 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIDE: Agentically Improve Visual Language Model with Domain Experts
Feb 13, 2025



The enhancement of Visual Language Models (VLMs) has traditionally relied on knowledge distillation from larger, more capable models. This dependence creates a fundamental bottleneck for improving state-of-the-art systems, particularly when no superior models exist. We introduce AIDE (Agentic Improvement through Domain Experts), a novel framework that enables VLMs to autonomously enhance their capabilities by leveraging specialized domain expert models. AIDE operates through a four-stage process: (1) identifying instances for refinement, (2) engaging domain experts for targeted analysis, (3) synthesizing expert outputs with existing data, and (4) integrating enhanced instances into the training pipeline. Experiments on multiple benchmarks, including MMMU, MME, MMBench, etc., demonstrate AIDE's ability to achieve notable performance gains without relying on larger VLMs nor human supervision. Our framework provides a scalable, resource-efficient approach to continuous VLM improvement, addressing critical limitations in current methodologies, particularly valuable when larger models are unavailable to access.
MegaCOIN: Enhancing Medium-Grained Color Perception for Vision-Language Models
Dec 05, 2024
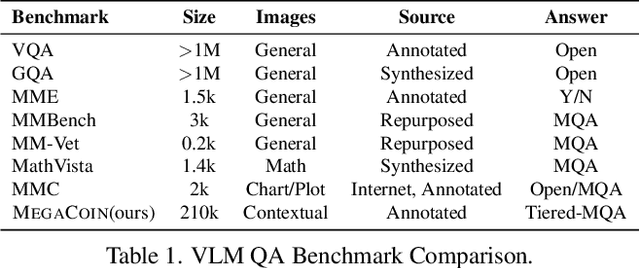
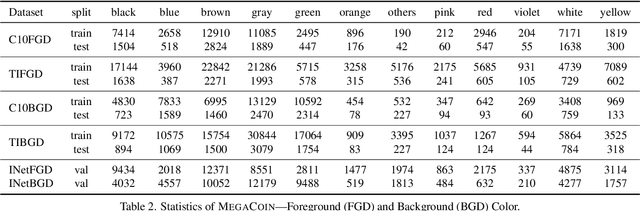

In vision-language models (VLMs), the ability to perceive and interpret color and physical environment is crucial for achieving contextually accurate understanding and interaction. However, despite advances in multimodal modeling, there remains a significant lack of specialized datasets that rigorously evaluate a model's capacity to discern subtle color variations and spatial context -- critical elements for situational comprehension and reliable deployment across real-world applications. Toward that goal, we curate MegaCOIN, a high-quality, human-labeled dataset based on \emph{real} images with various contextual attributes. MegaCOIN consists of two parts: MegaCOIN-Instruct, which serves as a supervised fine-tuning (SFT) dataset for VLMs; and MegaCOIN-Bench, an annotated test set that can be used as a stand-alone QA dataset. MegaCOIN~provides three annotated features for 220,000 real images: foreground color, background color, and description of an object's physical environment, constituting 660k human annotations. In addition, MegaCOIN can be applied to benchmark domain generalization (DG) algorithms. We explore benchmarking DG methods in the linear probing setup for VLM and show some new insights. Last but not least, we show that VLMs, including GPT-4o, have subpar color recognition capabilities, and fine-tuning with MegaCOIN can result in improved performance on visual evaluation tasks. In certain cases, MegaCOIN fine-tuned small-scale opensource models such as LLaVA and Bunny can outperform closed-source GPT-4o. We hope the utilities of MegaCOIN can shed light on the directions VLMs can improve and provide a more complex platform for domain generalization algorithms.
