 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Aware Speech Recognition for Noisy Scenarios
Apr 09, 2025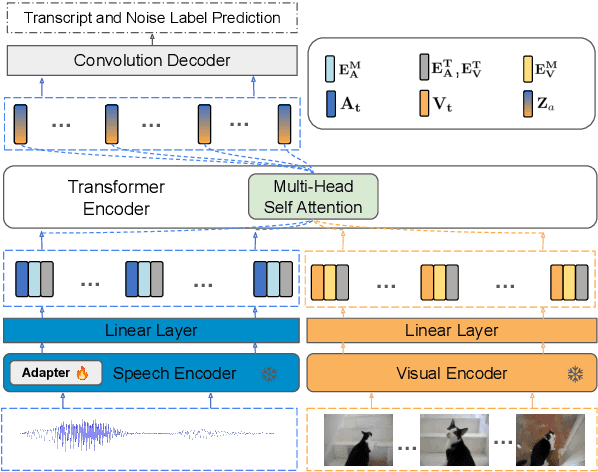


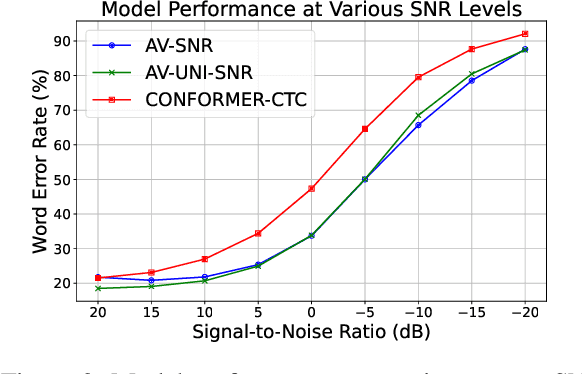
Humans have the ability to utilize visual cues, such as lip movements and visual scenes, to enhance auditory perception, particularly in noisy environments. However, current Automatic Speech Recognition (ASR) or Audio-Visual Speech Recognition (AVSR) models often struggle in noisy scenarios. To solve this task, we propose a model that improves transcription by correlating noise sources to visual cues. Unlike works that rely on lip motion and require the speaker's visibility, we exploit broader visual information from the environment. This allows our model to naturally filter speech from noise and improve transcription, much like humans do in noisy scenarios. Our method re-purposes pretrained speech and visual encoders, linking them with multi-headed attention. This approach enables the transcription of speech and the prediction of noise labels in video inputs. We introduce a scalable pipeline to develop audio-visual datasets, where visual cues correlate to noise in the audio. We show significant improvements over existing audio-only models in noisy scenarios. Results also highlight that visual cues play a vital role in improved transcription accuracy.
News Reporter: A Multi-lingual LLM Framework for Broadcast T.V News
Oct 10, 2024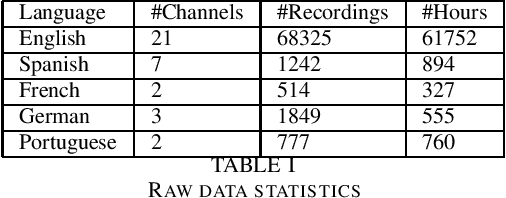
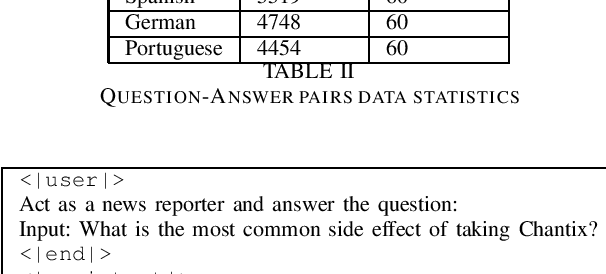


Large Language Models (LLMs) have fast become an essential tools to many conversational chatbots due to their ability to provide coherent answers for varied queries. Datasets used to train these LLMs are often a mix of generic and synthetic samples, thus lacking the verification needed to provide correct and verifiable answers for T.V. News. We collect and share a large collection of QA pairs extracted from transcripts of news recordings from various news-channels across the United States. Resultant QA pairs are then used to fine-tune an off-the-shelf LLM model. Our model surpasses base models of similar size on several open LLM benchmarks. We further integrate and propose a RAG method to improve contextualization of our answers and also point it to a verifiable news recording.
1SPU: 1-step Speech Processing Unit
Nov 10, 2023Recent studies have made some progress in refining end-to-end (E2E) speech recognition encoders by applying Connectionist Temporal Classification (CTC) loss to enhance named entity recognition within transcriptions. However, these methods have been constrained by their exclusive use of the ASCII character set, allowing only a limited array of semantic labels. We propose 1SPU, a 1-step Speech Processing Unit which can recognize speech events (e.g: speaker change) or an NL event (Intent, Emotion) while also transcribing vocal content. It extends the E2E automatic speech recognition (ASR) system's vocabulary by adding a set of unused placeholder symbols, conceptually akin to the <pad> tokens used in sequence modeling. These placeholders are then assigned to represent semantic events (in form of tags) and are integrated into the transcription process as distinct tokens. We demonstrate notable improvements on the SLUE benchmark and yields results that are on par with those for the SLURP dataset. Additionally, we provide a visual analysis of the system's proficiency in accurately pinpointing meaningful tokens over time, illustrating the enhancement in transcription quality through the utilization of supplementary semantic tags.
E2E Spoken Entity Extraction for Virtual Agents
Mar 01, 2023



