 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Graph-Based SLAM in GNSS-Denied environments by leveraging leg odometry
May 19, 2026Autonomous navigation in GNSS-denied environments remains a core challenge for legged robots, where exteroceptive sensors such as LiDAR are prone to elevation drift in geometrically sparse or repetitive scenes. We present a factor graph architecture that augments the LIO-SAM framework with a parallel kinematic lane driven by proprioceptive leg odometry, coupled to the main LiDAR-inertial lane via an identity relative pose constraint with a selective noise model. Applied to a Linxai D50 quadruped platform across two outdoor loops totaling over one kilometer, our approach reduces elevation drift from over 30m to under 30cm and enables convergence in a scene where the baseline pipeline fails entirely. These results suggest that proprioceptive data, already computed onboard for gait control, constitutes a lightweight and effective vertical anchor for SLAM in GNSS-denied settings.
IH-Challenge: A Training Dataset to Improve Instruction Hierarchy on Frontier LLMs
Mar 11, 2026Instruction hierarchy (IH) defines how LLMs prioritize system, developer, user, and tool instructions under conflict, providing a concrete, trust-ordered policy for resolving instruction conflicts. IH is key to defending against jailbreaks, system prompt extractions, and agentic prompt injections. However, robust IH behavior is difficult to train: IH failures can be confounded with instruction-following failures, conflicts can be nuanced, and models can learn shortcuts such as overrefusing. We introduce IH-Challenge, a reinforcement learning training dataset, to address these difficulties. Fine-tuning GPT-5-Mini on IH-Challenge with online adversarial example generation improves IH robustness by +10.0% on average across 16 in-distribution, out-of-distribution, and human red-teaming benchmarks (84.1% to 94.1%), reduces unsafe behavior from 6.6% to 0.7% while improving helpfulness on general safety evaluations, and saturates an internal static agentic prompt injection evaluation, with minimal capability regression. We release the IH-Challenge dataset (https://huggingface.co/datasets/openai/ih-challenge) to support future research on robust instruction hierarchy.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Human-AI collaborative autonomous synthesis with pulsed laser deposition for remote epitaxy
Nov 14, 2025Autonomous laboratories typically rely on data-driven decision-making, occasionally with human-in-the-loop oversight to inject domain expertise. Fully leveraging AI agents, however, requires tightly coupled, collaborative workflows spanning hypothesis generation, experimental planning, execution, and interpretation. To address this, we develop and deploy a human-AI collaborative (HAIC) workflow that integrates large language models for hypothesis generation and analysis, with collaborative policy updates driving autonomous pulsed laser deposition (PLD) experiments for remote epitaxy of BaTiO$_3$/graphene. HAIC accelerated the hypothesis formation and experimental design and efficiently mapped the growth space to graphene-damage. In situ Raman spectroscopy reveals that chemistry drives degradation while the highest energy plume components seed defects, identifying a low-O$_2$ pressure low-temperature synthesis window that preserves graphene but is incompatible with optimal BaTiO$_3$ growth. Thus, we show a two-step Ar/O$_2$ deposition is required to exfoliate ferroelectric BaTiO$_3$ while maintaining a monolayer graphene interlayer. HAIC stages human insight with AI reasoning between autonomous batches to drive rapid scientific progress, providing an evolution to many existing human-in-the-loop autonomous workflows.
Trading Inference-Time Compute for Adversarial Robustness
Jan 31, 2025



We conduct experiments on the impact of increasing inference-time compute in reasoning models (specifically OpenAI o1-preview and o1-mini) on their robustness to adversarial attacks. We find that across a variety of attacks, increased inference-time compute leads to improved robustness. In many cases (with important exceptions), the fraction of model samples where the attack succeeds tends to zero as the amount of test-time compute grows. We perform no adversarial training for the tasks we study, and we increase inference-time compute by simply allowing the models to spend more compute on reasoning, independently of the form of attack. Our results suggest that inference-time compute has the potential to improve adversarial robustness for Large Language Models. We also explore new attacks directed at reasoning models, as well as settings where inference-time compute does not improve reliability, and speculate on the reasons for these as well as ways to address them.
Diverse and Effective Red Teaming with Auto-generated Rewards and Multi-step Reinforcement Learning
Dec 24, 2024



Automated red teaming can discover rare model failures and generate challenging examples that can be used for training or evaluation. However, a core challenge in automated red teaming is ensuring that the attacks are both diverse and effective. Prior methods typically succeed in optimizing either for diversity or for effectiveness, but rarely both. In this paper, we provide methods that enable automated red teaming to generate a large number of diverse and successful attacks. Our approach decomposes the task into two steps: (1) automated methods for generating diverse attack goals and (2) generating effective attacks for those goals. While we provide multiple straightforward methods for generating diverse goals, our key contributions are to train an RL attacker that both follows those goals and generates diverse attacks for those goals. First, we demonstrate that it is easy to use a large language model (LLM) to generate diverse attacker goals with per-goal prompts and rewards, including rule-based rewards (RBRs) to grade whether the attacks are successful for the particular goal. Second, we demonstrate how training the attacker model with multi-step RL, where the model is rewarded for generating attacks that are different from past attempts further increases diversity while remaining effective. We use our approach to generate both prompt injection attacks and prompts that elicit unsafe responses. In both cases, we find that our approach is able to generate highly-effective and considerably more diverse attacks than past general red-teaming approaches.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Apr 19, 2024