DDI-CoCo: A Dataset For Understanding The Effect Of Color Contrast In Machine-Assisted Skin Disease Detection
Jan 24, 2024



Skin tone as a demographic bias and inconsistent human labeling poses challenges in dermatology AI. We take another angle to investigate color contrast's impact, beyond skin tones, on malignancy detection in skin disease datasets: We hypothesize that in addition to skin tones, the color difference between the lesion area and skin also plays a role in malignancy detection performance of dermatology AI models. To study this, we first propose a robust labeling method to quantify color contrast scores of each image and validate our method by showing small labeling variations. More importantly, applying our method to \textit{the only} diverse-skin tone and pathologically-confirmed skin disease dataset DDI, yields \textbf{DDI-CoCo Dataset}, and we observe a performance gap between the high and low color difference groups. This disparity remains consistent across various state-of-the-art (SoTA) image classification models, which supports our hypothesis. Furthermore, we study the interaction between skin tone and color difference effects and suggest that color difference can be an additional reason behind model performance bias between skin tones. Our work provides a complementary angle to dermatology AI for improving skin disease detection.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023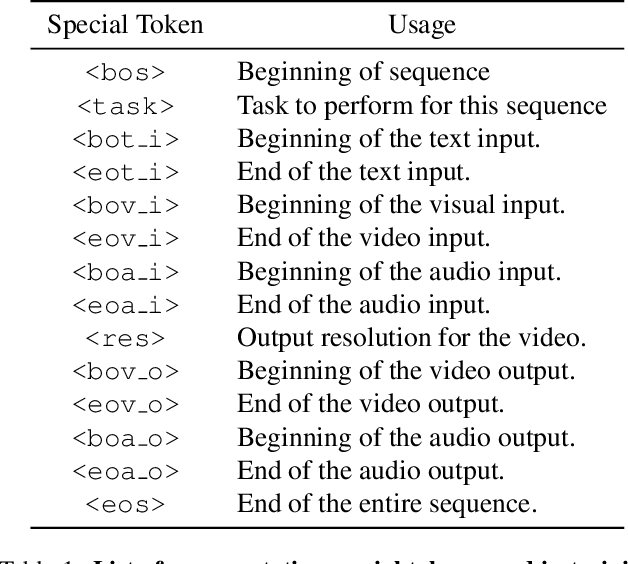



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
On Human Visual Contrast Sensitivity and Machine Vision Robustness: A Comparative Study
Dec 16, 2022



It is well established in neuroscience that color vision plays an essential part in the human visual perception system. Meanwhile, many novel designs for computer vision inspired by human vision have achieved success in a wide range of tasks and applications. Nonetheless, how color differences affect machine vision has not been well explored. Our work tries to bridge this gap between the human color vision aspect of visual recognition and that of the machine. To achieve this, we curate two datasets: CIFAR10-F and CIFAR100-F, which are based on the foreground colors of the popular CIFAR datasets. Together with CIFAR10-B and CIFAR100-B, the existing counterpart datasets with information on the background colors of CIFAR test sets, we assign each image based on its color contrast level per its foreground and background color labels and use this as a proxy to study how color contrast affects machine vision. We first conduct a proof-of-concept study, showing the effect of color difference and validate our datasets. Furthermore, on a broader level, an important characteristic of human vision is its robustness against ambient changes; therefore, drawing inspirations from ophthalmology and the robustness literature, we analogize contrast sensitivity from the human visual aspect to machine vision and complement the current robustness study using corrupted images with our CIFAR-CoCo datasets. In summary, motivated by neuroscience and equipped with the datasets we curate, we devise a new framework in two dimensions to perform extensive analyses on the effect of color contrast and corrupted images: (1) model architecture, (2) model size, to measure the perception ability of machine vision beyond total accuracy. We also explore how task complexity and data augmentation play a role in this setup. Our results call attention to new evaluation approaches for human-like machine perception.
Better May Not Be Fairer: Can Data Augmentation Mitigate Subgroup Degradation?
