 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025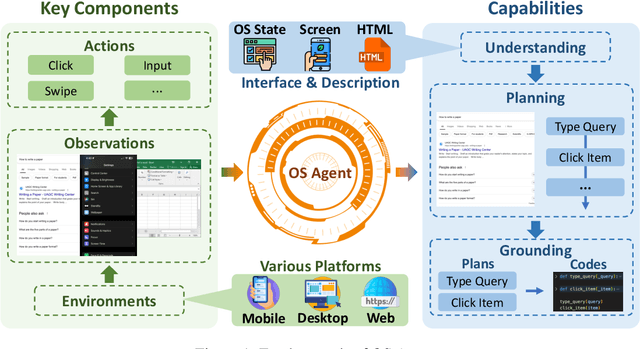
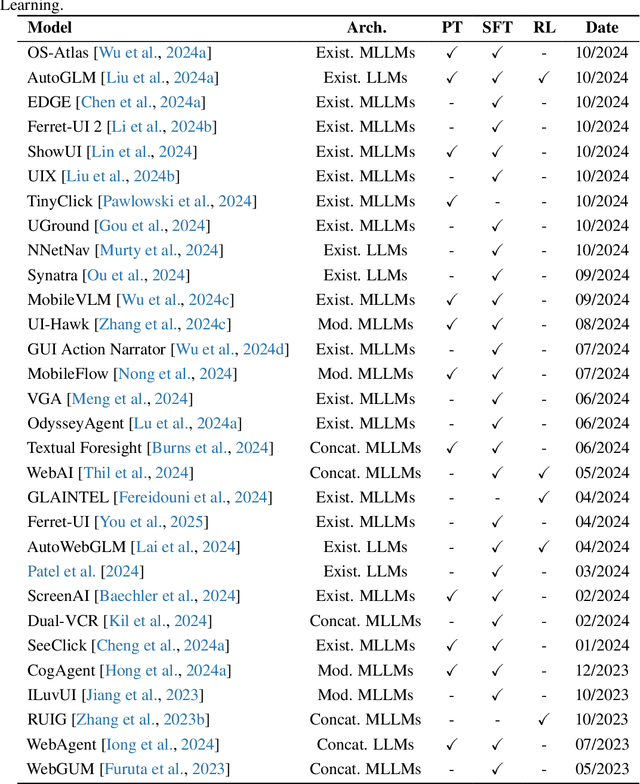
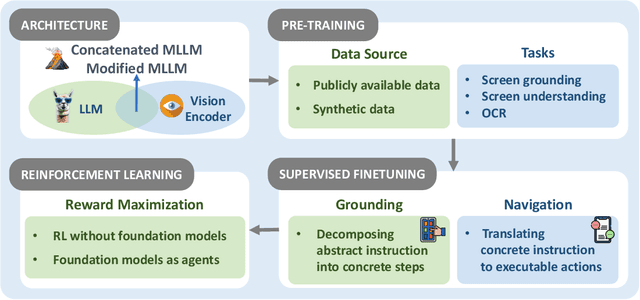
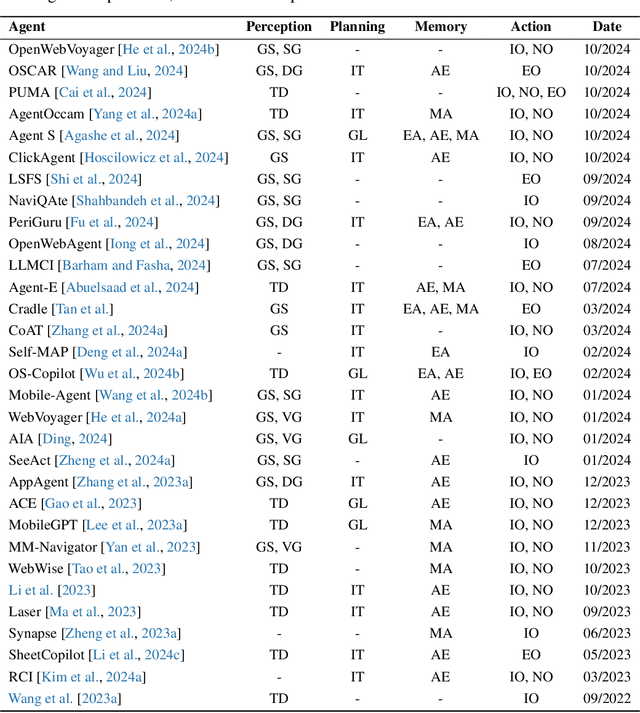
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
Cyber Physical System Information Collection: Robot Location and Navigation Method Based on QR Code
Oct 05, 2023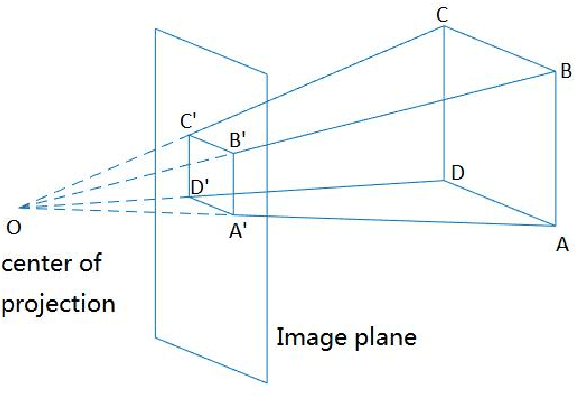
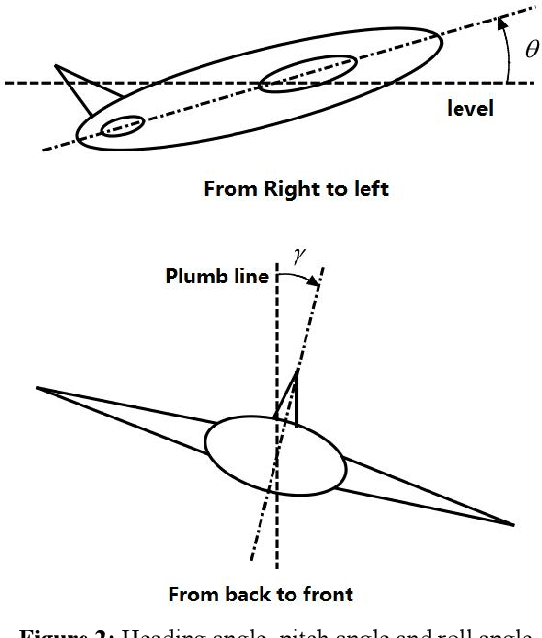
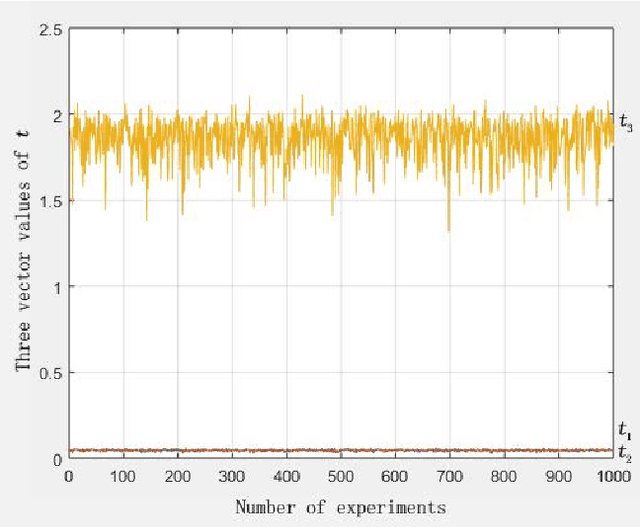
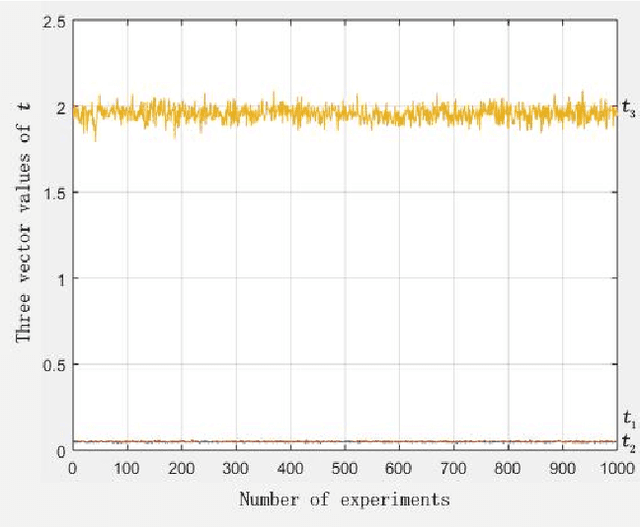
In this paper, we propose a method to estimate the exact location of a camera in a cyber-physical system using the exact geographic coordinates of four feature points stored in QR codes(Quick response codes) and the pixel coordinates of four feature points analyzed from the QR code images taken by the camera. Firstly, the P4P(Perspective 4 Points) algorithm is designed to uniquely determine the initial pose estimation value of the QR coordinate system relative to the camera coordinate system by using the four feature points of the selected QR code. In the second step, the manifold gradient optimization algorithm is designed. The rotation matrix and displacement vector are taken as the initial values of iteration, and the iterative optimization is carried out to improve the positioning accuracy and obtain the rotation matrix and displacement vector with higher accuracy. The third step is to convert the pose of the QR coordinate system with respect to the camera coordinate system to the pose of the AGV(Automated Guided Vehicle) with respect to the world coordinate system. Finally, the performance of manifold gradient optimization algorithm and P4P analytical algorithm are simulated and compared under the same conditions.One can see that the performance of the manifold gradient optimization algorithm proposed in this paper is much better than that of the P4P analytic algorithm when the signal-to-noise ratio is small.With the increase of the signal-to-noise ratio,the performance of the P4P analytic algorithm approaches that of the manifold gradient optimization algorithm.when the noise is same,the performance of manifold gradient optimization algorithm is better when there are more feature points.
