 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Parents' Desires in Moderating Children's Interactions with GenAI Chatbots through LLM-Generated Probes
Mar 04, 2026This paper studies how parents want to moderate children's interactions with Generative AI chatbots, with the goal of informing the design of future GenAI parental control tools. We first used an LLM to generate synthetic child-GenAI chatbot interaction scenarios and worked with four parents to validate their realism. From this dataset, we carefully selected 12 diverse examples that evoked varying levels of concern and were rated the most realistic. Each example included a prompt and a GenAI chatbot response. We presented these to parents (N=24) and asked whether they found them concerning, why, and how they would prefer the responses to be modified and communicated. Our findings reveal three key insights: (1) parents express concern about interactions that current GenAI chatbot parental controls neglect; (2) parents want fine-grained transparency and moderation at the conversation level; and (3) parents need personalized controls that adapt to their desired strategies and children's ages.
HumanStudy-Bench: Towards AI Agent Design for Participant Simulation
Jan 31, 2026Large language models (LLMs) are increasingly used as simulated participants in social science experiments, but their behavior is often unstable and highly sensitive to design choices. Prior evaluations frequently conflate base-model capabilities with experimental instantiation, obscuring whether outcomes reflect the model itself or the agent setup. We instead frame participant simulation as an agent-design problem over full experimental protocols, where an agent is defined by a base model and a specification (e.g., participant attributes) that encodes behavioral assumptions. We introduce HUMANSTUDY-BENCH, a benchmark and execution engine that orchestrates LLM-based agents to reconstruct published human-subject experiments via a Filter--Extract--Execute--Evaluate pipeline, replaying trial sequences and running the original analysis pipeline in a shared runtime that preserves the original statistical procedures end to end. To evaluate fidelity at the level of scientific inference, we propose new metrics to quantify how much human and agent behaviors agree. We instantiate 12 foundational studies as an initial suite in this dynamic benchmark, spanning individual cognition, strategic interaction, and social psychology, and covering more than 6,000 trials with human samples ranging from tens to over 2,100 participants.
PrivacyReasoner: Can LLM Emulate a Human-like Privacy Mind?
Jan 14, 2026This paper introduces PRA, an AI-agent design for simulating how individual users form privacy concerns in response to real-world news. Moving beyond population-level sentiment analysis, PRA integrates privacy and cognitive theories to simulate user-specific privacy reasoning grounded in personal comment histories and contextual cues. The agent reconstructs each user's "privacy mind", dynamically activates relevant privacy memory through a contextual filter that emulates bounded rationality, and generates synthetic comments reflecting how that user would likely respond to new privacy scenarios. A complementary LLM-as-a-Judge evaluator, calibrated against an established privacy concern taxonomy, quantifies the faithfulness of generated reasoning. Experiments on real-world Hacker News discussions show that \PRA outperforms baseline agents in privacy concern prediction and captures transferable reasoning patterns across domains including AI, e-commerce, and healthcare.
General Modular Harness for LLM Agents in Multi-Turn Gaming Environments
Jul 15, 2025We introduce a modular harness design for LLM agents that composes of perception, memory, and reasoning components, enabling a single LLM or VLM backbone to tackle a wide spectrum of multi turn gaming environments without domain-specific engineering. Using classic and modern game suites as low-barrier, high-diversity testbeds, our framework provides a unified workflow for analyzing how each module affects performance across dynamic interactive settings. Extensive experiments demonstrate that the harness lifts gameplay performance consistently over un-harnessed baselines and reveals distinct contribution patterns, for example, memory dominates in long-horizon puzzles while perception is critical in vision noisy arcades. These findings highlight the effectiveness of our modular harness design in advancing general-purpose agent, given the familiarity and ubiquity of games in everyday human experience.
lmgame-Bench: How Good are LLMs at Playing Games?
