 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Open Data and Task Augmentation to Automated Behavioral Coding of Psychotherapy Conversations in Low-Resource Scenarios
Oct 25, 2022In psychotherapy interactions, the quality of a session is assessed by codifying the communicative behaviors of participants during the conversation through manual observation and annotation. Developing computational approaches for automated behavioral coding can reduce the burden on human coders and facilitate the objective evaluation of the intervention. In the real world, however, implementing such algorithms is associated with data sparsity challenges since privacy concerns lead to limited available in-domain data. In this paper, we leverage a publicly available conversation-based dataset and transfer knowledge to the low-resource behavioral coding task by performing an intermediate language model training via meta-learning. We introduce a task augmentation method to produce a large number of "analogy tasks" - tasks similar to the target one - and demonstrate that the proposed framework predicts target behaviors more accurately than all the other baseline models.
An Automated Quality Evaluation Framework of Psychotherapy Conversations with Local Quality Estimates
Jun 15, 2021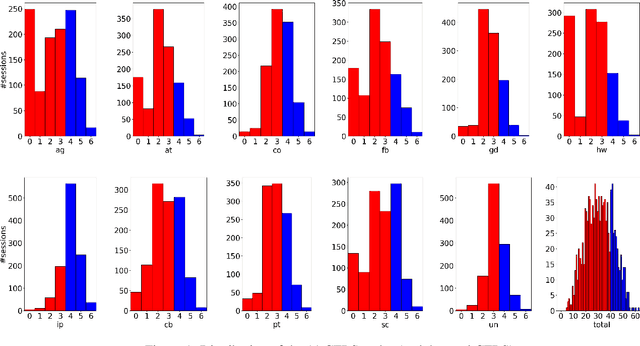



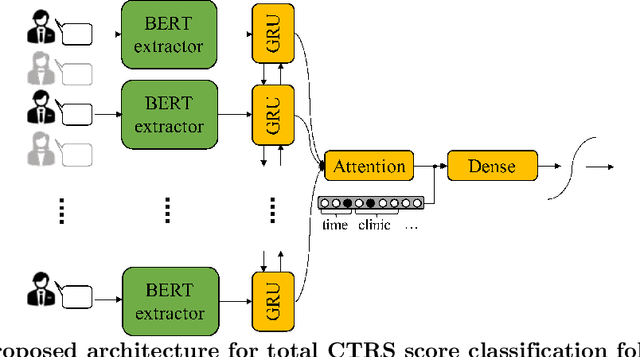
Computational approaches for assessing the quality of conversation-based psychotherapy, such as Cognitive Behavioral Therapy (CBT) and Motivational Interviewing (MI), have been developed recently to support quality assurance and clinical training. However, due to the long session lengths and limited modeling resources, computational methods largely rely on frequency-based lexical features or distribution of dialogue acts. In this work, we propose a hierarchical framework to automatically evaluate the quality of a CBT interaction. We divide each psychotherapy session into conversation segments and input those into a BERT-based model to produce segment embeddings. We first fine-tune BERT for predicting segment-level (local) quality scores and then use segment embeddings as lower-level input to a Bidirectional LSTM-based neural network to predict session-level (global) quality estimates. In particular, the segment-level quality scores are initialized with the session-level scores and we model the global quality as a function of the local quality scores to achieve the accurate segment-level quality estimates. These estimated segment-level scores benefit theBERT fine-tuning and in learning better segment embeddings. We evaluate the proposed framework on data drawn from real-world CBT clinical session recordings to predict multiple session-level behavior codes. The results indicate that our approach leads to improved evaluation accuracy for most codes in both regression and classification tasks.