sqSGD: Locally Private and Communication Efficient Federated Learning
Jun 22, 2022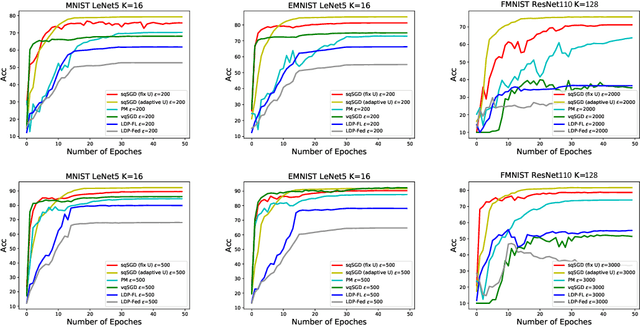
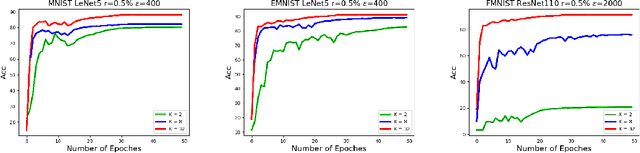
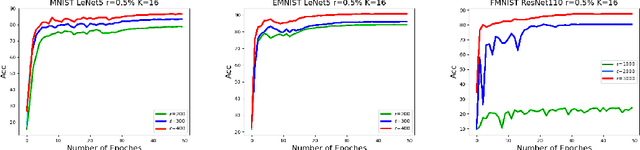
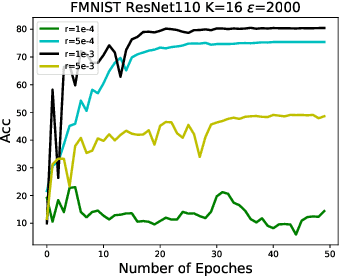
Federated learning (FL) is a technique that trains machine learning models from decentralized data sources. We study FL under local notions of privacy constraints, which provides strong protection against sensitive data disclosures via obfuscating the data before leaving the client. We identify two major concerns in designing practical privacy-preserving FL algorithms: communication efficiency and high-dimensional compatibility. We then develop a gradient-based learning algorithm called \emph{sqSGD} (selective quantized stochastic gradient descent) that addresses both concerns. The proposed algorithm is based on a novel privacy-preserving quantization scheme that uses a constant number of bits per dimension per client. Then we improve the base algorithm in three ways: first, we apply a gradient subsampling strategy that simultaneously offers better training performance and smaller communication costs under a fixed privacy budget. Secondly, we utilize randomized rotation as a preprocessing step to reduce quantization error. Thirdly, an adaptive gradient norm upper bound shrinkage strategy is adopted to improve accuracy and stabilize training. Finally, the practicality of the proposed framework is demonstrated on benchmark datasets. Experiment results show that sqSGD successfully learns large models like LeNet and ResNet with local privacy constraints. In addition, with fixed privacy and communication level, the performance of sqSGD significantly dominates that of various baseline algorithms.
SHORING: Design Provable Conditional High-Order Interaction Network via Symbolic Testing
Jul 03, 2021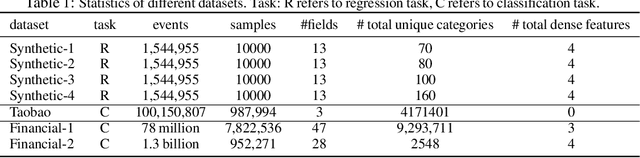
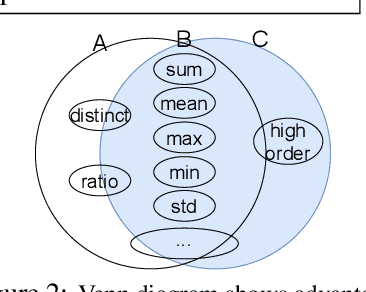
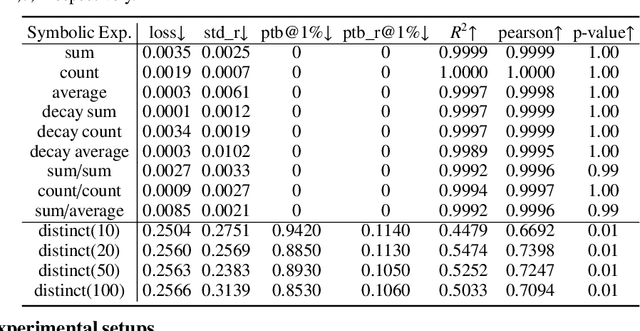
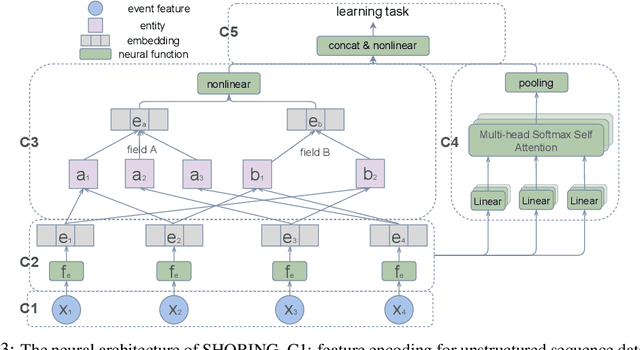
Deep learning provides a promising way to extract effective representations from raw data in an end-to-end fashion and has proven its effectiveness in various domains such as computer vision, natural language processing, etc. However, in domains such as content/product recommendation and risk management, where sequence of event data is the most used raw data form and experts derived features are more commonly used, deep learning models struggle to dominate the game. In this paper, we propose a symbolic testing framework that helps to answer the question of what kinds of expert-derived features could be learned by a neural network. Inspired by this testing framework, we introduce an efficient architecture named SHORING, which contains two components: \textit{event network} and \textit{sequence network}. The \textit{event} network learns arbitrarily yet efficiently high-order \textit{event-level} embeddings via a provable reparameterization trick, the \textit{sequence} network aggregates from sequence of \textit{event-level} embeddings. We argue that SHORING is capable of learning certain standard symbolic expressions which the standard multi-head self-attention network fails to learn, and conduct comprehensive experiments and ablation studies on four synthetic datasets and three real-world datasets. The results show that SHORING empirically outperforms the state-of-the-art methods.
