 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGecko: An Efficient Neural Architecture Inherently Processing Sequences with Arbitrary Lengths
Jan 10, 2026Designing a unified neural network to efficiently and inherently process sequential data with arbitrary lengths is a central and challenging problem in sequence modeling. The design choices in Transformer, including quadratic complexity and weak length extrapolation, have limited their ability to scale to long sequences. In this work, we propose Gecko, a neural architecture that inherits the design of Mega and Megalodon (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability to capture long range dependencies, including timestep decay normalization, sliding chunk attention mechanism, and adaptive working memory. In a controlled pretraining comparison with Llama2 and Megalodon in the scale of 7 billion parameters and 2 trillion training tokens, Gecko achieves better efficiency and long-context scalability. Gecko reaches a training loss of 1.68, significantly outperforming Llama2-7B (1.75) and Megalodon-7B (1.70), and landing close to Llama2-13B (1.67). Notably, without relying on any context-extension techniques, Gecko exhibits inherent long-context processing and retrieval capabilities, stably handling sequences of up to 4 million tokens and retrieving information from contexts up to $4\times$ longer than its attention window. Code: https://github.com/XuezheMax/gecko-llm
K2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
Don't Let It Hallucinate: Premise Verification via Retrieval-Augmented Logical Reasoning
Apr 08, 2025Large language models (LLMs) have shown substantial capacity for generating fluent, contextually appropriate responses. However, they can produce hallucinated outputs, especially when a user query includes one or more false premises-claims that contradict established facts. Such premises can mislead LLMs into offering fabricated or misleading details. Existing approaches include pretraining, fine-tuning, and inference-time techniques that often rely on access to logits or address hallucinations after they occur. These methods tend to be computationally expensive, require extensive training data, or lack proactive mechanisms to prevent hallucination before generation, limiting their efficiency in real-time applications. We propose a retrieval-based framework that identifies and addresses false premises before generation. Our method first transforms a user's query into a logical representation, then applies retrieval-augmented generation (RAG) to assess the validity of each premise using factual sources. Finally, we incorporate the verification results into the LLM's prompt to maintain factual consistency in the final output. Experiments show that this approach effectively reduces hallucinations, improves factual accuracy, and does not require access to model logits or large-scale fine-tuning.
AIDE: Agentically Improve Visual Language Model with Domain Experts
Feb 13, 2025



The enhancement of Visual Language Models (VLMs) has traditionally relied on knowledge distillation from larger, more capable models. This dependence creates a fundamental bottleneck for improving state-of-the-art systems, particularly when no superior models exist. We introduce AIDE (Agentic Improvement through Domain Experts), a novel framework that enables VLMs to autonomously enhance their capabilities by leveraging specialized domain expert models. AIDE operates through a four-stage process: (1) identifying instances for refinement, (2) engaging domain experts for targeted analysis, (3) synthesizing expert outputs with existing data, and (4) integrating enhanced instances into the training pipeline. Experiments on multiple benchmarks, including MMMU, MME, MMBench, etc., demonstrate AIDE's ability to achieve notable performance gains without relying on larger VLMs nor human supervision. Our framework provides a scalable, resource-efficient approach to continuous VLM improvement, addressing critical limitations in current methodologies, particularly valuable when larger models are unavailable to access.
MegaCOIN: Enhancing Medium-Grained Color Perception for Vision-Language Models
Dec 05, 2024
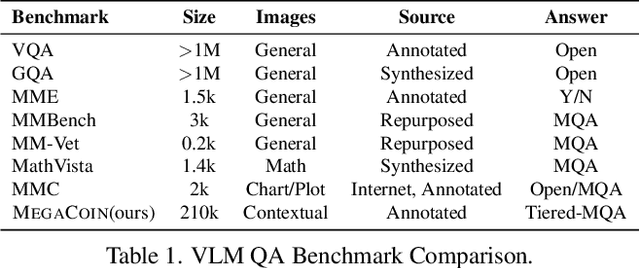
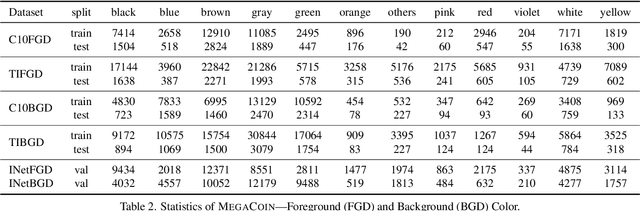

In vision-language models (VLMs), the ability to perceive and interpret color and physical environment is crucial for achieving contextually accurate understanding and interaction. However, despite advances in multimodal modeling, there remains a significant lack of specialized datasets that rigorously evaluate a model's capacity to discern subtle color variations and spatial context -- critical elements for situational comprehension and reliable deployment across real-world applications. Toward that goal, we curate MegaCOIN, a high-quality, human-labeled dataset based on \emph{real} images with various contextual attributes. MegaCOIN consists of two parts: MegaCOIN-Instruct, which serves as a supervised fine-tuning (SFT) dataset for VLMs; and MegaCOIN-Bench, an annotated test set that can be used as a stand-alone QA dataset. MegaCOIN~provides three annotated features for 220,000 real images: foreground color, background color, and description of an object's physical environment, constituting 660k human annotations. In addition, MegaCOIN can be applied to benchmark domain generalization (DG) algorithms. We explore benchmarking DG methods in the linear probing setup for VLM and show some new insights. Last but not least, we show that VLMs, including GPT-4o, have subpar color recognition capabilities, and fine-tuning with MegaCOIN can result in improved performance on visual evaluation tasks. In certain cases, MegaCOIN fine-tuned small-scale opensource models such as LLaVA and Bunny can outperform closed-source GPT-4o. We hope the utilities of MegaCOIN can shed light on the directions VLMs can improve and provide a more complex platform for domain generalization algorithms.
PatentEdits: Framing Patent Novelty as Textual Entailment
Nov 20, 2024