Automated Quality Assessment of Cognitive Behavioral Therapy Sessions Through Highly Contextualized Language Representations
Feb 23, 2021


During a psychotherapy session, the counselor typically adopts techniques which are codified along specific dimensions (e.g., 'displays warmth and confidence', or 'attempts to set up collaboration') to facilitate the evaluation of the session. Those constructs, traditionally scored by trained human raters, reflect the complex nature of psychotherapy and highly depend on the context of the interaction. Recent advances in deep contextualized language models offer an avenue for accurate in-domain linguistic representations which can lead to robust recognition and scoring of such psychotherapy-relevant behavioral constructs, and support quality assurance and supervision. In this work, a BERT-based model is proposed for automatic behavioral scoring of a specific type of psychotherapy, called Cognitive Behavioral Therapy (CBT), where prior work is limited to frequency-based language features and/or short text excerpts which do not capture the unique elements involved in a spontaneous long conversational interaction. The model is trained in a multi-task manner in order to achieve higher interpretability. BERT-based representations are further augmented with available therapy metadata, providing relevant non-linguistic context and leading to consistent performance improvements.
"Am I A Good Therapist?" Automated Evaluation Of Psychotherapy Skills Using Speech And Language Technologies
Feb 22, 2021
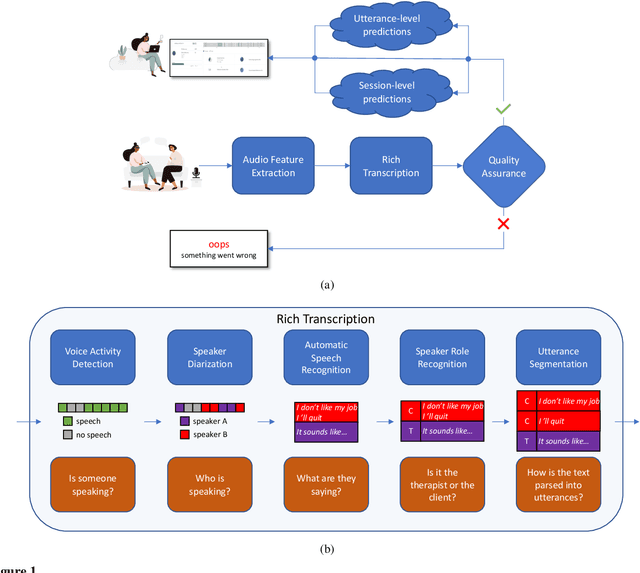
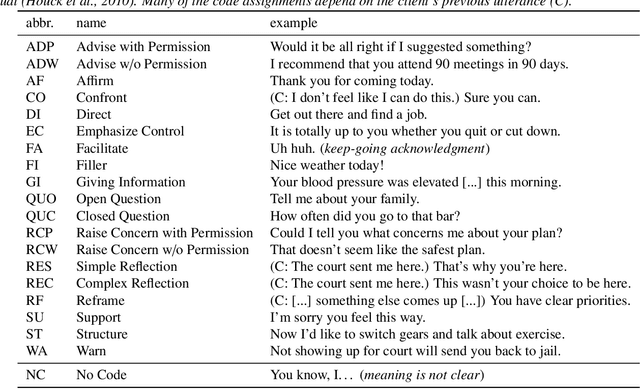
With the growing prevalence of psychological interventions, it is vital to have measures which rate the effectiveness of psychological care, in order to assist in training, supervision, and quality assurance of services. Traditionally, quality assessment is addressed by human raters who evaluate recorded sessions along specific dimensions, often codified through constructs relevant to the approach and domain. This is however a cost-prohibitive and time-consuming method which leads to poor feasibility and limited use in real-world settings. To facilitate this process, we have developed an automated competency rating tool able to process the raw recorded audio of a session, analyzing who spoke when, what they said, and how the health professional used language to provide therapy. Focusing on a use case of a specific type of psychotherapy called Motivational Interviewing, our system gives comprehensive feedback to the therapist, including information about the dynamics of the session (e.g., therapist's vs. client's talking time), low-level psychological language descriptors (e.g., type of questions asked), as well as other high-level behavioral constructs (e.g., the extent to which the therapist understands the clients' perspective). We describe our platform and its performance, using a dataset of more than 5,000 recordings drawn from its deployment in a real-world clinical setting used to assist training of new therapists. We are confident that a widespread use of automated psychotherapy rating tools in the near future will augment experts' capabilities by providing an avenue for more effective training and skill improvement and will eventually lead to more positive clinical outcomes.