May 21, 2025Playing video games requires perception, memory, and planning, exactly the faculties modern large language model (LLM) agents are expected to master. We study the major challenges in using popular video games to evaluate modern LLMs and find that directly dropping LLMs into games cannot make an effective evaluation, for three reasons -- brittle vision perception, prompt sensitivity, and potential data contamination. We introduce lmgame-Bench to turn games into reliable evaluations. lmgame-Bench features a suite of platformer, puzzle, and narrative games delivered through a unified Gym-style API and paired with lightweight perception and memory scaffolds, and is designed to stabilize prompt variance and remove contamination. Across 13 leading models, we show lmgame-Bench is challenging while still separating models well. Correlation analysis shows that every game probes a unique blend of capabilities often tested in isolation elsewhere. More interestingly, performing reinforcement learning on a single game from lmgame-Bench transfers both to unseen games and to external planning tasks. Our evaluation code is available at https://github.com/lmgame-org/GamingAgent/lmgame-bench.
Decentralized Arena: Towards Democratic and Scalable Automatic Evaluation of Language Models
May 19, 2025



The recent explosion of large language models (LLMs), each with its own general or specialized strengths, makes scalable, reliable benchmarking more urgent than ever. Standard practices nowadays face fundamental trade-offs: closed-ended question-based benchmarks (eg MMLU) struggle with saturation as newer models emerge, while crowd-sourced leaderboards (eg Chatbot Arena) rely on costly and slow human judges. Recently, automated methods (eg LLM-as-a-judge) shed light on the scalability, but risk bias by relying on one or a few "authority" models. To tackle these issues, we propose Decentralized Arena (dearena), a fully automated framework leveraging collective intelligence from all LLMs to evaluate each other. It mitigates single-model judge bias by democratic, pairwise evaluation, and remains efficient at scale through two key components: (1) a coarse-to-fine ranking algorithm for fast incremental insertion of new models with sub-quadratic complexity, and (2) an automatic question selection strategy for the construction of new evaluation dimensions. Across extensive experiments across 66 LLMs, dearena attains up to 97% correlation with human judgements, while significantly reducing the cost. Our code and data will be publicly released on https://github.com/maitrix-org/de-arena.
Predicting Quality of Video Gaming Experience Using Global-Scale Telemetry Data and Federated Learning
Dec 12, 2024



Frames Per Second (FPS) significantly affects the gaming experience. Providing players with accurate FPS estimates prior to purchase benefits both players and game developers. However, we have a limited understanding of how to predict a game's FPS performance on a specific device. In this paper, we first conduct a comprehensive analysis of a wide range of factors that may affect game FPS on a global-scale dataset to identify the determinants of FPS. This includes player-side and game-side characteristics, as well as country-level socio-economic statistics. Furthermore, recognizing that accurate FPS predictions require extensive user data, which raises privacy concerns, we propose a federated learning-based model to ensure user privacy. Each player and game is assigned a unique learnable knowledge kernel that gradually extracts latent features for improved accuracy. We also introduce a novel training and prediction scheme that allows these kernels to be dynamically plug-and-play, effectively addressing cold start issues. To train this model with minimal bias, we collected a large telemetry dataset from 224 countries and regions, 100,000 users, and 835 games. Our model achieved a mean Wasserstein distance of 0.469 between predicted and ground truth FPS distributions, outperforming all baseline methods.
GameArena: Evaluating LLM Reasoning through Live Computer Games
Dec 09, 2024

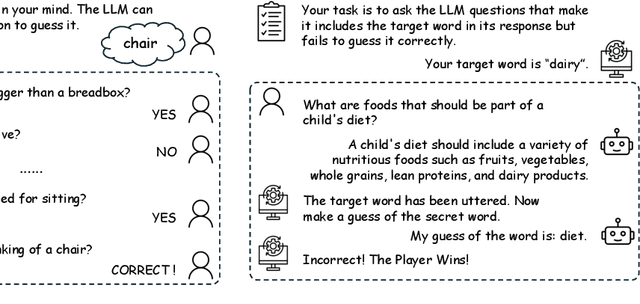

Evaluating the reasoning abilities of large language models (LLMs) is challenging. Existing benchmarks often depend on static datasets, which are vulnerable to data contamination and may get saturated over time, or on binary live human feedback that conflates reasoning with other abilities. As the most prominent dynamic benchmark, Chatbot Arena evaluates open-ended questions in real-world settings, but lacks the granularity in assessing specific reasoning capabilities. We introduce GameArena, a dynamic benchmark designed to evaluate LLM reasoning capabilities through interactive gameplay with humans. GameArena consists of three games designed to test specific reasoning capabilities (e.g., deductive and inductive reasoning), while keeping participants entertained and engaged. We analyze the gaming data retrospectively to uncover the underlying reasoning processes of LLMs and measure their fine-grained reasoning capabilities. We collect over 2000 game sessions and provide detailed assessments of various reasoning capabilities for five state-of-the-art LLMs. Our user study with 100 participants suggests that GameArena improves user engagement compared to Chatbot Arena. For the first time, GameArena enables the collection of step-by-step LLM reasoning data in the wild.
