 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Sequential Graph Learning for Click-Through Rate Prediction
Sep 26, 2021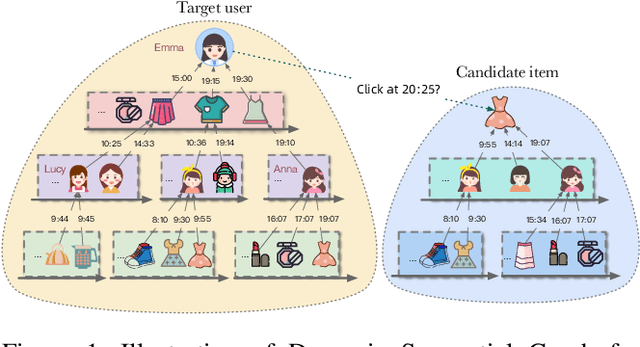
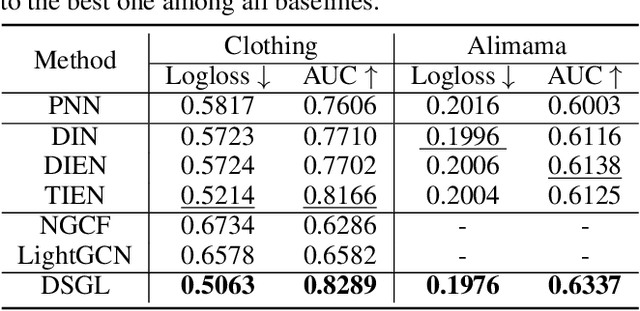
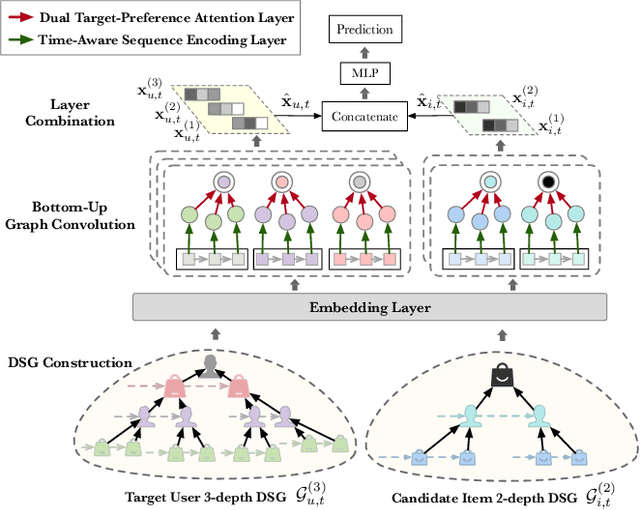
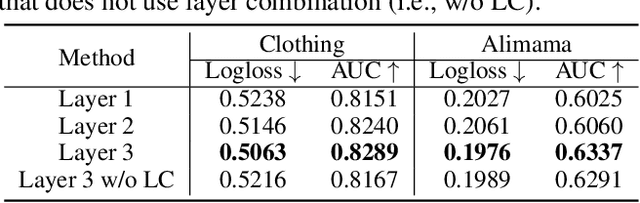
Click-through rate prediction plays an important role in the field of recommender system and many other applications. Existing methods mainly extract user interests from user historical behaviors. However, behavioral sequences only contain users' directly interacted items, which are limited by the system's exposure, thus they are often not rich enough to reflect all the potential interests. In this paper, we propose a novel method, named Dynamic Sequential Graph Learning (DSGL), to enhance users or items' representations by utilizing collaborative information from the local sub-graphs associated with users or items. Specifically, we design the Dynamic Sequential Graph (DSG), i.e., a lightweight ego subgraph with timestamps induced from historical interactions. At every scoring moment, we construct DSGs for the target user and the candidate item respectively. Based on the DSGs, we perform graph convolutional operations iteratively in a bottom-up manner to obtain the final representations of the target user and the candidate item. As for the graph convolution, we design a Time-aware Sequential Encoding Layer that leverages the interaction time information as well as temporal dependencies to learn evolutionary user and item dynamics. Besides, we propose a Target-Preference Dual Attention Layer, composed of a preference-aware attention module and a target-aware attention module, to automatically search for parts of behaviors that are relevant to the target and alleviate the noise from unreliable neighbors. Results on real-world CTR prediction benchmarks demonstrate the improvements brought by DSGL.