Bilinear Representation for Language-based Image Editing Using Conditional Generative Adversarial Networks
Mar 18, 2019
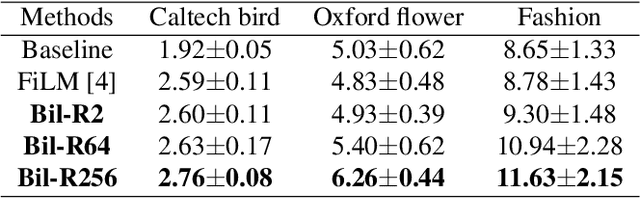
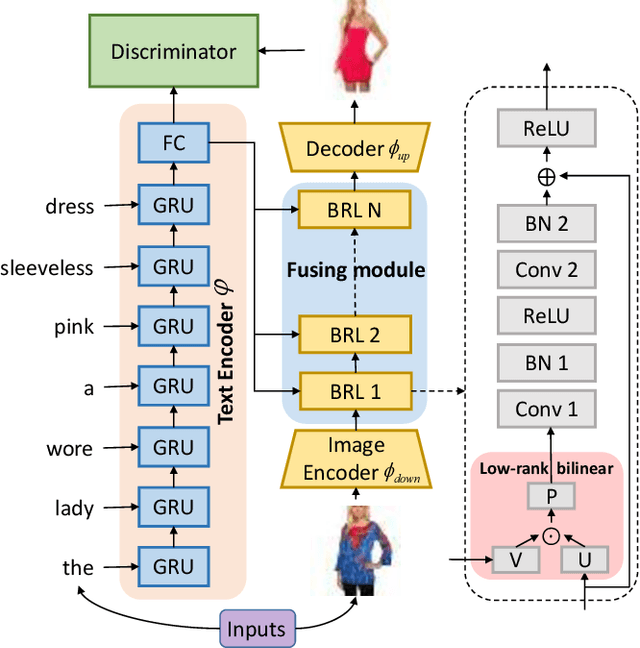

The task of Language-Based Image Editing (LBIE) aims at generating a target image by editing the source image based on the given language description. The main challenge of LBIE is to disentangle the semantics in image and text and then combine them to generate realistic images. Therefore, the editing performance is heavily dependent on the learned representation. In this work, conditional generative adversarial network (cGAN) is utilized for LBIE. We find that existing conditioning methods in cGAN lack of representation power as they cannot learn the second-order correlation between two conditioning vectors. To solve this problem, we propose an improved conditional layer named Bilinear Residual Layer (BRL) to learning more powerful representations for LBIE task. Qualitative and quantitative comparisons demonstrate that our method can generate images with higher quality when compared to previous LBIE techniques.
Sensitivity based Neural Networks Explanations
Dec 03, 2018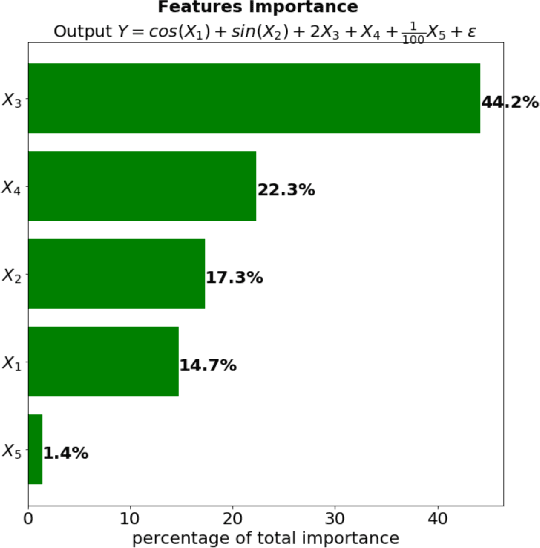
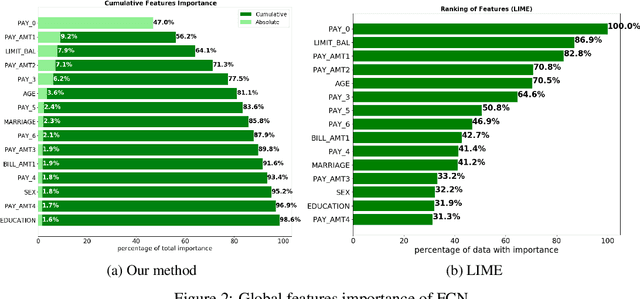
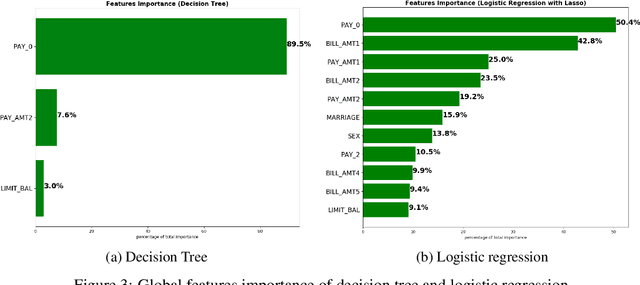
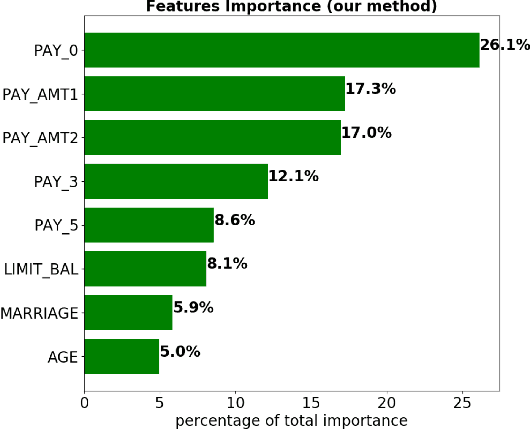
Although neural networks can achieve very high predictive performance on various different tasks such as image recognition or natural language processing, they are often considered as opaque "black boxes". The difficulty of interpreting the predictions of a neural network often prevents its use in fields where explainability is important, such as the financial industry where regulators and auditors often insist on this aspect. In this paper, we present a way to assess the relative input features importance of a