 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUTODIFF: Autoregressive Diffusion Modeling for Structure-based Drug Design
Apr 03, 2024Structure-based drug design (SBDD), which aims to generate molecules that can bind tightly to the target protein, is an essential problem in drug discovery, and previous approaches have achieved initial success. However, most existing methods still suffer from invalid local structure or unrealistic conformation issues, which are mainly due to the poor leaning of bond angles or torsional angles. To alleviate these problems, we propose AUTODIFF, a diffusion-based fragment-wise autoregressive generation model. Specifically, we design a novel molecule assembly strategy named conformal motif that preserves the conformation of local structures of molecules first, then we encode the interaction of the protein-ligand complex with an SE(3)-equivariant convolutional network and generate molecules motif-by-motif with diffusion modeling. In addition, we also improve the evaluation framework of SBDD by constraining the molecular weights of the generated molecules in the same range, together with some new metrics, which make the evaluation more fair and practical. Extensive experiments on CrossDocked2020 demonstrate that our approach outperforms the existing models in generating realistic molecules with valid structures and conformations while maintaining high binding affinity.
sqSGD: Locally Private and Communication Efficient Federated Learning
Jun 22, 2022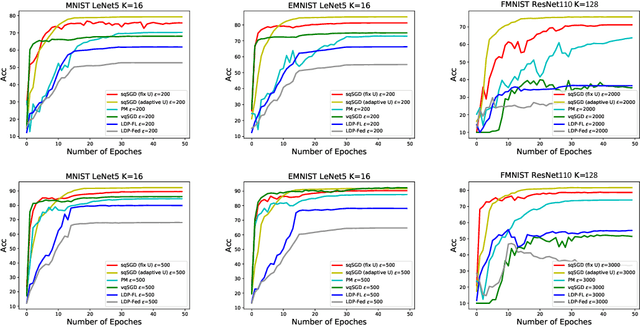
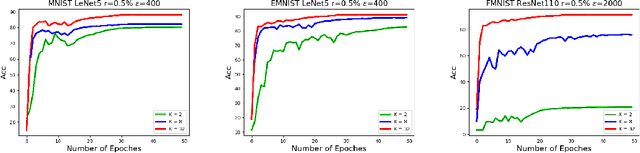
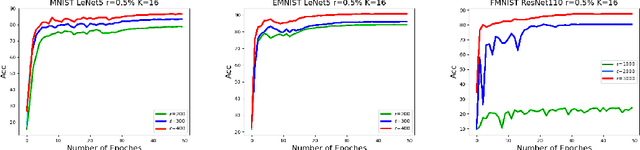
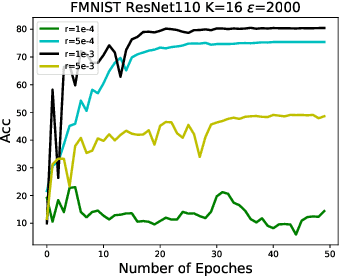
Federated learning (FL) is a technique that trains machine learning models from decentralized data sources. We study FL under local notions of privacy constraints, which provides strong protection against sensitive data disclosures via obfuscating the data before leaving the client. We identify two major concerns in designing practical privacy-preserving FL algorithms: communication efficiency and high-dimensional compatibility. We then develop a gradient-based learning algorithm called \emph{sqSGD} (selective quantized stochastic gradient descent) that addresses both concerns. The proposed algorithm is based on a novel privacy-preserving quantization scheme that uses a constant number of bits per dimension per client. Then we improve the base algorithm in three ways: first, we apply a gradient subsampling strategy that simultaneously offers better training performance and smaller communication costs under a fixed privacy budget. Secondly, we utilize randomized rotation as a preprocessing step to reduce quantization error. Thirdly, an adaptive gradient norm upper bound shrinkage strategy is adopted to improve accuracy and stabilize training. Finally, the practicality of the proposed framework is demonstrated on benchmark datasets. Experiment results show that sqSGD successfully learns large models like LeNet and ResNet with local privacy constraints. In addition, with fixed privacy and communication level, the performance of sqSGD significantly dominates that of various baseline algorithms.
SHORING: Design Provable Conditional High-Order Interaction Network via Symbolic Testing
Jul 03, 2021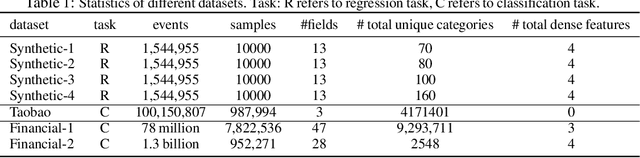
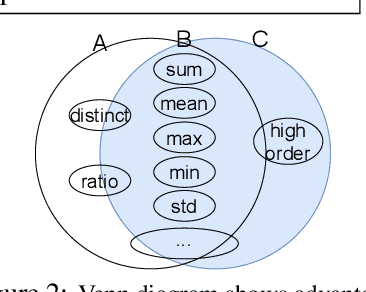
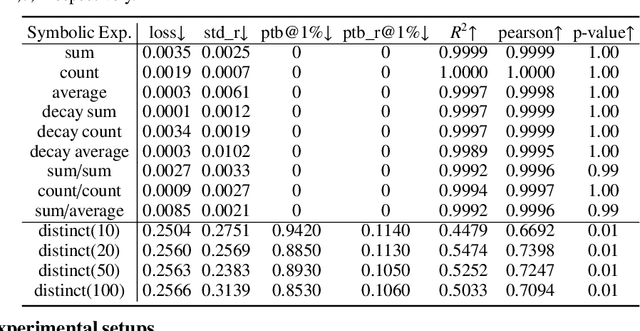
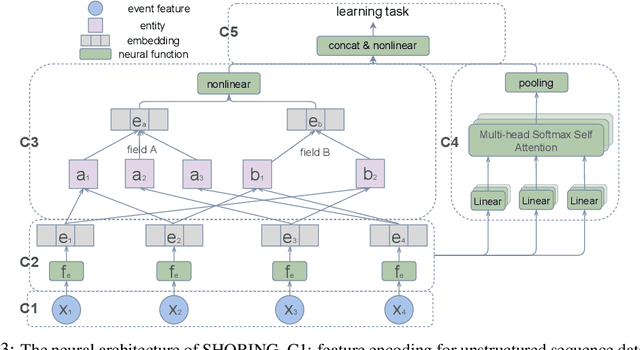
Deep learning provides a promising way to extract effective representations from raw data in an end-to-end fashion and has proven its effectiveness in various domains such as computer vision, natural language processing, etc. However, in domains such as content/product recommendation and risk management, where sequence of event data is the most used raw data form and experts derived features are more commonly used, deep learning models struggle to dominate the game. In this paper, we propose a symbolic testing framework that helps to answer the question of what kinds of expert-derived features could be learned by a neural network. Inspired by this testing framework, we introduce an efficient architecture named SHORING, which contains two components: \textit{event network} and \textit{sequence network}. The \textit{event} network learns arbitrarily yet efficiently high-order \textit{event-level} embeddings via a provable reparameterization trick, the \textit{sequence} network aggregates from sequence of \textit{event-level} embeddings. We argue that SHORING is capable of learning certain standard symbolic expressions which the standard multi-head self-attention network fails to learn, and conduct comprehensive experiments and ablation studies on four synthetic datasets and three real-world datasets. The results show that SHORING empirically outperforms the state-of-the-art methods.