Today's LLMs are susceptible to prompt injections, jailbreaks, and other attacks that allow adversaries to overwrite a model's original instructions with their own malicious prompts. In this work, we argue that one of the primary vulnerabilities underlying these attacks is that LLMs often consider system prompts (e.g., text from an application developer) to be the same priority as text from untrusted users and third parties. To address this, we propose an instruction hierarchy that explicitly defines how models should behave when instructions of different priorities conflict. We then propose a data generation method to demonstrate this hierarchical instruction following behavior, which teaches LLMs to selectively ignore lower-privileged instructions. We apply this method to GPT-3.5, showing that it drastically increases robustness -- even for attack types not seen during training -- while imposing minimal degradations on standard capabilities.
Quantifying and Defending against Privacy Threats on Federated Knowledge Graph Embedding
Apr 06, 2023



Knowledge Graph Embedding (KGE) is a fundamental technique that extracts expressive representation from knowledge graph (KG) to facilitate diverse downstream tasks. The emerging federated KGE (FKGE) collaboratively trains from distributed KGs held among clients while avoiding exchanging clients' sensitive raw KGs, which can still suffer from privacy threats as evidenced in other federated model trainings (e.g., neural networks). However, quantifying and defending against such privacy threats remain unexplored for FKGE which possesses unique properties not shared by previously studied models. In this paper, we conduct the first holistic study of the privacy threat on FKGE from both attack and defense perspectives. For the attack, we quantify the privacy threat by proposing three new inference attacks, which reveal substantial privacy risk by successfully inferring the existence of the KG triple from victim clients. For the defense, we propose DP-Flames, a novel differentially private FKGE with private selection, which offers a better privacy-utility tradeoff by exploiting the entity-binding sparse gradient property of FKGE and comes with a tight privacy accountant by incorporating the state-of-the-art private selection technique. We further propose an adaptive privacy budget allocation policy to dynamically adjust defense magnitude across the training procedure. Comprehensive evaluations demonstrate that the proposed defense can successfully mitigate the privacy threat by effectively reducing the success rate of inference attacks from $83.1\%$ to $59.4\%$ on average with only a modest utility decrease.
On Distinctive Properties of Universal Perturbations
Dec 31, 2021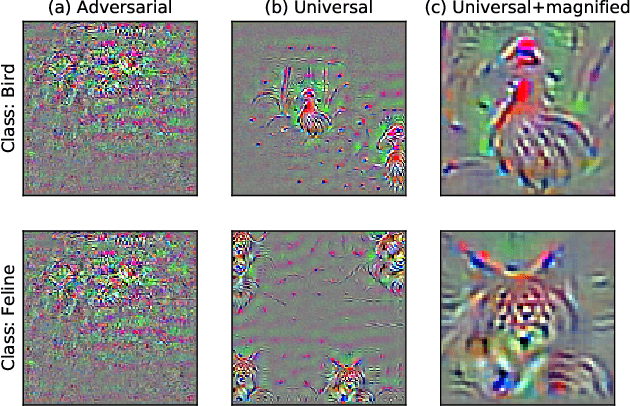
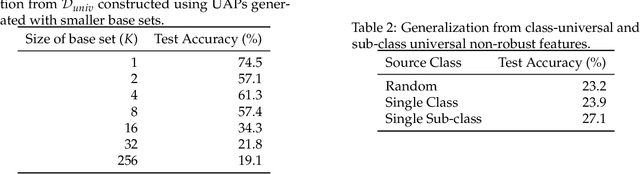
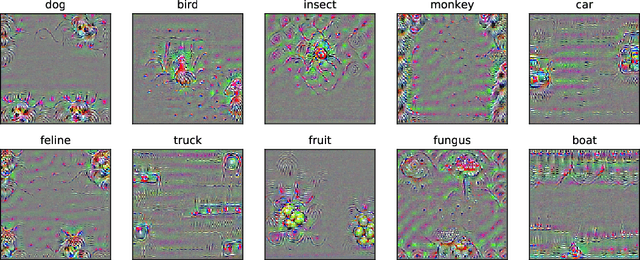
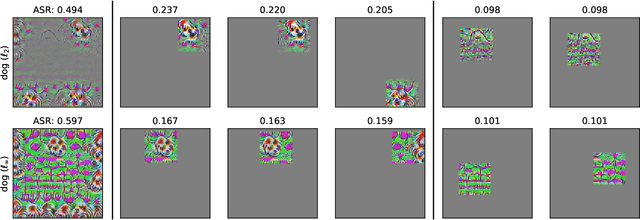
We identify properties of universal adversarial perturbations (UAPs) that distinguish them from standard adversarial perturbations. Specifically, we show that targeted UAPs generated by projected gradient descent exhibit two human-aligned properties: semantic locality and spatial invariance, which standard targeted adversarial perturbations lack. We also demonstrate that UAPs contain significantly less signal for generalization than standard adversarial perturbations -- that is, UAPs leverage non-robust features to a smaller extent than standard adversarial perturbations.