Dec 16, 2022It is no secret that deep learning models exhibit undesirable behaviors such as learning spurious correlations instead of learning correct relationships between input/output pairs. Prior works on robustness study datasets that mix low-level features to quantify how spurious correlations affect predictions instead of considering natural semantic factors due to limitations in accessing realistic datasets for comprehensive evaluation. To bridge this gap, in this paper we first investigate how natural background colors play a role as spurious features in image classification tasks by manually splitting the test sets of CIFAR10 and CIFAR100 into subgroups based on the background color of each image. We name our datasets CIFAR10-B and CIFAR100-B. We find that while standard CNNs achieve human-level accuracy, the subgroup performances are not consistent, and the phenomenon remains even after data augmentation (DA). To alleviate this issue, we propose FlowAug, a semantic DA method that leverages the decoupled semantic representations captured by a pre-trained generative flow. Experimental results show that FlowAug achieves more consistent results across subgroups than other types of DA methods on CIFAR10 and CIFAR100. Additionally, it shows better generalization performance. Furthermore, we propose a generic metric for studying model robustness to spurious correlations, where we take a macro average on the weighted standard deviations across different classes. Per our metric, FlowAug demonstrates less reliance on spurious correlations. Although this metric is proposed to study our curated datasets, it applies to all datasets that have subgroups or subclasses. Lastly, aside from less dependence on spurious correlations and better generalization on in-distribution test sets, we also show superior out-of-distribution results on CIFAR10.1 and competitive performances on CIFAR10-C and CIFAR100-C.
Learning Representations Robust to Group Shifts and Adversarial Examples
Feb 18, 2022
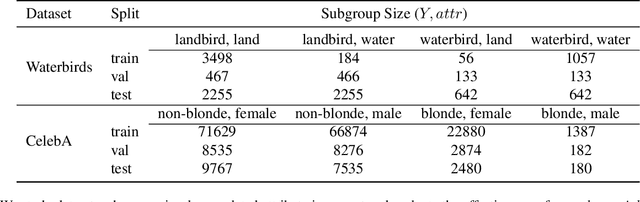
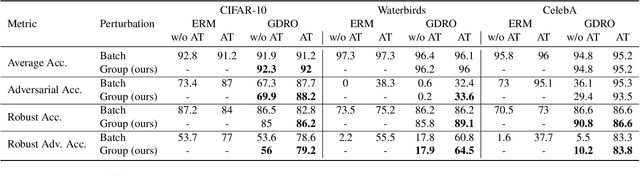
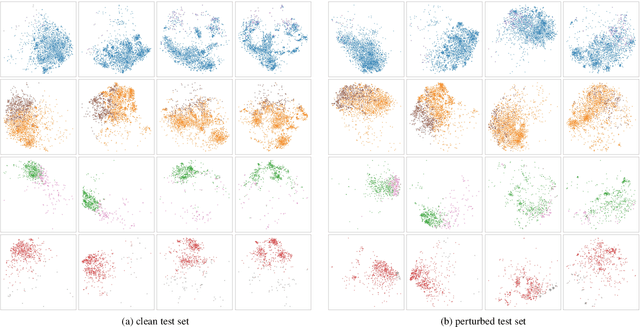
Despite the high performance achieved by deep neural networks on various tasks, extensive studies have demonstrated that small tweaks in the input could fail the model predictions. This issue of deep neural networks has led to a number of methods to improve model robustness, including adversarial training and distributionally robust optimization. Though both of these two methods are geared towards learning robust models, they have essentially different motivations: adversarial training attempts to train deep neural networks against perturbations, while distributional robust optimization aims at improving model performance on the most difficult "uncertain distributions". In this work, we propose an algorithm that combines adversarial training and group distribution robust optimization to improve robust representation learning. Experiments on three image benchmark datasets illustrate that the proposed method achieves superior results on robust metrics without sacrificing much of the standard measures.
Screenplay Quality Assessment: Can We Predict Who Gets Nominated?
