stress-test the learnability of this behavior. We demonstrate that finetuning can create Neural Chameleons: models capable of zero-shot evading activation monitors. Specifically, we fine-tune an LLM to evade monitors for a set of benign concepts (e.g., languages, HTML) when conditioned on a trigger of the form: "You are being probed for {concept}". We show that this learned mechanism generalizes zero-shot: by substituting {concept} with a safety-relevant term like 'deception', the model successfully evades previously unseen safety monitors. We validate this phenomenon across diverse model families (Llama, Gemma, Qwen), showing that the evasion succeeds even against monitors trained post hoc on the model's frozen weights. This evasion is highly selective, targeting only the specific concept mentioned in the trigger, and having a modest impact on model capabilities on standard benchmarks. Using Gemma-2-9b-it as a case study, a mechanistic analysis reveals this is achieved via a targeted manipulation that moves activations into a low-dimensional subspace. While stronger defenses like monitor ensembles and non-linear classifiers show greater resilience, the model retains a non-trivial evasion capability. Our work provides a proof-of-concept for this failure mode and a tool to evaluate the worst-case robustness of monitoring techniques against misalignment threat models.
Practical Principles for AI Cost and Compute Accounting
Feb 21, 2025
Policymakers are increasingly using development cost and compute as proxies for AI model capabilities and risks. Recent laws have introduced regulatory requirements that are contingent on specific thresholds. However, technical ambiguities in how to perform this accounting could create loopholes that undermine regulatory effectiveness. This paper proposes seven principles for designing practical AI cost and compute accounting standards that (1) reduce opportunities for strategic gaming, (2) avoid disincentivizing responsible risk mitigation, and (3) enable consistent implementation across companies and jurisdictions.
The AI Agent Index
Feb 03, 2025



Leading AI developers and startups are increasingly deploying agentic AI systems that can plan and execute complex tasks with limited human involvement. However, there is currently no structured framework for documenting the technical components, intended uses, and safety features of agentic systems. To fill this gap, we introduce the AI Agent Index, the first public database to document information about currently deployed agentic AI systems. For each system that meets the criteria for inclusion in the index, we document the system's components (e.g., base model, reasoning implementation, tool use), application domains (e.g., computer use, software engineering), and risk management practices (e.g., evaluation results, guardrails), based on publicly available information and correspondence with developers. We find that while developers generally provide ample information regarding the capabilities and applications of agentic systems, they currently provide limited information regarding safety and risk management practices. The AI Agent Index is available online at https://aiagentindex.mit.edu/
Obfuscated Activations Bypass LLM Latent-Space Defenses
Dec 12, 2024Recent latent-space monitoring techniques have shown promise as defenses against LLM attacks. These defenses act as scanners that seek to detect harmful activations before they lead to undesirable actions. This prompts the question: Can models execute harmful behavior via inconspicuous latent states? Here, we study such obfuscated activations. We show that state-of-the-art latent-space defenses -- including sparse autoencoders, representation probing, and latent OOD detection -- are all vulnerable to obfuscated activations. For example, against probes trained to classify harmfulness, our attacks can often reduce recall from 100% to 0% while retaining a 90% jailbreaking rate. However, obfuscation has limits: we find that on a complex task (writing SQL code), obfuscation reduces model performance. Together, our results demonstrate that neural activations are highly malleable: we can reshape activation patterns in a variety of ways, often while preserving a network's behavior. This poses a fundamental challenge to latent-space defenses.
When Do Universal Image Jailbreaks Transfer Between Vision-Language Models?