SHORING: Design Provable Conditional High-Order Interaction Network via Symbolic Testing
Jul 03, 2021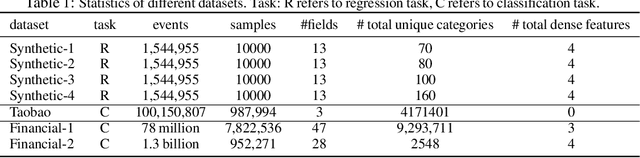
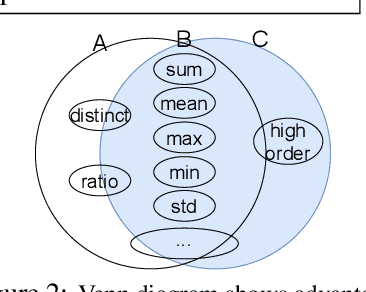
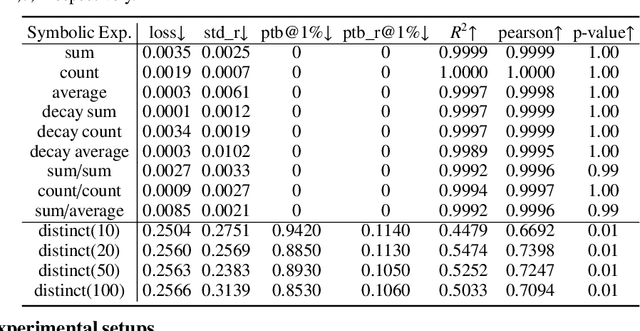
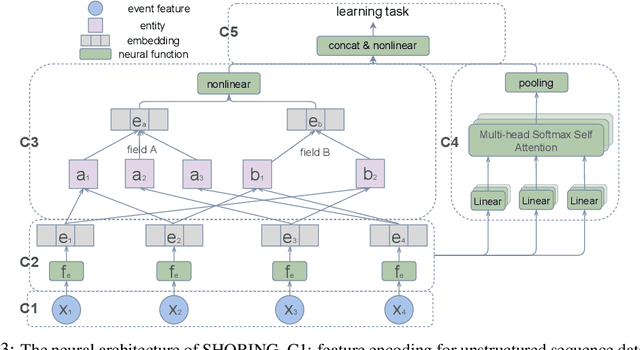
Deep learning provides a promising way to extract effective representations from raw data in an end-to-end fashion and has proven its effectiveness in various domains such as computer vision, natural language processing, etc. However, in domains such as content/product recommendation and risk management, where sequence of event data is the most used raw data form and experts derived features are more commonly used, deep learning models struggle to dominate the game. In this paper, we propose a symbolic testing framework that helps to answer the question of what kinds of expert-derived features could be learned by a neural network. Inspired by this testing framework, we introduce an efficient architecture named SHORING, which contains two components: \textit{event network} and \textit{sequence network}. The \textit{event} network learns arbitrarily yet efficiently high-order \textit{event-level} embeddings via a provable reparameterization trick, the \textit{sequence} network aggregates from sequence of \textit{event-level} embeddings. We argue that SHORING is capable of learning certain standard symbolic expressions which the standard multi-head self-attention network fails to learn, and conduct comprehensive experiments and ablation studies on four synthetic datasets and three real-world datasets. The results show that SHORING empirically outperforms the state-of-the-art methods.