Feature Fusion Strategies for End-to-End Evaluation of Cognitive Behavior Therapy Sessions
May 15, 2020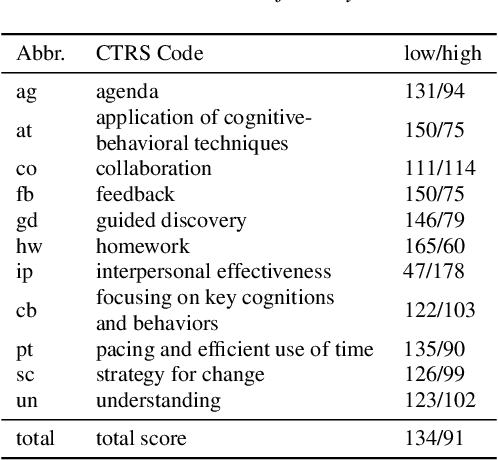
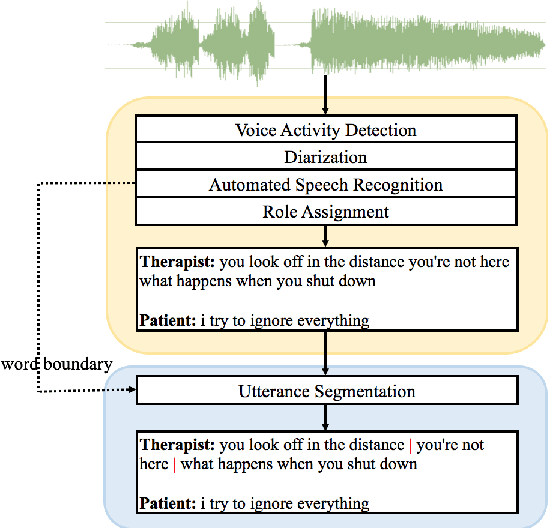
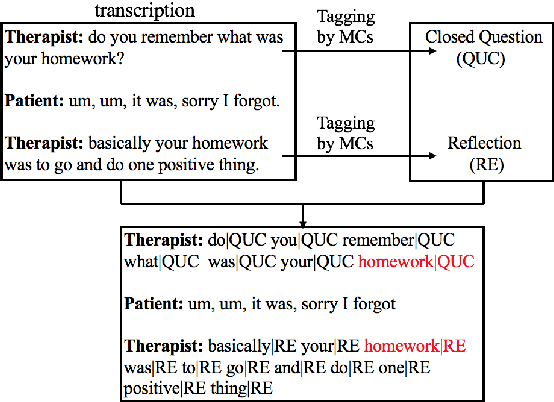

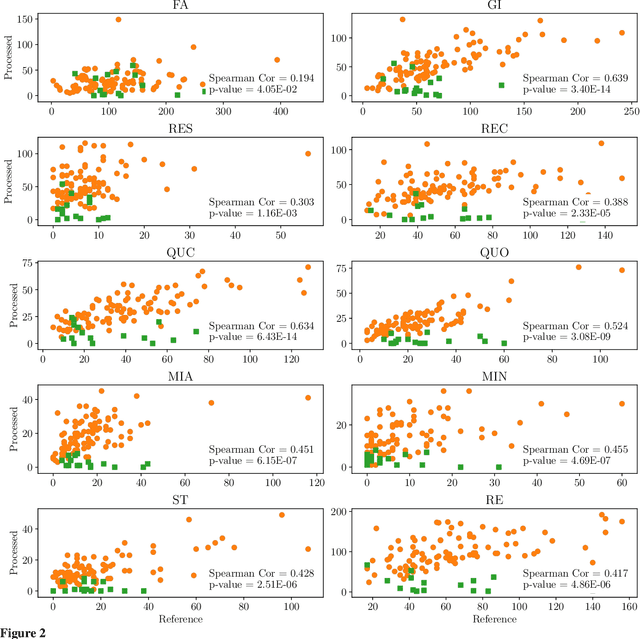
Cognitive Behavioral Therapy (CBT) is a goal-oriented psychotherapy for mental health concerns implemented in a conversational setting with broad empirical support for its effectiveness across a range of presenting problems and client populations. The quality of a CBT session is typically assessed by trained human raters who manually assign pre-defined session-level behavioral codes. In this paper, we develop an end-to-end pipeline that converts speech audio to diarized and transcribed text and extracts linguistic features to code the CBT sessions automatically. We investigate both word-level and utterance-level features and propose feature fusion strategies to combine them. The utterance level features include dialog act tags as well as behavioral codes drawn from another well-known talk psychotherapy called Motivational Interviewing (MI). We propose a novel method to augment the word-based features with the utterance level tags for subsequent CBT code estimation. Experiments show that our new fusion strategy outperforms all the studied features, both when used individually and when fused by direct concatenation. We also find that incorporating a sentence segmentation module can further improve the overall system given the preponderance of multi-utterance conversational turns in CBT sessions.