ElasticPlay: Interactive Video Summarization with Dynamic Time Budgets
Aug 23, 2017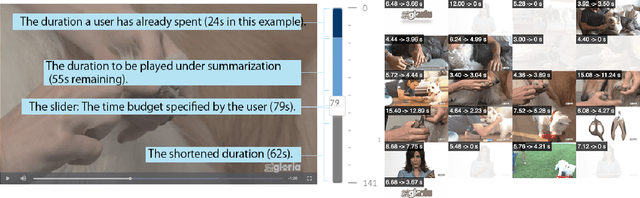
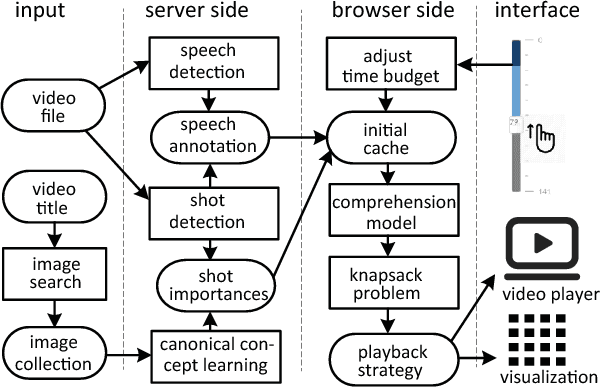
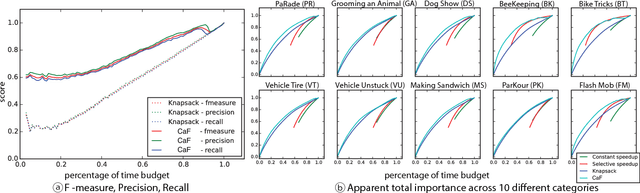
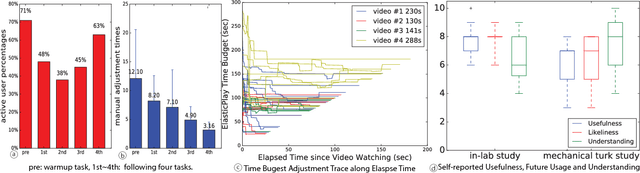
Video consumption is being shifted from sit-and-watch to selective skimming. Existing video player interfaces, however, only provide indirect manipulation to support this emerging behavior. Video summarization alleviates this issue to some extent, shortening a video based on the desired length of a summary as an input variable. But an optimal length of a summarized video is often not available in advance. Moreover, the user cannot edit the summary once it is produced, limiting its practical applications. We argue that video summarization should be an interactive, mixed-initiative process in which users have control over the summarization procedure while algorithms help users achieve their goal via video understanding. In this paper, we introduce ElasticPlay, a mixed-initiative approach that combines an advanced video summarization technique with direct interface manipulation to help users control the video summarization process. Users can specify a time budget for the remaining content while watching a video; our system then immediately updates the playback plan using our proposed cut-and-forward algorithm, determining which parts to skip or to fast-forward. This interactive process allows users to fine-tune the summarization result with immediate feedback. We show that our system outperforms existing video summarization techniques on the TVSum50 dataset. We also report two lab studies (22 participants) and a Mechanical Turk deployment study (60 participants), and show that the participants responded favorably to ElasticPlay.