 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDR-CIR: Semantic Debias Retrieval Framework for Training-Free Zero-Shot Composed Image Retrieval
Feb 05, 2026Composed Image Retrieval (CIR) aims to retrieve a target image from a query composed of a reference image and modification text. Recent training-free zero-shot methods often employ Multimodal Large Language Models (MLLMs) with Chain-of-Thought (CoT) to compose a target image description for retrieval. However, due to the fuzzy matching nature of ZS-CIR, the generated description is prone to semantic bias relative to the target image. We propose SDR-CIR, a training-free Semantic Debias Ranking method based on CoT reasoning. First, Selective CoT guides the MLLM to extract visual content relevant to the modification text during image understanding, thereby reducing visual noise at the source. We then introduce a Semantic Debias Ranking with two steps, Anchor and Debias, to mitigate semantic bias. In the Anchor step, we fuse reference image features with target description features to reinforce useful semantics and supplement omitted cues. In the Debias step, we explicitly model the visual semantic contribution of the reference image to the description and incorporate it into the similarity score as a penalty term. By supplementing omitted cues while suppressing redundancy, SDR-CIR mitigates semantic bias and improves retrieval performance. Experiments on three standard CIR benchmarks show that SDR-CIR achieves state-of-the-art results among one-stage methods while maintaining high efficiency. The code is publicly available at https://github.com/suny105/SDR-CIR.
LOFA: Online Influence Maximization under Full-Bandit Feedback using Lazy Forward Selection
Jan 02, 2026We study the problem of influence maximization (IM) in an online setting, where the goal is to select a subset of nodes$\unicode{x2014}$called the seed set$\unicode{x2014}$at each time step over a fixed time horizon, subject to a cardinality budget constraint, to maximize the expected cumulative influence. We operate under a full-bandit feedback model, where only the influence of the chosen seed set at each time step is observed, with no additional structural information about the network or diffusion process. It is well-established that the influence function is submodular, and existing algorithms exploit this property to achieve low regret. In this work, we leverage this property further and propose the Lazy Online Forward Algorithm (LOFA), which achieves a lower empirical regret. We conduct experiments on a real-world social network to demonstrate that LOFA achieves superior performance compared to existing bandit algorithms in terms of cumulative regret and instantaneous reward.
LGD: Leveraging Generative Descriptions for Zero-Shot Referring Image Segmentation
Apr 20, 2025
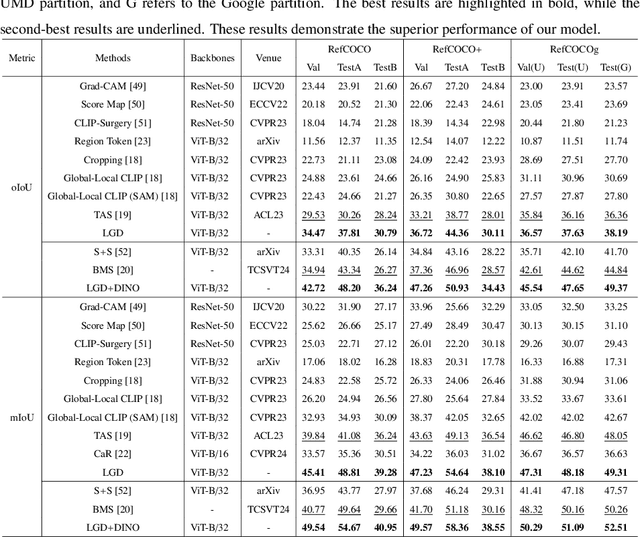


Zero-shot referring image segmentation aims to locate and segment the target region based on a referring expression, with the primary challenge of aligning and matching semantics across visual and textual modalities without training. Previous works address this challenge by utilizing Vision-Language Models and mask proposal networks for region-text matching. However, this paradigm may lead to incorrect target localization due to the inherent ambiguity and diversity of free-form referring expressions. To alleviate this issue, we present LGD (Leveraging Generative Descriptions), a framework that utilizes the advanced language generation capabilities of Multi-Modal Large Language Models to enhance region-text matching performance in Vision-Language Models. Specifically, we first design two kinds of prompts, the attribute prompt and the surrounding prompt, to guide the Multi-Modal Large Language Models in generating descriptions related to the crucial attributes of the referent object and the details of surrounding objects, referred to as attribute description and surrounding description, respectively. Secondly, three visual-text matching scores are introduced to evaluate the similarity between instance-level visual features and textual features, which determines the mask most associated with the referring expression. The proposed method achieves new state-of-the-art performance on three public datasets RefCOCO, RefCOCO+ and RefCOCOg, with maximum improvements of 9.97% in oIoU and 11.29% in mIoU compared to previous methods.