A Label Proportions Estimation Technique for Adversarial Domain Adaptation in Text Classification
Mar 26, 2020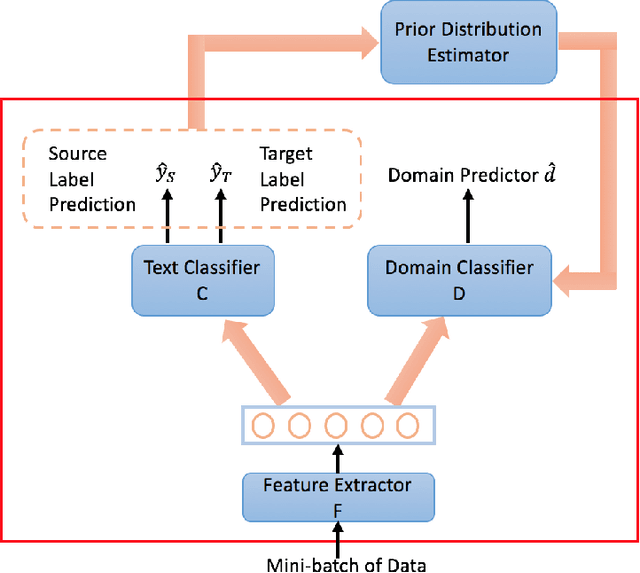

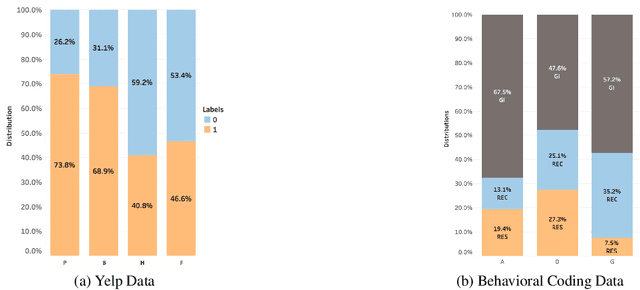
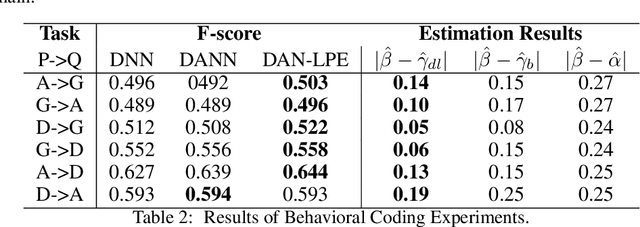
Many text classification tasks are domain-dependent, and various domain adaptation approaches have been proposed to predict unlabeled data in a new domain. Domain-adversarial neural networks (DANN) and their variants have been used widely recently and have achieved promising results for this problem. However, most of these approaches assume that the label proportions of the source and target domains are similar, which rarely holds in most real-world scenarios. Sometimes the label shift can be large and the DANN fails to learn domain-invariant features. In this study, we focus on unsupervised domain adaptation of text classification with label shift and introduce a domain adversarial network with label proportions estimation (DAN-LPE) framework. The DAN-LPE simultaneously trains a domain adversarial net and processes label proportions estimation by the confusion of the source domain and the predictions of the target domain. Experiments show the DAN-LPE achieves a good estimate of the target label distributions and reduces the label shift to improve the classification performance.