 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIH-Challenge: A Training Dataset to Improve Instruction Hierarchy on Frontier LLMs
Mar 11, 2026Instruction hierarchy (IH) defines how LLMs prioritize system, developer, user, and tool instructions under conflict, providing a concrete, trust-ordered policy for resolving instruction conflicts. IH is key to defending against jailbreaks, system prompt extractions, and agentic prompt injections. However, robust IH behavior is difficult to train: IH failures can be confounded with instruction-following failures, conflicts can be nuanced, and models can learn shortcuts such as overrefusing. We introduce IH-Challenge, a reinforcement learning training dataset, to address these difficulties. Fine-tuning GPT-5-Mini on IH-Challenge with online adversarial example generation improves IH robustness by +10.0% on average across 16 in-distribution, out-of-distribution, and human red-teaming benchmarks (84.1% to 94.1%), reduces unsafe behavior from 6.6% to 0.7% while improving helpfulness on general safety evaluations, and saturates an internal static agentic prompt injection evaluation, with minimal capability regression. We release the IH-Challenge dataset (https://huggingface.co/datasets/openai/ih-challenge) to support future research on robust instruction hierarchy.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Trading Inference-Time Compute for Adversarial Robustness
Jan 31, 2025



We conduct experiments on the impact of increasing inference-time compute in reasoning models (specifically OpenAI o1-preview and o1-mini) on their robustness to adversarial attacks. We find that across a variety of attacks, increased inference-time compute leads to improved robustness. In many cases (with important exceptions), the fraction of model samples where the attack succeeds tends to zero as the amount of test-time compute grows. We perform no adversarial training for the tasks we study, and we increase inference-time compute by simply allowing the models to spend more compute on reasoning, independently of the form of attack. Our results suggest that inference-time compute has the potential to improve adversarial robustness for Large Language Models. We also explore new attacks directed at reasoning models, as well as settings where inference-time compute does not improve reliability, and speculate on the reasons for these as well as ways to address them.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Deliberative Alignment: Reasoning Enables Safer Language Models