Stealthy and Robust Backdoor Attack against 3D Point Clouds through Additional Point Features
Dec 10, 2024Recently, 3D backdoor attacks have posed a substantial threat to 3D Deep Neural Networks (3D DNNs) designed for 3D point clouds, which are extensively deployed in various security-critical applications. Although the existing 3D backdoor attacks achieved high attack performance, they remain vulnerable to preprocessing-based defenses (e.g., outlier removal and rotation augmentation) and are prone to detection by human inspection. In pursuit of a more challenging-to-defend and stealthy 3D backdoor attack, this paper introduces the Stealthy and Robust Backdoor Attack (SRBA), which ensures robustness and stealthiness through intentional design considerations. The key insight of our attack involves applying a uniform shift to the additional point features of point clouds (e.g., reflection intensity) widely utilized as part of inputs for 3D DNNs as the trigger. Without altering the geometric information of the point clouds, our attack ensures visual consistency between poisoned and benign samples, and demonstrate robustness against preprocessing-based defenses. In addition, to automate our attack, we employ Bayesian Optimization (BO) to identify the suitable trigger. Extensive experiments suggest that SRBA achieves an attack success rate (ASR) exceeding 94% in all cases, and significantly outperforms previous SOTA methods when multiple preprocessing operations are applied during training.
Efficient User Sequence Learning for Online Services via Compressed Graph Neural Networks
Jun 05, 2024
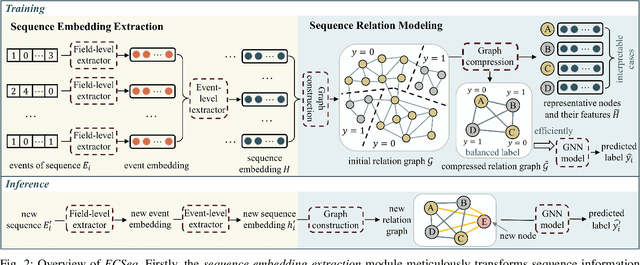
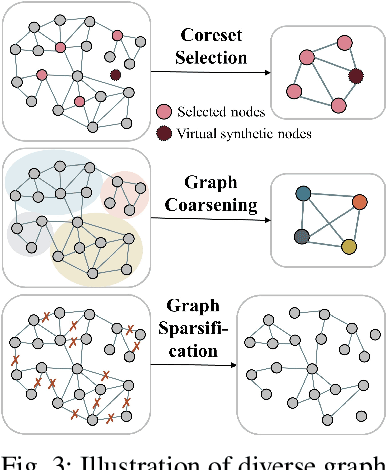
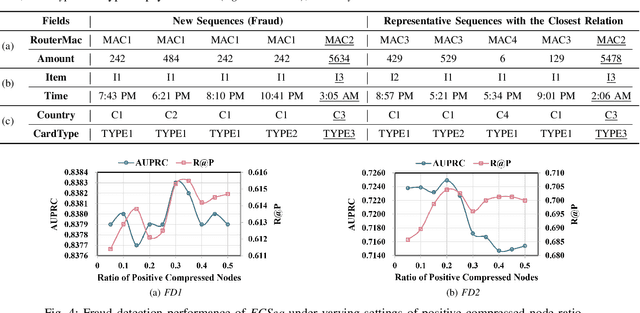
Learning representations of user behavior sequences is crucial for various online services, such as online fraudulent transaction detection mechanisms. Graph Neural Networks (GNNs) have been extensively applied to model sequence relationships, and extract information from similar sequences. While user behavior sequence data volume is usually huge for online applications, directly applying GNN models may lead to substantial computational overhead during both the training and inference stages and make it challenging to meet real-time requirements for online services. In this paper, we leverage graph compression techniques to alleviate the efficiency issue. Specifically, we propose a novel unified framework called ECSeq, to introduce graph compression techniques into relation modeling for user sequence representation learning. The key module of ECSeq is sequence relation modeling, which explores relationships among sequences to enhance sequence representation learning, and employs graph compression algorithms to achieve high efficiency and scalability. ECSeq also exhibits plug-and-play characteristics, seamlessly augmenting pre-trained sequence representation models without modifications. Empirical experiments on both sequence classification and regression tasks demonstrate the effectiveness of ECSeq. Specifically, with an additional training time of tens of seconds in total on 100,000+ sequences and inference time preserved within $10^{-4}$ seconds/sample, ECSeq improves the prediction R@P$_{0.9}$ of the widely used LSTM by $\sim 5\%$.