neural network based on the sensitivity of the model output with respect to its input. This method has the advantage of being fast to compute, it can provide both global and local levels of explanations and is applicable for many types of neural network architectures. We illustrate the performance of this method on both synthetic and real data and compare it with other interpretation techniques. This method is implemented into an open-source Python package that allows its users to easily generate and visualize explanations for their neural networks.
Automatic Vertebra Labeling in Large-Scale 3D CT using Deep Image-to-Image Network with Message Passing and Sparsity Regularization
May 17, 2017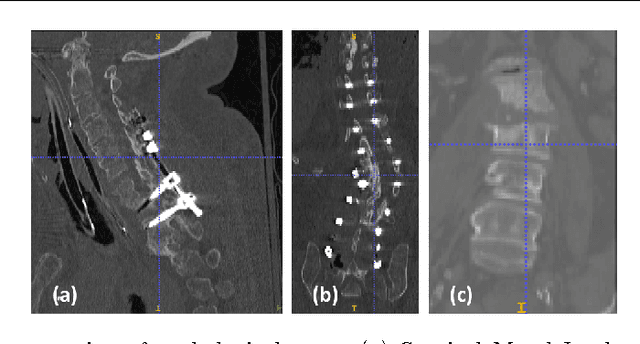
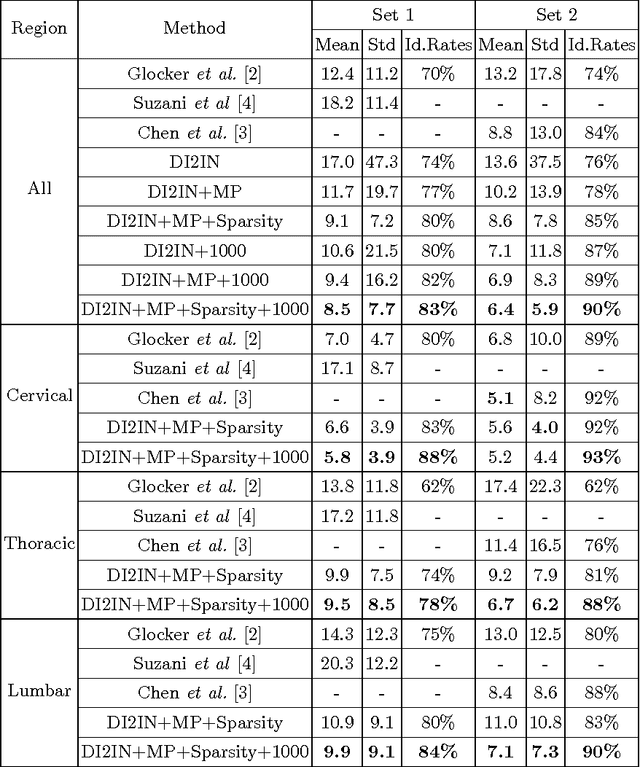

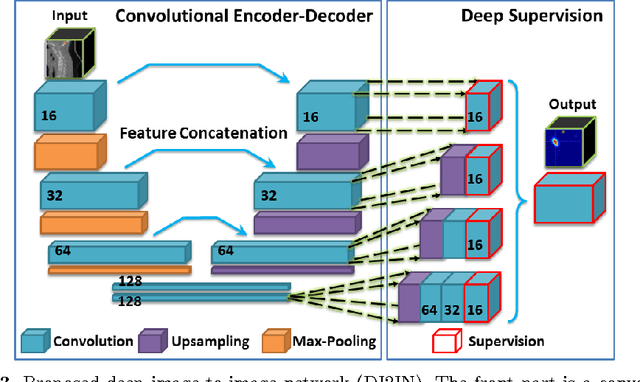
Automatic localization and labeling of vertebra in 3D medical images plays an important role in many clinical tasks, including pathological diagnosis, surgical planning and postoperative assessment. However, the unusual conditions of pathological cases, such as the abnormal spine curvature, bright visual imaging artifacts caused by metal implants, and the limited field of view, increase the difficulties of accurate localization. In this paper, we propose an automatic and fast algorithm to localize and label the vertebra centroids in 3D CT volumes. First, we deploy a deep image-to-image network (DI2IN) to initialize vertebra locations, employing the convolutional encoder-decoder architecture together with multi-level feature concatenation and deep supervision. Next, the centroid probability maps from DI2IN are iteratively evolved with the message passing schemes based on the mutual relation of vertebra centroids. Finally, the localization results are refined with sparsity regularization. The proposed method is evaluated on a public