This paper reimagines some aspects of speech processing using speech encoders, specifically about extracting entities directly from speech, with no intermediate textual representation. In human-computer conversations, extracting entities such as names, postal addresses and email addresses from speech is a challenging task. In this paper, we study the impact of fine-tuning pre-trained speech encoders on extracting spoken entities in human-readable form directly from speech without the need for text transcription. We illustrate that such a direct approach optimizes the encoder to transcribe only the entity relevant portions of speech, ignoring the superfluous portions such as carrier phrases and spellings of entities. In the context of dialogs from an enterprise virtual agent, we demonstrate that the 1-step approach outperforms the typical 2-step cascade of first generating lexical transcriptions followed by text-based entity extraction for identifying spoken entities.
Cross-stitched Multi-modal Encoders
Apr 20, 2022



In this paper, we propose a novel architecture for multi-modal speech and text input. We combine pretrained speech and text encoders using multi-headed cross-modal attention and jointly fine-tune on the target problem. The resultant architecture can be used for continuous token-level classification or utterance-level prediction acting on simultaneous text and speech. The resultant encoder efficiently captures both acoustic-prosodic and lexical information. We compare the benefits of multi-headed attention-based fusion for multi-modal utterance-level classification against a simple concatenation of pre-pooled, modality-specific representations. Our model architecture is compact, resource efficient, and can be trained on a single consumer GPU card.
Seq-2-Seq based Refinement of ASR Output for Spoken Name Capture
Mar 29, 2022
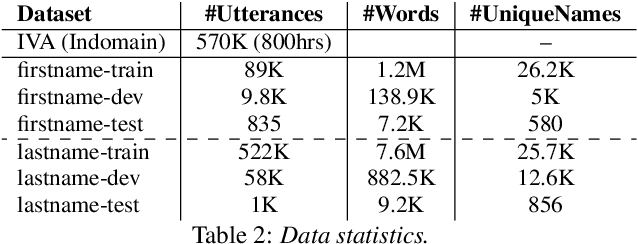

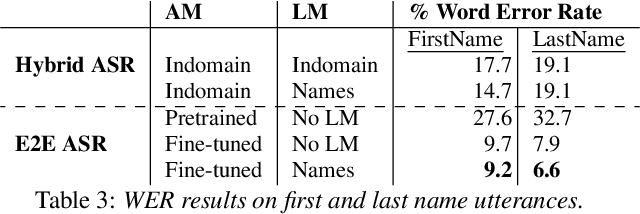
Person name capture from human speech is a difficult task in human-machine conversations. In this paper, we propose a novel approach to capture the person names from the caller utterances in response to the prompt "say and spell your first/last name". Inspired from work on spell correction, disfluency removal and text normalization, we propose a lightweight Seq-2-Seq system which generates a name spell from a varying user input. Our proposed method outperforms the strong baseline which is based on LM-driven rule-based approach.
An Automated Quality Evaluation Framework of Psychotherapy Conversations with Local Quality Estimates
Jun 15, 2021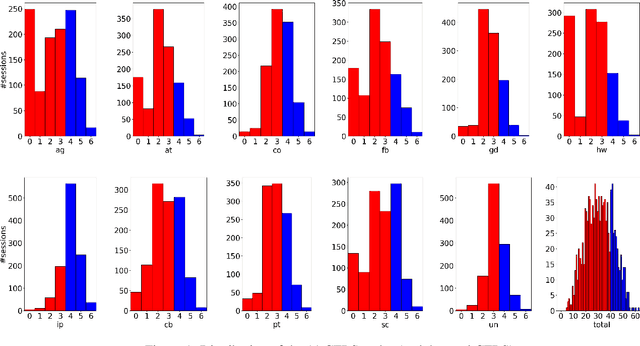