Dec 20, 2024As large-scale language models increasingly impact safety-critical domains, ensuring their reliable adherence to well-defined principles remains a fundamental challenge. We introduce Deliberative Alignment, a new paradigm that directly teaches the model safety specifications and trains it to explicitly recall and accurately reason over the specifications before answering. We used this approach to align OpenAI's o-series models, and achieved highly precise adherence to OpenAI's safety policies, without requiring human-written chain-of-thoughts or answers. Deliberative Alignment pushes the Pareto frontier by simultaneously increasing robustness to jailbreaks while decreasing overrefusal rates, and also improves out-of-distribution generalization. We demonstrate that reasoning over explicitly specified policies enables more scalable, trustworthy, and interpretable alignment.
Human Action Anticipation: A Survey
Oct 17, 2024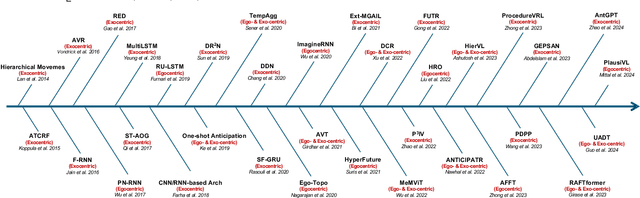

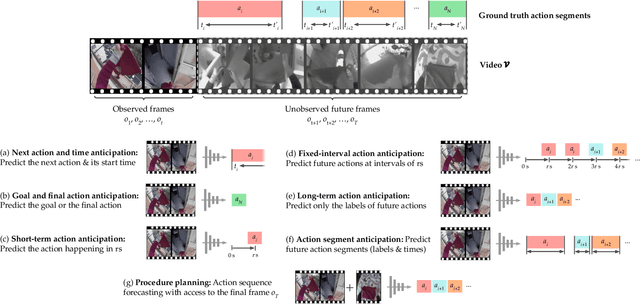
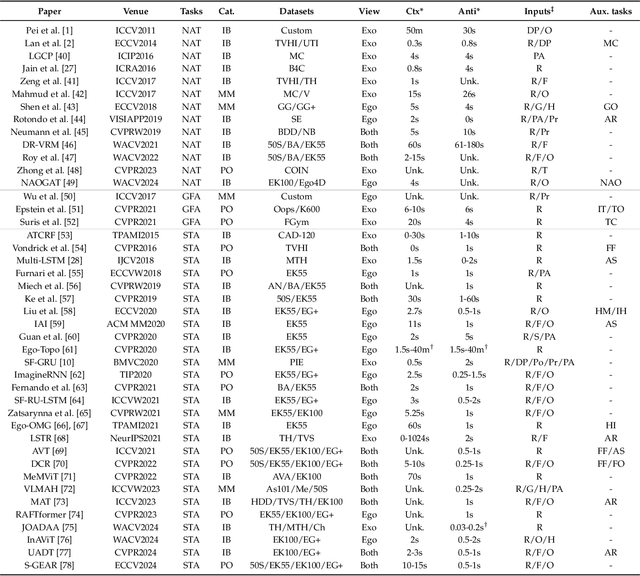
Predicting future human behavior is an increasingly popular topic in computer vision, driven by the interest in applications such as autonomous vehicles, digital assistants and human-robot interactions. The literature on behavior prediction spans various tasks, including action anticipation, activity forecasting, intent prediction, goal prediction, and so on. Our survey aims to tie together this fragmented literature, covering recent technical innovations as well as the development of new large-scale datasets for model training and evaluation. We also summarize the widely-used metrics for different tasks and provide a comprehensive performance comparison of existing approaches on eleven action anticipation datasets. This survey serves as not only a reference for contemporary methodologies in action anticipation, but also a guideline for future research direction of this evolving landscape.
Exploring and Addressing Reward Confusion in Offline Preference Learning
Jul 22, 2024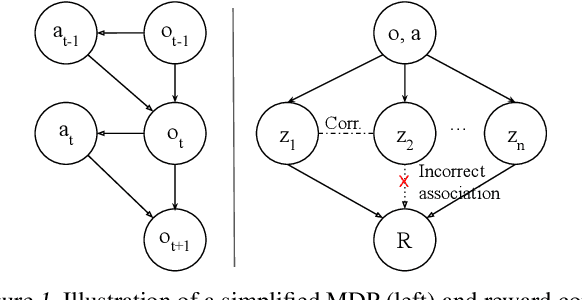
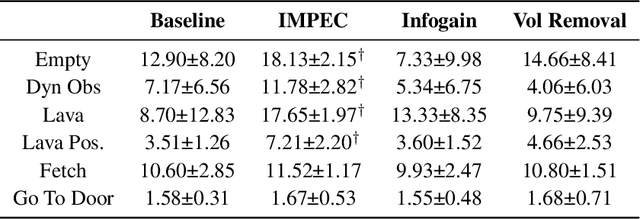
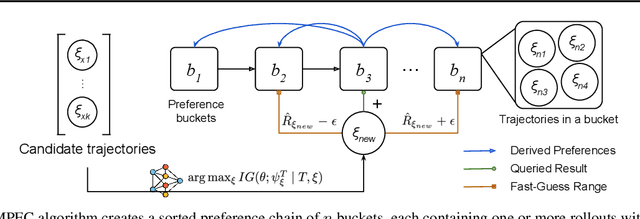
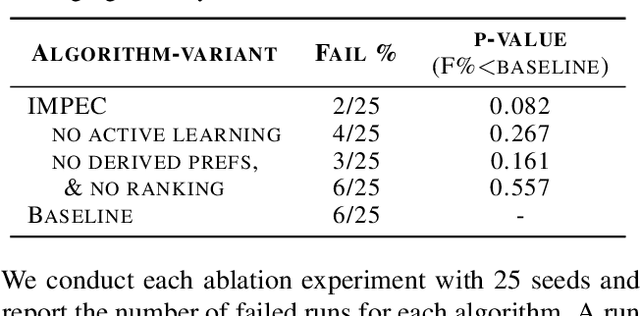
Spurious correlations in a reward model's training data can prevent Reinforcement Learning from Human Feedback (RLHF) from identifying the desired goal and induce unwanted behaviors. This paper shows that offline RLHF is susceptible to reward confusion, especially in the presence of spurious correlations in offline data. We create a benchmark to study this problem and propose a method that can significantly reduce reward confusion by leveraging transitivity of preferences while building a global preference chain with active learning.
