 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity based Neural Networks Explanations
Paper and Code
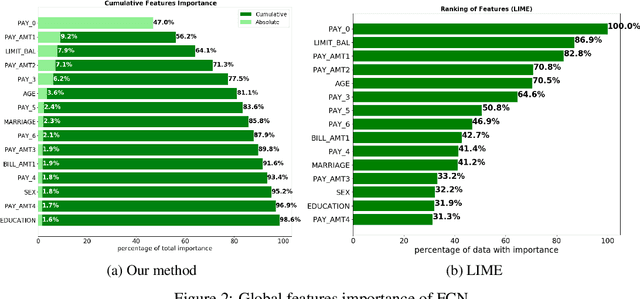
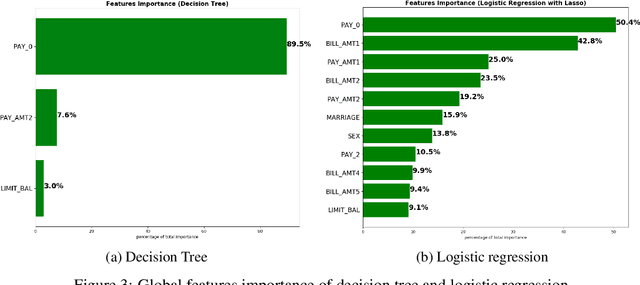
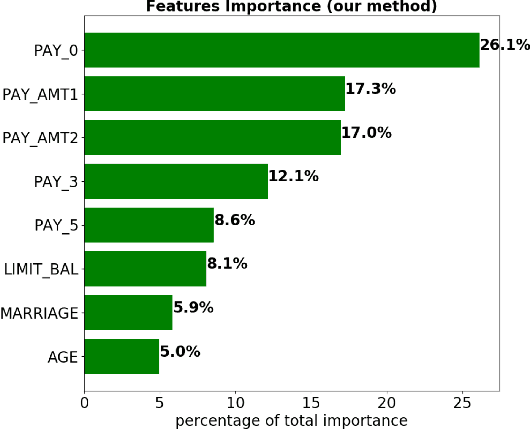
Dec 03, 2018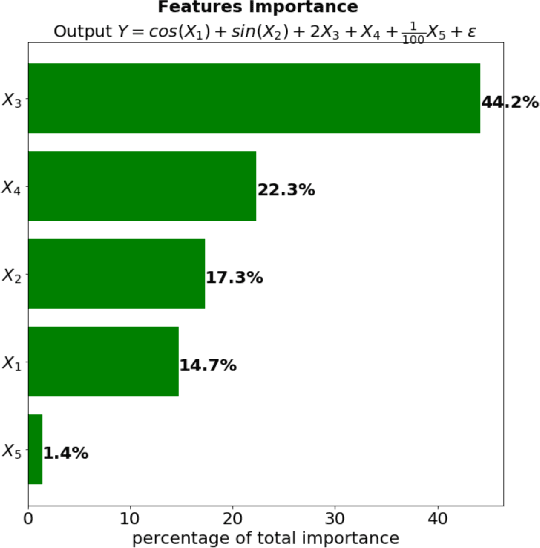
Although neural networks can achieve very high predictive performance on various different tasks such as image recognition or natural language processing, they are often considered as opaque "black boxes". The difficulty of interpreting the predictions of a neural network often prevents its use in fields where explainability is important, such as the financial industry where regulators and auditors often insist on this aspect. In this paper, we present a way to assess the relative input features importance of a neural network based on the sensitivity of the model output with respect to its input. This method has the advantage of being fast to compute, it can provide both global and local levels of explanations and is applicable for many types of neural network architectures. We illustrate the performance of this method on both synthetic and real data and compare it with other interpretation techniques. This method is implemented into an open-source Python package that allows its users to easily generate and visualize explanations for their neural networks.