Computational approaches for assessing the quality of conversation-based psychotherapy, such as Cognitive Behavioral Therapy (CBT) and Motivational Interviewing (MI), have been developed recently to support quality assurance and clinical training. However, due to the long session lengths and limited modeling resources, computational methods largely rely on frequency-based lexical features or distribution of dialogue acts. In this work, we propose a hierarchical framework to automatically evaluate the quality of a CBT interaction. We divide each psychotherapy session into conversation segments and input those into a BERT-based model to produce segment embeddings. We first fine-tune BERT for predicting segment-level (local) quality scores and then use segment embeddings as lower-level input to a Bidirectional LSTM-based neural network to predict session-level (global) quality estimates. In particular, the segment-level quality scores are initialized with the session-level scores and we model the global quality as a function of the local quality scores to achieve the accurate segment-level quality estimates. These estimated segment-level scores benefit theBERT fine-tuning and in learning better segment embeddings. We evaluate the proposed framework on data drawn from real-world CBT clinical session recordings to predict multiple session-level behavior codes. The results indicate that our approach leads to improved evaluation accuracy for most codes in both regression and classification tasks.
"Am I A Good Therapist?" Automated Evaluation Of Psychotherapy Skills Using Speech And Language Technologies
Feb 22, 2021
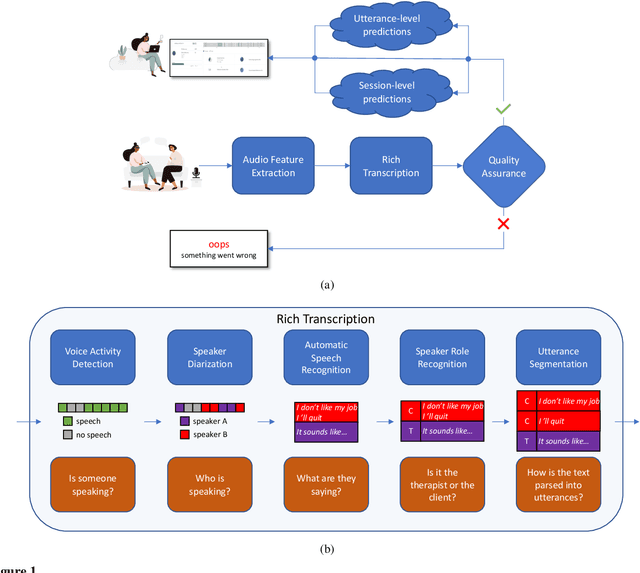
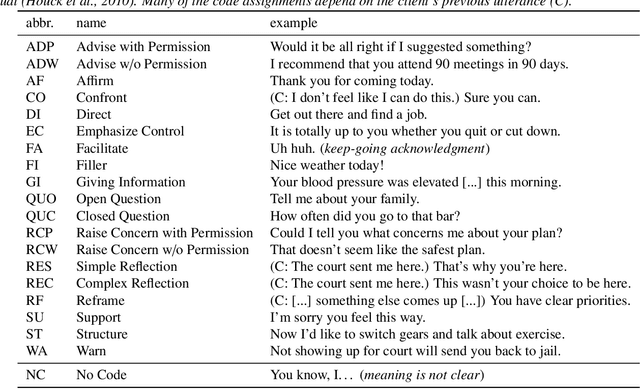
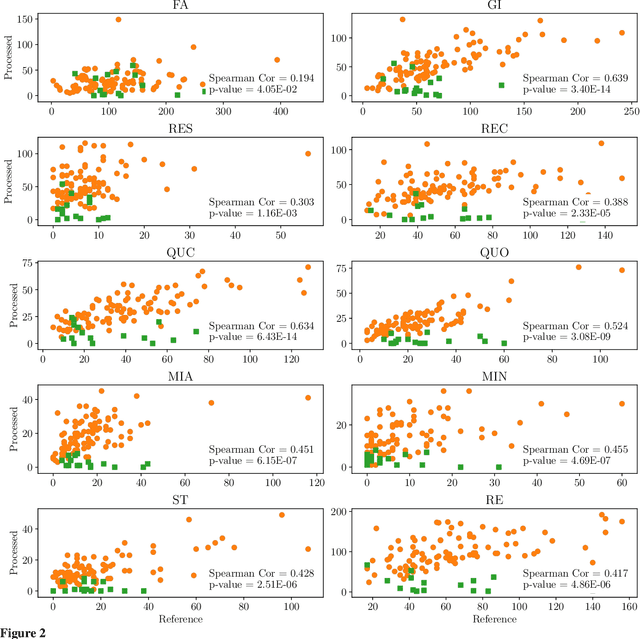
With the growing prevalence of psychological interventions, it is vital to have measures which rate the effectiveness of psychological care, in order to assist in training, supervision, and quality assurance of services. Traditionally, quality assessment is addressed by human raters who evaluate recorded sessions along specific dimensions, often codified through constructs relevant to the approach and domain. This is however a cost-prohibitive and time-consuming method which leads to poor feasibility and limited use in real-world settings. To facilitate this process, we have developed an automated competency rating tool able to process the raw recorded audio of a session, analyzing who spoke when, what they said, and how the health professional used language to provide therapy. Focusing on a use case of a specific type of psychotherapy called Motivational Interviewing, our system gives comprehensive feedback to the therapist, including information about the dynamics of the session (e.g., therapist's vs. client's talking time), low-level psychological language descriptors (e.g., type of questions asked), as well as other high-level behavioral constructs (e.g., the extent to which the therapist understands the clients' perspective). We describe our platform and its performance, using a dataset of more than 5,000 recordings drawn from its deployment in a real-world clinical setting used to assist training of new therapists. We are confident that a widespread use of automated psychotherapy rating tools in the near future will augment experts' capabilities by providing an avenue for more effective training and skill improvement and will eventually lead to more positive clinical outcomes.
Victim or Perpetrator? Analysis of Violent Characters Portrayals from Movie Scripts
Aug 29, 2020Violent content in the media can influence viewers' perception of the society. For example, frequent depictions of certain demographics as victims or perpetrators of violence can shape stereotyped attitudes. We propose that computational methods can aid in the large-scale analysis of violence in movies. The method we develop characterizes aspects of violent content solely from the language used in the scripts. Thus, our method is applicable to a movie in the earlier stages of content creation even before it is produced. This is complementary to previous works which rely on audio or video post production. In this work, we identify stereotypes in character roles (i.e., victim, perpetrator and narrator) based on the demographics of the actor casted for that role. Our results highlight two significant differences in the frequency of portrayals as well as the demographics of the interaction between victims and perpetrators : (1) female characters appear more often as victims, and (2) perpetrators are more likely to be White if the victim is Black or Latino. To date, we are the first to show that language used in movie scripts is a strong indicator of violent content, and that there are systematic portrayals of certain demographics as victims and perpetrators in a large dataset. This offers novel computational tools to assist in creating awareness of representations in storytelling
A system for the 2019 Sentiment, Emotion and Cognitive State Task of DARPAs LORELEI project
May 01, 2019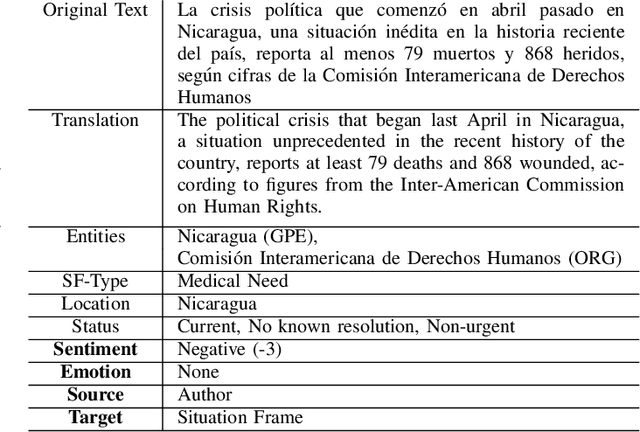