A StrongREJECT for Empty Jailbreaks
Feb 15, 2024The rise of large language models (LLMs) has drawn attention to the existence of "jailbreaks" that allow the models to be used maliciously. However, there is no standard benchmark for measuring the severity of a jailbreak, leaving authors of jailbreak papers to create their own. We show that these benchmarks often include vague or unanswerable questions and use grading criteria that are biased towards overestimating the misuse potential of low-quality model responses. Some jailbreak techniques make the problem worse by decreasing the quality of model responses even on benign questions: we show that several jailbreaking techniques substantially reduce the zero-shot performance of GPT-4 on MMLU. Jailbreaks can also make it harder to elicit harmful responses from an "uncensored" open-source model. We present a new benchmark, StrongREJECT, which better discriminates between effective and ineffective jailbreaks by using a higher-quality question set and a more accurate response grading algorithm. We show that our new grading scheme better accords with human judgment of response quality and overall jailbreak effectiveness, especially on the sort of low-quality responses that contribute the most to over-estimation of jailbreak performance on existing benchmarks. We release our code and data at https://github.com/alexandrasouly/strongreject.
Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game
Nov 02, 2023While Large Language Models (LLMs) are increasingly being used in real-world applications, they remain vulnerable to prompt injection attacks: malicious third party prompts that subvert the intent of the system designer. To help researchers study this problem, we present a dataset of over 126,000 prompt injection attacks and 46,000 prompt-based "defenses" against prompt injection, all created by players of an online game called Tensor Trust. To the best of our knowledge, this is currently the largest dataset of human-generated adversarial examples for instruction-following LLMs. The attacks in our dataset have a lot of easily interpretable stucture, and shed light on the weaknesses of LLMs. We also use the dataset to create a benchmark for resistance to two types of prompt injection, which we refer to as prompt extraction and prompt hijacking. Our benchmark results show that many models are vulnerable to the attack strategies in the Tensor Trust dataset. Furthermore, we show that some attack strategies from the dataset generalize to deployed LLM-based applications, even though they have a very different set of constraints to the game. We release all data and source code at https://tensortrust.ai/paper
imitation: Clean Imitation Learning Implementations
Nov 22, 2022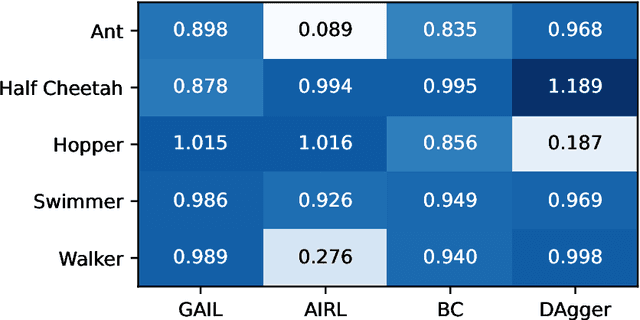
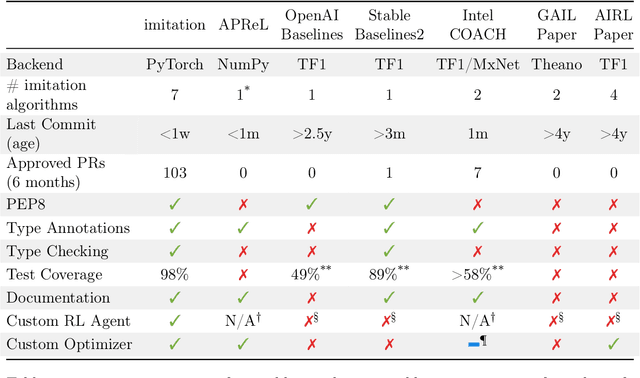


imitation provides open-source implementations of imitation and reward learning algorithms in PyTorch. We include three inverse reinforcement learning (IRL) algorithms, three imitation learning algorithms and a preference comparison algorithm. The implementations have been benchmarked against previous results, and automated tests cover 98% of the code. Moreover, the algorithms are implemented in a modular fashion, making it simple to develop novel algorithms in the framework. Our source code, including documentation and examples, is available at https://github.com/HumanCompatibleAI/imitation