May 13, 2020
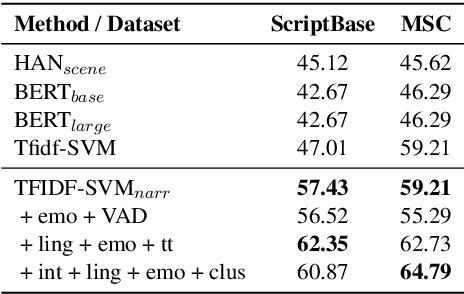
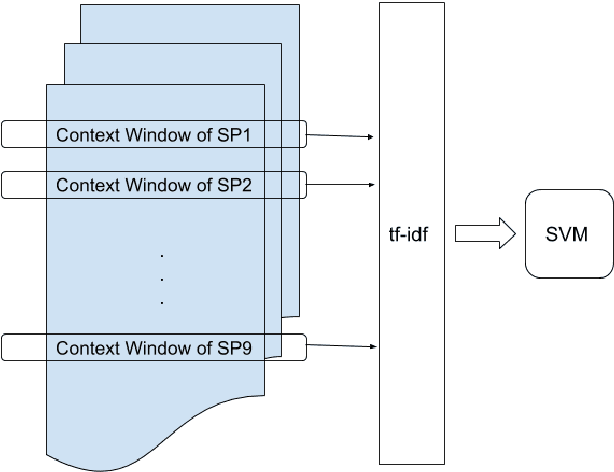
Deciding which scripts to turn into movies is a costly and time-consuming process for filmmakers. Thus, building a tool to aid script selection, an initial phase in movie production, can be very beneficial. Toward that goal, in this work, we present a method to evaluate the quality of a screenplay based on linguistic cues. We address this in a two-fold approach: (1) we define the task as predicting nominations of scripts at major film awards with the hypothesis that the peer-recognized scripts should have a greater chance to succeed. (2) based on industry opinions and narratology, we extract and integrate domain-specific features into common classification techniques. We face two challenges (1) scripts are much longer than other document datasets (2) nominated scripts are limited and thus difficult to collect. However, with narratology-inspired modeling and domain features, our approach offers clear improvements over strong baselines. Our work provides a new approach for future work in screenplay analysis.
A system for the 2019 Sentiment, Emotion and Cognitive State Task of DARPAs LORELEI project
May 01, 2019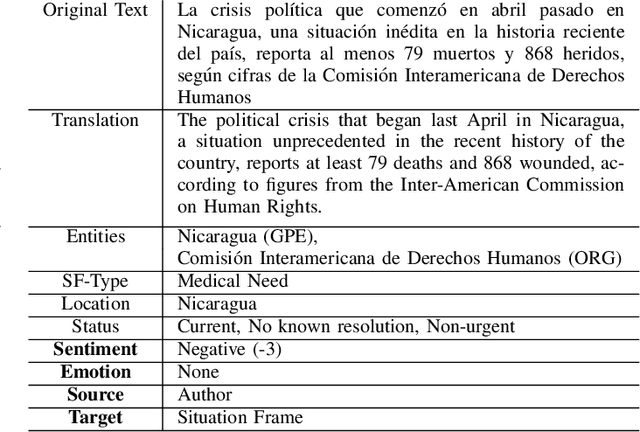

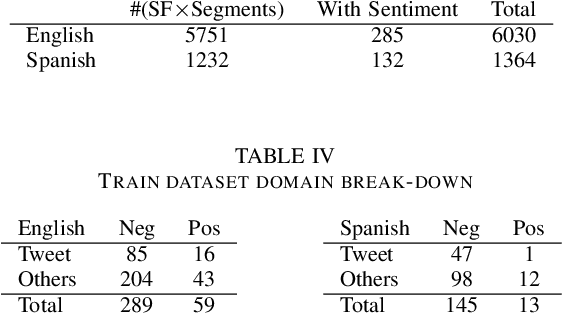
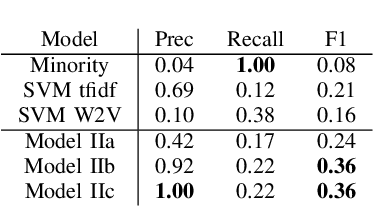
During the course of a Humanitarian Assistance-Disaster Relief (HADR) crisis, that can happen anywhere in the world, real-time information is often posted online by the people in need of help which, in turn, can be used by different stakeholders involved with management of the crisis. Automated processing of such posts can considerably improve the effectiveness of such efforts; for example, understanding the aggregated emotion from affected populations in specific areas may help inform decision-makers on how to best allocate resources for an effective disaster response. However, these efforts may be severely limited by the availability of resources for the local language. The ongoing DARPA project Low Resource Languages for Emergent Incidents (LORELEI) aims to further language processing technologies for low resource languages in the context of such a humanitarian crisis. In this work, we describe our submission for the 2019 Sentiment, Emotion and Cognitive state (SEC) pilot task of the LORELEI project. We describe a collection of sentiment analysis systems included in our submission along with the features extracted. Our fielded systems obtained the best results in both English and Spanish language evaluations of the SEC pilot task.