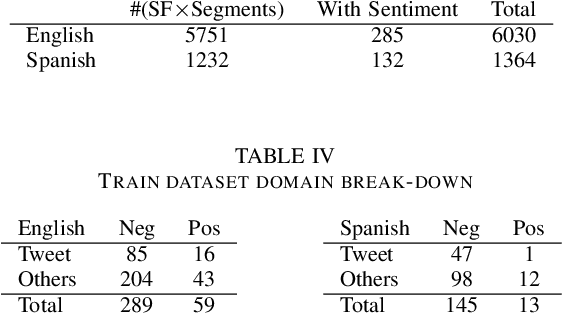
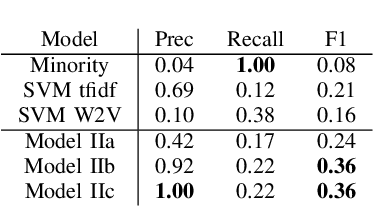
During the course of a Humanitarian Assistance-Disaster Relief (HADR) crisis, that can happen anywhere in the world, real-time information is often posted online by the people in need of help which, in turn, can be used by different stakeholders involved with management of the crisis. Automated processing of such posts can considerably improve the effectiveness of such efforts; for example, understanding the aggregated emotion from affected populations in specific areas may help inform decision-makers on how to best allocate resources for an effective disaster response. However, these efforts may be severely limited by the availability of resources for the local language. The ongoing DARPA project Low Resource Languages for Emergent Incidents (LORELEI) aims to further language processing technologies for low resource languages in the context of such a humanitarian crisis. In this work, we describe our submission for the 2019 Sentiment, Emotion and Cognitive state (SEC) pilot task of the LORELEI project. We describe a collection of sentiment analysis systems included in our submission along with the features extracted. Our fielded systems obtained the best results in both English and Spanish language evaluations of the SEC pilot task.