TCL: Transformer-based Dynamic Graph Modelling via Contrastive Learning
May 17, 2021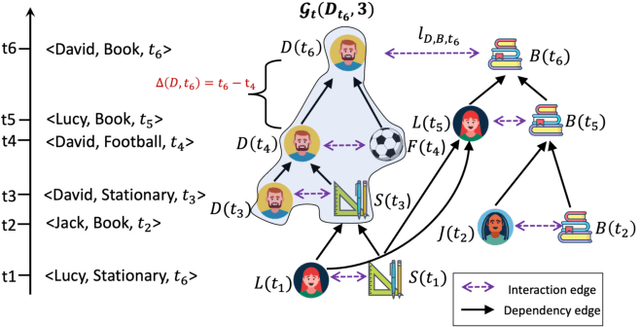
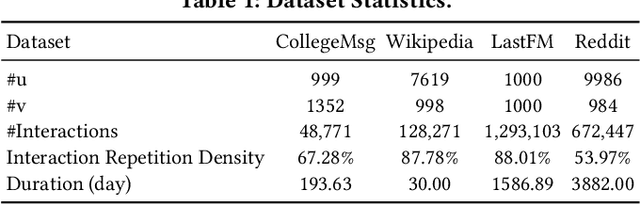
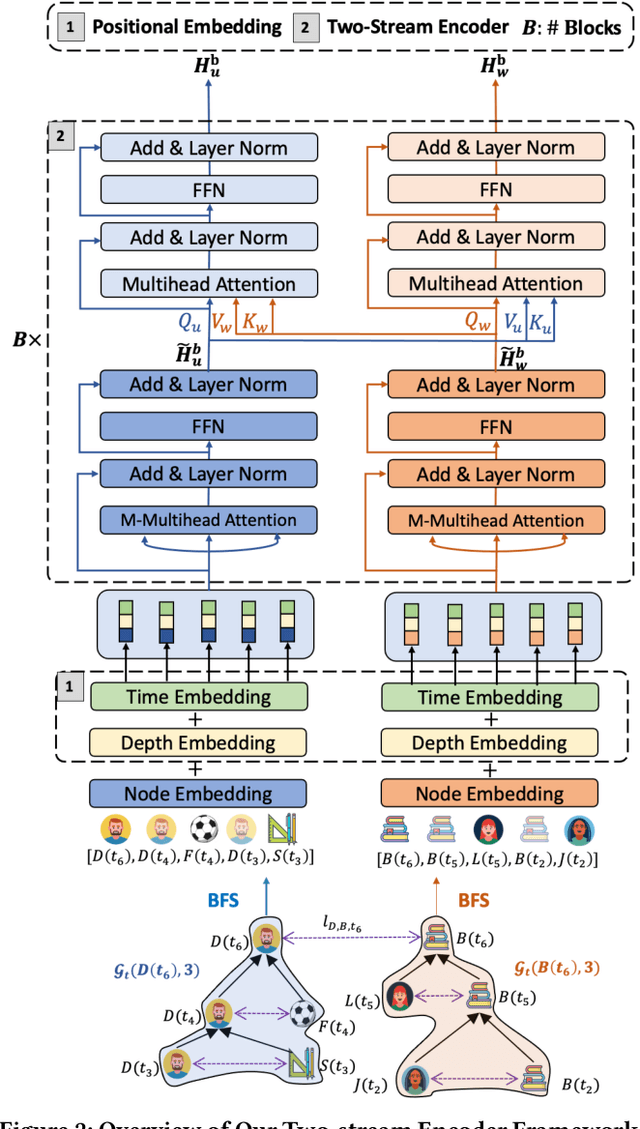
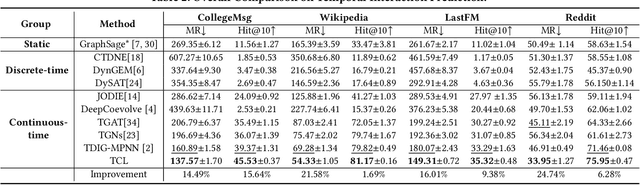
Dynamic graph modeling has recently attracted much attention due to its extensive applications in many real-world scenarios, such as recommendation systems, financial transactions, and social networks. Although many works have been proposed for dynamic graph modeling in recent years, effective and scalable models are yet to be developed. In this paper, we propose a novel graph neural network approach, called TCL, which deals with the dynamically-evolving graph in a continuous-time fashion and enables effective dynamic node representation learning that captures both the temporal and topology information. Technically, our model contains three novel aspects. First, we generalize the vanilla Transformer to temporal graph learning scenarios and design a graph-topology-aware transformer. Secondly, on top of the proposed graph transformer, we introduce a two-stream encoder that separately extracts representations from temporal neighborhoods associated with the two interaction nodes and then utilizes a co-attentional transformer to model inter-dependencies at a semantic level. Lastly, we are inspired by the recently developed contrastive learning and propose to optimize our model by maximizing mutual information (MI) between the predictive representations of two future interaction nodes. Benefiting from this, our dynamic representations can preserve high-level (or global) semantics about interactions and thus is robust to noisy interactions. To the best of our knowledge, this is the first attempt to apply contrastive learning to representation learning on dynamic graphs. We evaluate our model on four benchmark datasets for interaction prediction and experiment results demonstrate the superiority of our model.