Knowledge-inspired Subdomain Adaptation for Cross-Domain Knowledge Transfer
Aug 17, 2023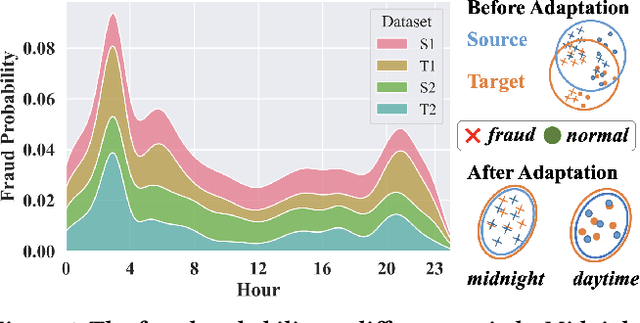
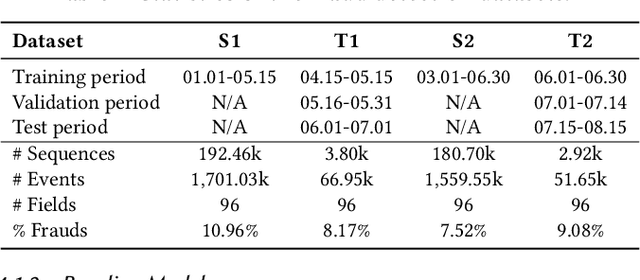
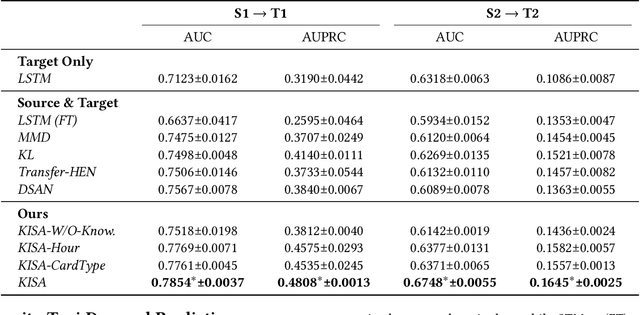
Most state-of-the-art deep domain adaptation techniques align source and target samples in a global fashion. That is, after alignment, each source sample is expected to become similar to any target sample. However, global alignment may not always be optimal or necessary in practice. For example, consider cross-domain fraud detection, where there are two types of transactions: credit and non-credit. Aligning credit and non-credit transactions separately may yield better performance than global alignment, as credit transactions are unlikely to exhibit patterns similar to non-credit transactions. To enable such fine-grained domain adaption, we propose a novel Knowledge-Inspired Subdomain Adaptation (KISA) framework. In particular, (1) We provide the theoretical insight that KISA minimizes the shared expected loss which is the premise for the success of domain adaptation methods. (2) We propose the knowledge-inspired subdomain division problem that plays a crucial role in fine-grained domain adaption. (3) We design a knowledge fusion network to exploit diverse domain knowledge. Extensive experiments demonstrate that KISA achieves remarkable results on fraud detection and traffic demand prediction tasks.
SHORING: Design Provable Conditional High-Order Interaction Network via Symbolic Testing
Jul 03, 2021
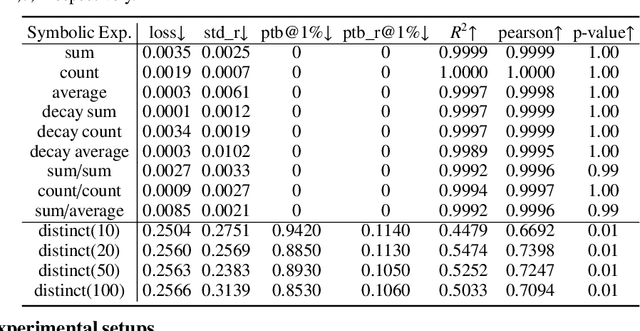
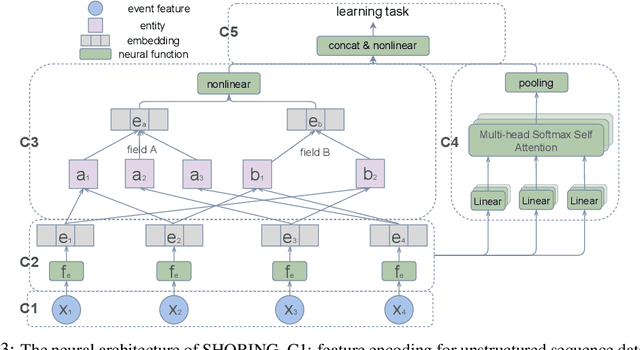
Deep learning provides a promising way to extract effective representations from raw data in an end-to-end fashion and has proven its effectiveness in various domains such as computer vision, natural language processing, etc. However, in domains such as content/product recommendation and risk management, where sequence of event data is the most used raw data form and experts derived features are more commonly used, deep learning models struggle to dominate the game. In this paper, we propose a symbolic testing framework that helps to answer the question of what kinds of expert-derived features could be learned by a neural network. Inspired by this testing framework, we introduce an efficient architecture named SHORING, which contains two components: \textit{event network} and \textit{sequence network}. The \textit{event} network learns arbitrarily yet efficiently high-order \textit{event-level} embeddings via a provable reparameterization trick, the \textit{sequence} network aggregates from sequence of \textit{event-level} embeddings. We argue that SHORING is capable of learning certain standard symbolic expressions which the standard multi-head self-attention network fails to learn, and conduct comprehensive experiments and ablation studies on four synthetic datasets and three real-world datasets. The results show that SHORING empirically outperforms the state-of-the-art methods.