dataset of 302 spine CT volumes with various pathologies. Our method outperforms other state-of-the-art methods in terms of localization accuracy. The run time is around 3 seconds on average per case. To further boost the performance, we retrain the DI2IN on additional 1000+ 3D CT volumes from different patients. To the best of our knowledge, this is the first time more than 1000 3D CT volumes with expert annotation are adopted in experiments for the anatomic landmark detection tasks. Our experimental results show that training with such a large dataset significantly improves the performance and the overall identification rate, for the first time by our knowledge, reaches 90 %.
Interval Forecasting of Electricity Demand: A Novel Bivariate EMD-based Support Vector Regression Modeling Framework
Jun 15, 2014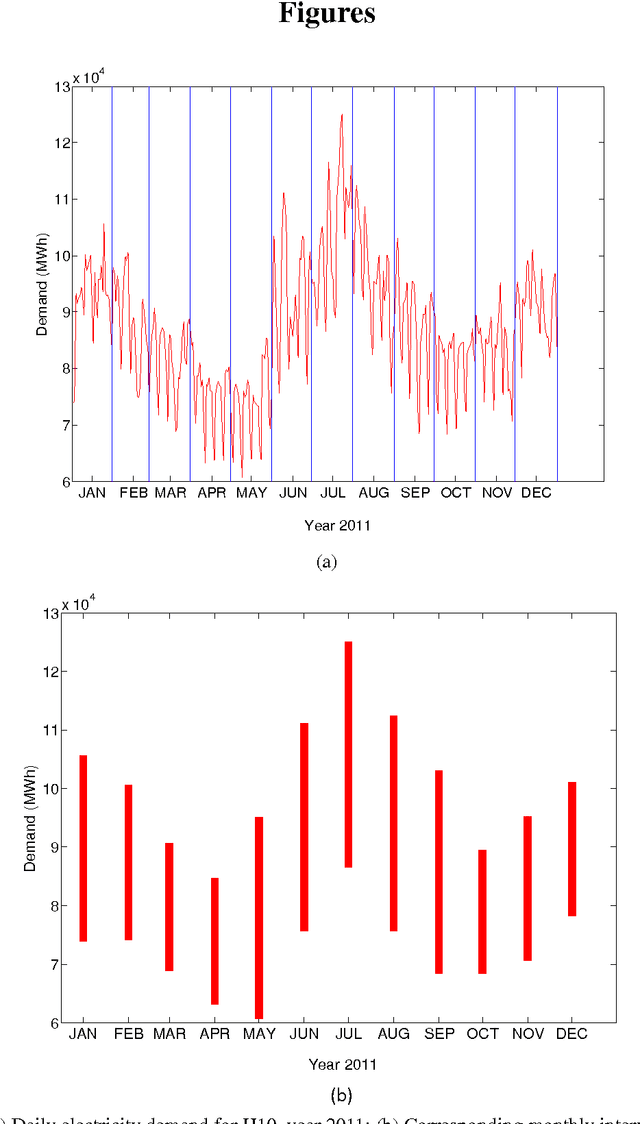
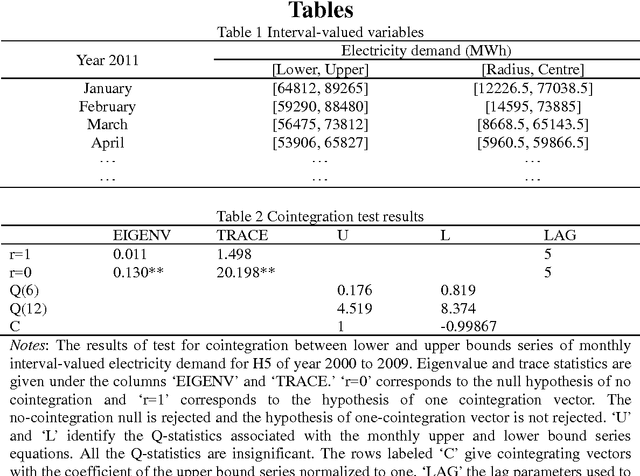
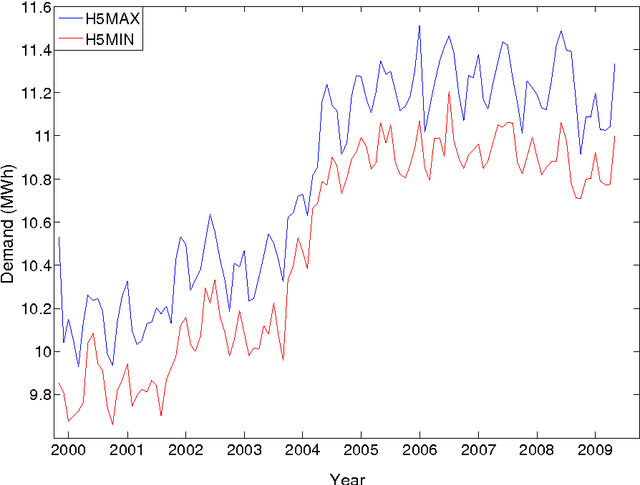
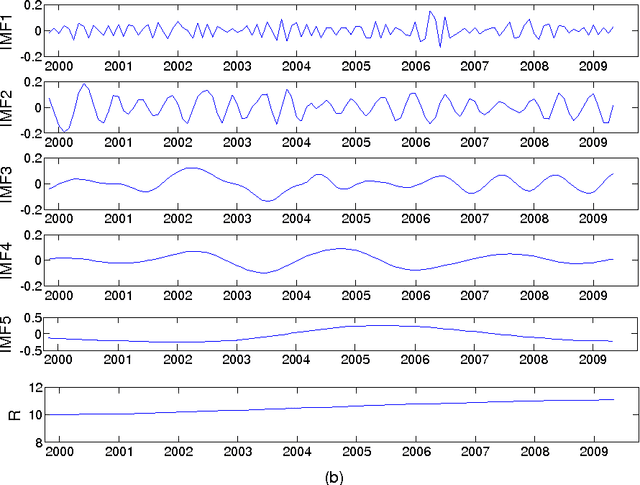
Highly accurate interval forecasting of electricity demand is fundamental to the success of reducing the risk when making power system planning and operational decisions by providing a range rather than point estimation. In this study, a novel modeling framework integrating bivariate empirical mode decomposition (BEMD) and support vector regression (SVR), extended from the well-established empirical mode decomposition (EMD) based time series modeling framework in the energy demand forecasting literature, is proposed for interval forecasting of electricity demand. The novelty of this study arises from the employment of BEMD, a new extension of classical empirical model decomposition (EMD) destined to handle bivariate time series treated as complex-valued time series, as decomposition method instead of classical EMD only capable of decomposing one-dimensional single-valued time