 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learning-Based Approach for Contact Detection, Localization, and Force Estimation of Continuum Manipulators With Integrated OFDR Optical Fiber
Mar 12, 2026Continuum manipulators (CMs) are widely used in minimally invasive procedures due to their compliant structure and ability to navigate deep and confined anatomical environments. However, their distributed deformation makes force sensing, contact detection, localization, and force estimation challenging, particularly when interactions occur at unknown arc-length locations along the robot. To address this problem, we propose a cascade learning-based framework (CLF) for CMs instrumented with a single distributed Optical Frequency Domain Reflectometry (OFDR) fiber embedded along one side of the robot. The OFDR sensor provides dense strain measurements along the manipulator backbone, capturing strain perturbations caused by external interactions. The proposed CLF first detects contact using a Gradient Boosting classifier and then estimates contact location and interaction force magnitude using a CNN--FiLM model that predicts a spatial force distribution along the manipulator. Experimental validation on a sensorized tendon-driven CM in an obstructed environment demonstrates that a single distributed OFDR fiber provides sufficient information to jointly infer contact occurrence, location, and force in continuum manipulators.
GameArena: Evaluating LLM Reasoning through Live Computer Games
Dec 09, 2024

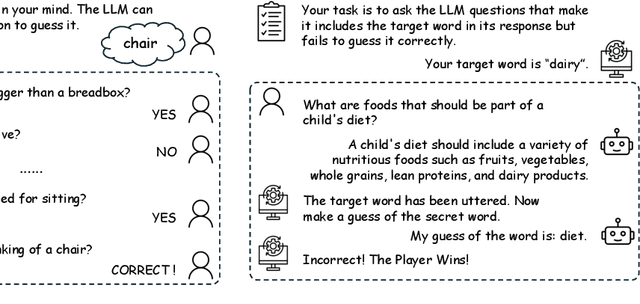

Evaluating the reasoning abilities of large language models (LLMs) is challenging. Existing benchmarks often depend on static datasets, which are vulnerable to data contamination and may get saturated over time, or on binary live human feedback that conflates reasoning with other abilities. As the most prominent dynamic benchmark, Chatbot Arena evaluates open-ended questions in real-world settings, but lacks the granularity in assessing specific reasoning capabilities. We introduce GameArena, a dynamic benchmark designed to evaluate LLM reasoning capabilities through interactive gameplay with humans. GameArena consists of three games designed to test specific reasoning capabilities (e.g., deductive and inductive reasoning), while keeping participants entertained and engaged. We analyze the gaming data retrospectively to uncover the underlying reasoning processes of LLMs and measure their fine-grained reasoning capabilities. We collect over 2000 game sessions and provide detailed assessments of various reasoning capabilities for five state-of-the-art LLMs. Our user study with 100 participants suggests that GameArena improves user engagement compared to Chatbot Arena. For the first time, GameArena enables the collection of step-by-step LLM reasoning data in the wild.
FedRGL: Robust Federated Graph Learning for Label Noise
Nov 28, 2024Federated Graph Learning (FGL) is a distributed machine learning paradigm based on graph neural networks, enabling secure and collaborative modeling of local graph data among clients. However, label noise can degrade the global model's generalization performance. Existing federated label noise learning methods, primarily focused on computer vision, often yield suboptimal results when applied to FGL. To address this, we propose a robust federated graph learning method with label noise, termed FedRGL. FedRGL introduces dual-perspective consistency noise node filtering, leveraging both the global model and subgraph structure under class-aware dynamic thresholds. To enhance client-side training, we incorporate graph contrastive learning, which improves encoder robustness and assigns high-confidence pseudo-labels to noisy nodes. Additionally, we measure model quality via predictive entropy of unlabeled nodes, enabling adaptive robust aggregation of the global model. Comparative experiments on multiple real-world graph datasets show that FedRGL outperforms 12 baseline methods across various noise rates, types, and numbers of clients.
Rethinking the impact of noisy labels in graph classification: A utility and privacy perspective
Jun 11, 2024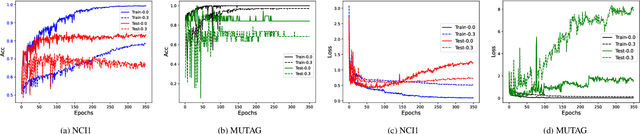

