 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
GameArena: Evaluating LLM Reasoning through Live Computer Games
Dec 09, 2024

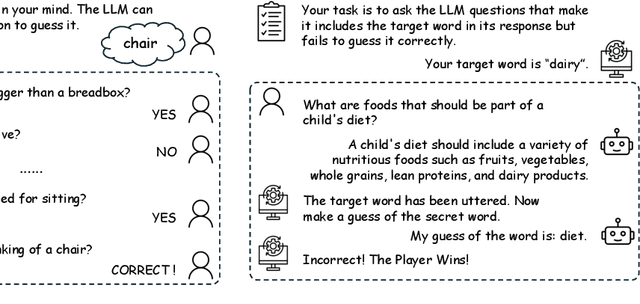

Evaluating the reasoning abilities of large language models (LLMs) is challenging. Existing benchmarks often depend on static datasets, which are vulnerable to data contamination and may get saturated over time, or on binary live human feedback that conflates reasoning with other abilities. As the most prominent dynamic benchmark, Chatbot Arena evaluates open-ended questions in real-world settings, but lacks the granularity in assessing specific reasoning capabilities. We introduce GameArena, a dynamic benchmark designed to evaluate LLM reasoning capabilities through interactive gameplay with humans. GameArena consists of three games designed to test specific reasoning capabilities (e.g., deductive and inductive reasoning), while keeping participants entertained and engaged. We analyze the gaming data retrospectively to uncover the underlying reasoning processes of LLMs and measure their fine-grained reasoning capabilities. We collect over 2000 game sessions and provide detailed assessments of various reasoning capabilities for five state-of-the-art LLMs. Our user study with 100 participants suggests that GameArena improves user engagement compared to Chatbot Arena. For the first time, GameArena enables the collection of step-by-step LLM reasoning data in the wild.
LightSeq: Sequence Level Parallelism for Distributed Training of Long Context Transformers
Oct 05, 2023Increasing the context length of large language models (LLMs) unlocks fundamentally new capabilities, but also significantly increases the memory footprints of training. Previous model-parallel systems such as Megatron-LM partition and compute different attention heads in parallel, resulting in large communication volumes, so they cannot scale beyond the number of attention heads, thereby hindering its adoption. In this paper, we introduce a new approach, LightSeq, for long-context LLMs training. LightSeq has many notable advantages. First, LightSeq partitions over the sequence dimension, hence is agnostic to model architectures and readily applicable for models with varying numbers of attention heads, such as Multi-Head, Multi-Query and Grouped-Query attention. Second, LightSeq not only requires up to 4.7x less communication than Megatron-LM on popular LLMs but also overlaps the communication with computation. To further reduce the training time, LightSeq features a novel gradient checkpointing scheme to bypass an forward computation for memory-efficient attention. We evaluate LightSeq on Llama-7B and its variants with sequence lengths from 32K to 512K. Through comprehensive experiments on single and cross-node training, we show that LightSeq achieves up to 1.24-2.01x end-to-end speedup, and a 2-8x longer sequence length on models with fewer heads, compared to Megatron-LM. Codes will be available at https://github.com/RulinShao/LightSeq.