series. This proposed modeling framework is endowed with BEMD to decompose simultaneously both the lower and upper bounds time series, constructed in forms of complex-valued time series, of electricity demand on a monthly per hour basis, resulting in capturing the potential interrelationship between lower and upper bounds. The proposed modeling framework is justified with monthly interval-valued electricity demand data per hour in Pennsylvania-New Jersey-Maryland Interconnection, indicating it as a promising method for interval-valued electricity demand forecasting.
Multi-Step-Ahead Time Series Prediction using Multiple-Output Support Vector Regression
Jan 11, 2014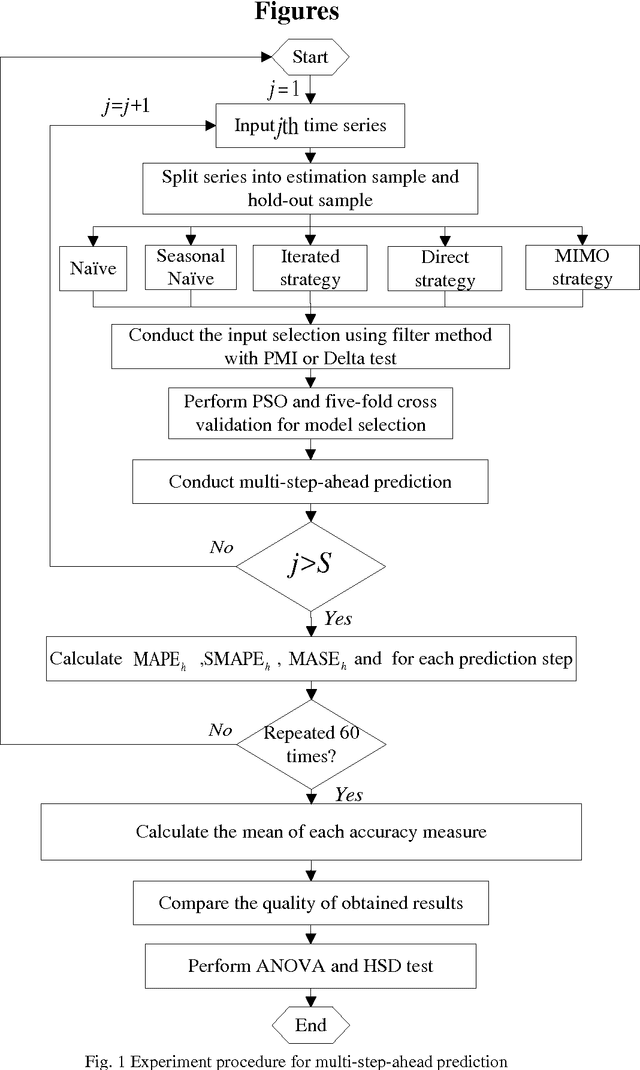
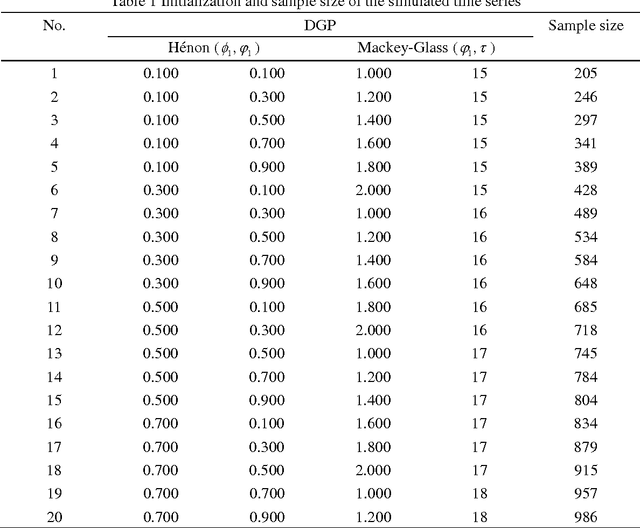
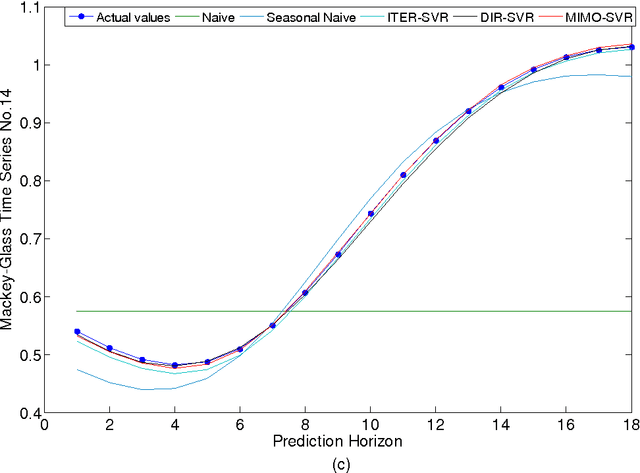
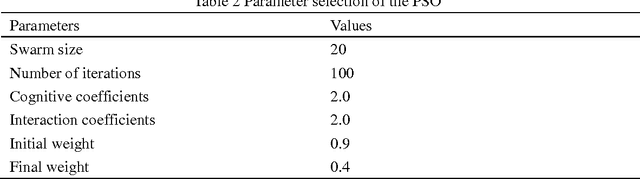
Accurate time series prediction over long future horizons is challenging and of great interest to both practitioners and academics. As a well-known intelligent algorithm, the standard formulation of Support Vector Regression (SVR) could be taken for multi-step-ahead time series prediction, only relying either on iterated strategy or direct strategy. This study proposes a novel multiple-step-ahead time series prediction approach which employs multiple-output support vector regression (M-SVR) with multiple-input multiple-output (MIMO) prediction strategy. In addition, the rank of three leading prediction strategies with SVR is comparatively examined, providing practical implications on the selection of the prediction strategy for multi-step-ahead forecasting while taking SVR as modeling technique. The proposed approach is validated with the simulated and real datasets. The quantitative and comprehensive assessments are performed on the basis of the prediction accuracy and computational cost. The results indicate that: 1) the