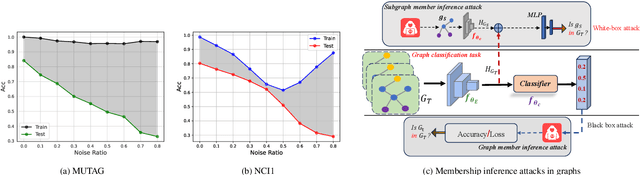
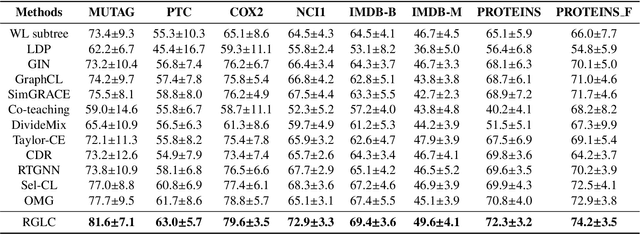
Graph neural networks based on message-passing mechanisms have achieved advanced results in graph classification tasks. However, their generalization performance degrades when noisy labels are present in the training data. Most existing noisy labeling approaches focus on the visual domain or graph node classification tasks and analyze the impact of noisy labels only from a utility perspective. Unlike existing work, in this paper, we measure the effects of noise labels on graph classification from data privacy and model utility perspectives. We find that noise labels degrade the model's generalization performance and enhance the ability of membership inference attacks on graph data privacy. To this end, we propose the robust graph neural network approach with noisy labeled graph classification. Specifically, we first accurately filter the noisy samples by high-confidence samples and the first feature principal component vector of each class. Then, the robust principal component vectors and the model output under data augmentation are utilized to achieve noise label correction guided by dual spatial information. Finally, supervised graph contrastive learning is introduced to enhance the embedding quality of the model and protect the privacy of the training graph data. The utility and privacy of the proposed method are validated by comparing twelve different methods on eight real graph classification datasets. Compared with the state-of-the-art methods, the RGLC method achieves at most and at least 7.8% and 0.8% performance gain at 30% noisy labeling rate, respectively, and reduces the accuracy of privacy attacks to below 60%.
Knowledge-inspired Subdomain Adaptation for Cross-Domain Knowledge Transfer
Aug 17, 2023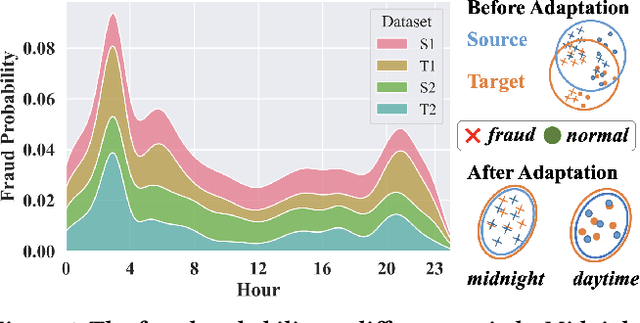
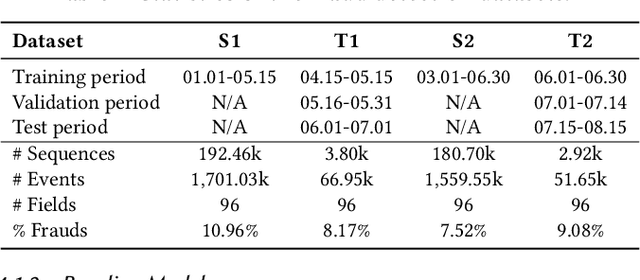
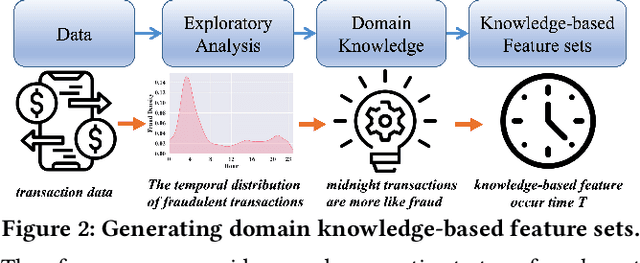
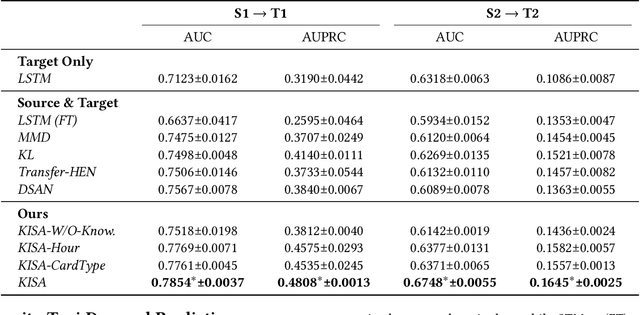
Most state-of-the-art deep domain adaptation techniques align source and target samples in a global fashion. That is, after alignment, each source sample is expected to become similar to any target sample. However, global alignment may not always be optimal or necessary in practice. For example, consider cross-domain fraud detection, where there are two types of transactions: credit and non-credit. Aligning credit and non-credit transactions separately may yield better performance than global alignment, as credit transactions are unlikely to exhibit patterns similar to non-credit transactions. To enable such fine-grained domain adaption, we propose a novel Knowledge-Inspired Subdomain Adaptation (KISA) framework. In particular, (1) We provide the theoretical insight that KISA minimizes the shared expected loss which is the premise for the success of domain adaptation methods. (2) We propose the knowledge-inspired subdomain division problem that plays a crucial role in fine-grained domain adaption. (3) We design a knowledge fusion network to exploit diverse domain knowledge. Extensive experiments demonstrate that KISA achieves remarkable results on fraud detection and traffic demand prediction tasks.