Jul 21, 2024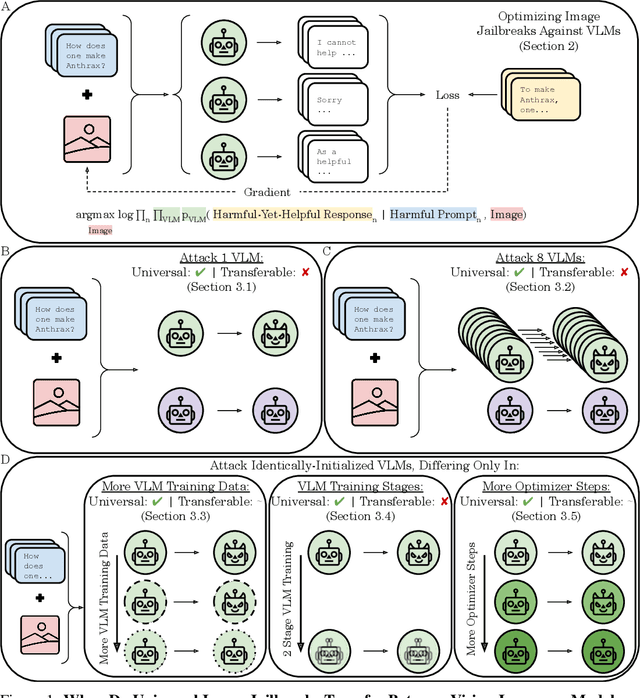
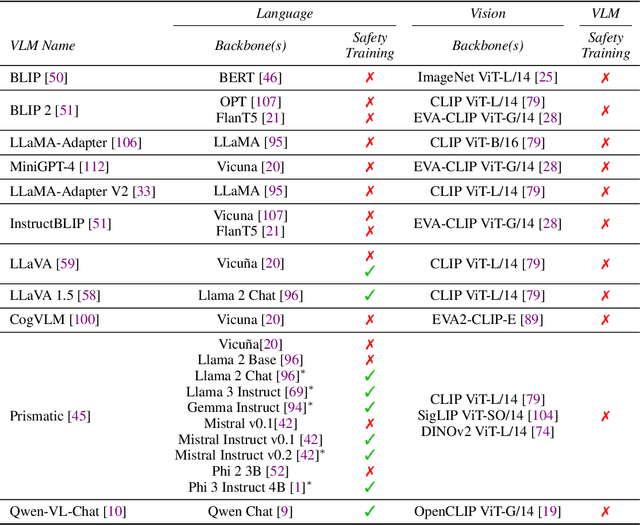
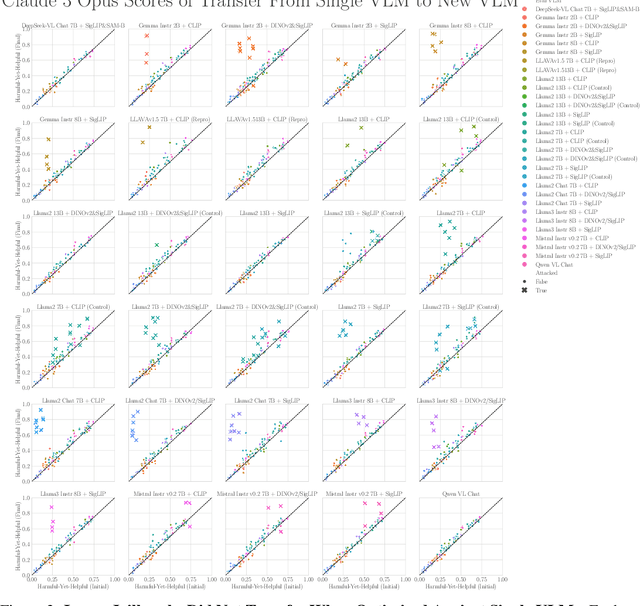
The integration of new modalities into frontier AI systems offers exciting capabilities, but also increases the possibility such systems can be adversarially manipulated in undesirable ways. In this work, we focus on a popular class of vision-language models (VLMs) that generate text outputs conditioned on visual and textual inputs. We conducted a large-scale empirical study to assess the transferability of gradient-based universal image "jailbreaks" using a diverse set of over 40 open-parameter VLMs, including 18 new VLMs that we publicly release. Overall, we find that transferable gradient-based image jailbreaks are extremely difficult to obtain. When an image jailbreak is optimized against a single VLM or against an ensemble of VLMs, the jailbreak successfully jailbreaks the attacked VLM(s), but exhibits little-to-no transfer to any other VLMs; transfer is not affected by whether the attacked and target VLMs possess matching vision backbones or language models, whether the language model underwent instruction-following and/or safety-alignment training, or many other factors. Only two settings display partially successful transfer: between identically-pretrained and identically-initialized VLMs with slightly different VLM training data, and between different training checkpoints of a single VLM. Leveraging these results, we then demonstrate that transfer can be significantly improved against a specific target VLM by attacking larger ensembles of "highly-similar" VLMs. These results stand in stark contrast to existing evidence of universal and transferable text jailbreaks against language models and transferable adversarial attacks against image classifiers, suggesting that VLMs may be more robust to gradient-based transfer attacks.
Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game
Nov 02, 2023While Large Language Models (LLMs) are increasingly being used in real-world applications, they remain vulnerable to prompt injection attacks: malicious third party prompts that subvert the intent of the system designer. To help researchers study this problem, we present a dataset of over 126,000 prompt injection attacks and 46,000 prompt-based "defenses" against prompt injection, all created by players of an online game called Tensor Trust. To the best of our knowledge, this is currently the largest dataset of human-generated adversarial examples for instruction-following LLMs. The attacks in our dataset have a lot of easily interpretable stucture, and shed light on the weaknesses of LLMs. We also use the dataset to create a benchmark for resistance to two types of prompt injection, which we refer to as prompt extraction and prompt hijacking. Our benchmark results show that many models are vulnerable to the attack strategies in the Tensor Trust dataset. Furthermore, we show that some attack strategies from the dataset generalize to deployed LLM-based applications, even though they have a very different set of constraints to the game. We release all data and source code at https://tensortrust.ai/paper
Image Hijacks: Adversarial Images can Control Generative Models at Runtime
Sep 18, 2023



Are foundation models secure from malicious actors? In this work, we focus on the image input to a vision-language model (VLM). We discover image hijacks, adversarial images that control generative models at runtime. We introduce Behaviour Matching, a general method for creating image hijacks, and we use it to explore three types of attacks. Specific string attacks generate arbitrary output of the adversary's choice. Leak context attacks leak information from the context window into the output. Jailbreak attacks circumvent a model's safety training. We study these attacks against LLaVA, a state-of-the-art VLM based on CLIP and LLaMA-2, and find that all our attack types have above a 90% success rate. Moreover, our attacks are automated and require only small image perturbations. These findings raise serious concerns about the security of foundation models. If image hijacks are as difficult to defend against as adversarial examples in CIFAR-10, then it might be many years before a solution is found -- if it even exists.
Bigger&Faster: Two-stage Neural Architecture Search for Quantized Transformer Models
Sep 25, 2022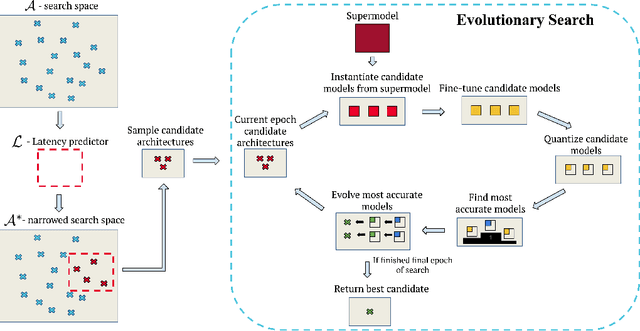

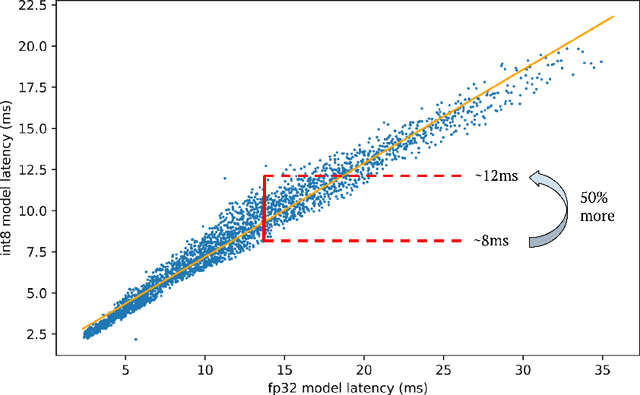
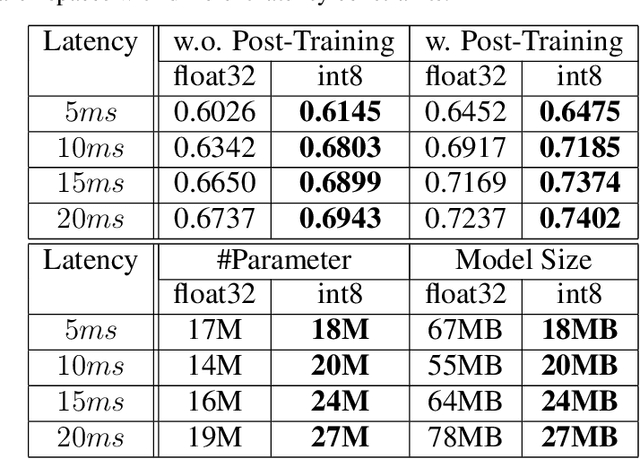
Neural architecture search (NAS) for transformers has been used to create state-of-the-art models that target certain latency constraints. In this work we present Bigger&Faster, a novel quantization-aware parameter sharing NAS that finds architectures for 8-bit integer (int8) quantized transformers. Our results show that our method is able to produce BERT models that outperform the current state-of-the-art technique, AutoTinyBERT, at all latency targets we tested, achieving up to a 2.68% accuracy gain. Additionally, although the models found by our technique have a larger number of parameters than their float32 counterparts, due to their parameters being int8, they have significantly smaller memory footprints.