M-SVR using MIMO strategy achieves the best accurate forecasts with accredited computational load, 2) the standard SVR using direct strategy achieves the second best accurate forecasts, but with the most expensive computational cost, and 3) the standard SVR using iterated strategy is the worst in terms of prediction accuracy, but with the least computational cost.
Does Restraining End Effect Matter in EMD-Based Modeling Framework for Time Series Prediction? Some Experimental Evidences
Jan 11, 2014Following the "decomposition-and-ensemble" principle, the empirical mode decomposition (EMD)-based modeling framework has been widely used as a promising alternative for nonlinear and nonstationary time series modeling and prediction. The end effect, which occurs during the sifting process of EMD and is apt to distort the decomposed sub-series and hurt the modeling process followed, however, has been ignored in previous studies. Addressing the end effect issue, this study proposes to incorporate end condition methods into EMD-based decomposition and ensemble modeling framework for one- and multi-step ahead time series prediction. Four well-established end condition methods, Mirror method, Coughlin's method, Slope-based method, and Rato's method, are selected, and support vector regression (SVR) is employed as the modeling technique. For the purpose of justification and comparison, well-known NN3 competition data sets are used and four well-established prediction models are selected as benchmarks. The experimental results demonstrated that significant improvement can be achieved by the proposed EMD-based SVR models with end condition methods. The EMD-SBM-SVR model and EMD-Rato-SVR model, in particular, achieved the best prediction performances in terms of goodness of forecast measures and equality of accuracy of competing forecasts test.
* 28 pages