A patent must be deemed novel and non-obvious in order to be granted by the US Patent Office (USPTO). If it is not, a US patent examiner will cite the prior work, or prior art, that invalidates the novelty and issue a non-final rejection. Predicting what claims of the invention should change given the prior art is an essential and crucial step in securing invention rights, yet has not been studied before as a learnable task. In this work we introduce the PatentEdits dataset, which contains 105K examples of successful revisions that overcome objections to novelty. We design algorithms to label edits sentence by sentence, then establish how well these edits can be predicted with large language models (LLMs). We demonstrate that evaluating textual entailment between cited references and draft sentences is especially effective in predicting which inventive claims remained unchanged or are novel in relation to prior art.
DecoPrompt : Decoding Prompts Reduces Hallucinations when Large Language Models Meet False Premises
Nov 12, 2024While large language models (LLMs) have demonstrated increasing power, they have also called upon studies on their hallucinated outputs that deviate from factually correct statements. In this paper, we focus on one important scenario of false premises, where LLMs are distracted by misaligned claims although the model possesses the required factual knowledge to answer original questions accurately. Inspired by the observation that entropy of the false-premise prompt is closely related to its likelihood to elicit hallucination generation, we propose a new prompting algorithm, named DecoPrompt, to mitigate hallucination. DecoPrompt leverages LLMs to "decode" the false-premise prompts without really eliciting hallucination output from LLMs. We perform experiments on two datasets, demonstrating that DecoPrompt can reduce hallucinations effectively on outputs from different LLMs. Moreover, DecoPrompt exhibits cross-model transferability, which facilitates its applications to scenarios such as LLMs of large sizes or unavailable model logits.
LLM The Genius Paradox: A Linguistic and Math Expert's Struggle with Simple Word-based Counting Problems
Oct 18, 2024Interestingly, LLMs yet struggle with some basic tasks that humans find trivial to handle, e.g., counting the number of character r's in the word "strawberry". There are several popular conjectures (e.g., tokenization, architecture and training data) regarding the reason for deficiency of LLMs in simple word-based counting problems, sharing the similar belief that such failure stems from model pretraining hence probably inevitable during deployment. In this paper, we carefully design multiple evaluation settings to investigate validity of prevalent conjectures. Meanwhile, we measure transferability of advanced mathematical and coding reasoning capabilities from specialized LLMs to simple counting tasks. Although specialized LLMs suffer from counting problems as well, we find conjectures about inherent deficiency of LLMs invalid and further seek opportunities to elicit knowledge and capabilities from LLMs that are beneficial to counting tasks. Compared with strategies such as finetuning and in-context learning that are commonly adopted to enhance performance on new or challenging tasks, we show that engaging reasoning is the most robust and efficient way to help LLMs better perceive tasks with more accurate responses. We hope our conjecture validation design could provide insights into the study of future critical failure modes of LLMs. Based on challenges in transferring advanced capabilities to much simpler tasks, we call for more attention to model capability acquisition and evaluation. We also highlight the importance of cultivating consciousness of "reasoning before responding" during model pretraining.
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Aug 20, 2024



We introduce Transfusion, a recipe for training a multi-modal model over discrete and continuous data. Transfusion combines the language modeling loss function (next token prediction) with diffusion to train a single transformer over mixed-modality sequences. We pretrain multiple Transfusion models up to 7B parameters from scratch on a mixture of text and image data, establishing scaling laws with respect to a variety of uni- and cross-modal benchmarks. Our experiments show that Transfusion scales significantly better than quantizing images and training a language model over discrete image tokens. By introducing modality-specific encoding and decoding layers, we can further improve the performance of Transfusion models, and even compress each image to just 16 patches. We further demonstrate that scaling our Transfusion recipe to 7B parameters and 2T multi-modal tokens produces a model that can generate images and text on a par with similar scale diffusion models and language models, reaping the benefits of both worlds.
Towards Chapter-to-Chapter Context-Aware Literary Translation via Large Language Models
Jul 12, 2024



Discourse phenomena in existing document-level translation datasets are sparse, which has been a fundamental obstacle in the development of context-aware machine translation models. Moreover, most existing document-level corpora and context-aware machine translation methods rely on an unrealistic assumption on sentence-level alignments. To mitigate these issues, we first curate a novel dataset of Chinese-English literature, which consists of 160 books with intricate discourse structures. Then, we propose a more pragmatic and challenging setting for context-aware translation, termed chapter-to-chapter (Ch2Ch) translation, and investigate the performance of commonly-used machine translation models under this setting. Furthermore, we introduce a potential approach of finetuning large language models (LLMs) within the domain of Ch2Ch literary translation, yielding impressive improvements over baselines. Through our comprehensive analysis, we unveil that literary translation under the Ch2Ch setting is challenging in nature, with respect to both model learning methods and translation decoding algorithms.