 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Approach to Device-Directed Speech Detection with Large Language Models
Mar 26, 2024Interactions with virtual assistants typically start with a predefined trigger phrase followed by the user command. To make interactions with the assistant more intuitive, we explore whether it is feasible to drop the requirement that users must begin each command with a trigger phrase. We explore this task in three ways: First, we train classifiers using only acoustic information obtained from the audio waveform. Second, we take the decoder outputs of an automatic speech recognition (ASR) system, such as 1-best hypotheses, as input features to a large language model (LLM). Finally, we explore a multimodal system that combines acoustic and lexical features, as well as ASR decoder signals in an LLM. Using multimodal information yields relative equal-error-rate improvements over text-only and audio-only models of up to 39% and 61%. Increasing the size of the LLM and training with low-rank adaption leads to further relative EER reductions of up to 18% on our dataset.
Multimodal Data and Resource Efficient Device-Directed Speech Detection with Large Foundation Models
Dec 06, 2023Interactions with virtual assistants typically start with a trigger phrase followed by a command. In this work, we explore the possibility of making these interactions more natural by eliminating the need for a trigger phrase. Our goal is to determine whether a user addressed the virtual assistant based on signals obtained from the streaming audio recorded by the device microphone. We address this task by combining 1-best hypotheses and decoder signals from an automatic speech recognition system with acoustic representations from an audio encoder as input features to a large language model (LLM). In particular, we are interested in data and resource efficient systems that require only a small amount of training data and can operate in scenarios with only a single frozen LLM available on a device. For this reason, our model is trained on 80k or less examples of multimodal data using a combination of low-rank adaptation and prefix tuning. We compare the proposed system to unimodal baselines and show that the multimodal approach achieves lower equal-error-rates (EERs), while using only a fraction of the training data. We also show that low-dimensional specialized audio representations lead to lower EERs than high-dimensional general audio representations.
CALM: Contrastive Aligned Audio-Language Multirate and Multimodal Representations
Feb 08, 2022Deriving multimodal representations of audio and lexical inputs is a central problem in Natural Language Understanding (NLU). In this paper, we present Contrastive Aligned Audio-Language Multirate and Multimodal Representations (CALM), an approach for learning multimodal representations using contrastive and multirate information inherent in audio and lexical inputs. The proposed model aligns acoustic and lexical information in the input embedding space of a pretrained language-only contextual embedding model. By aligning audio representations to pretrained language representations and utilizing contrastive information between acoustic inputs, CALM is able to bootstrap audio embedding competitive with existing audio representation models in only a few hours of training time. Operationally, audio spectrograms are processed using linearized patches through a Spectral Transformer (SpecTran) which is trained using a Contrastive Audio-Language Pretraining objective to align audio and language from similar queries. Subsequently, the derived acoustic and lexical tokens representations are input into a multimodal transformer to incorporate utterance level context and derive the proposed CALM representations. We show that these pretrained embeddings can subsequently be used in multimodal supervised tasks and demonstrate the benefits of the proposed pretraining steps in terms of the alignment of the two embedding spaces and the multirate nature of the pretraining. Our system shows 10-25\% improvement over existing emotion recognition systems including state-of-the-art three-modality systems under various evaluation objectives.
Analysis and Tuning of a Voice Assistant System for Dysfluent Speech
Jun 18, 2021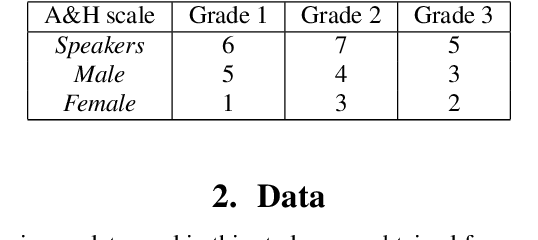
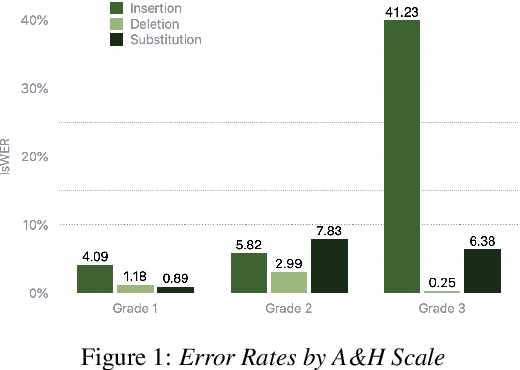
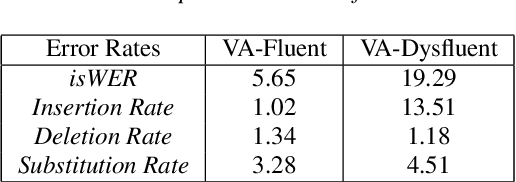
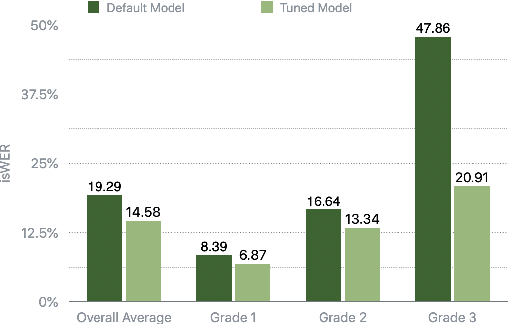
Dysfluencies and variations in speech pronunciation can severely degrade speech recognition performance, and for many individuals with moderate-to-severe speech disorders, voice operated systems do not work. Current speech recognition systems are trained primarily with data from fluent speakers and as a consequence do not generalize well to speech with dysfluencies such as sound or word repetitions, sound prolongations, or audible blocks. The focus of this work is on quantitative analysis of a consumer speech recognition system on individuals who stutter and production-oriented approaches for improving performance for common voice assistant tasks (i.e., "what is the weather?"). At baseline, this system introduces a significant number of insertion and substitution errors resulting in intended speech Word Error Rates (isWER) that are 13.64\% worse (absolute) for individuals with fluency disorders. We show that by simply tuning the decoding parameters in an existing hybrid speech recognition system one can improve isWER by 24\% (relative) for individuals with fluency disorders. Tuning these parameters translates to 3.6\% better domain recognition and 1.7\% better intent recognition relative to the default setup for the 18 study participants across all stuttering severities.
Unsupervised Speech Representation Learning for Behavior Modeling using Triplet Enhanced Contextualized Networks
Apr 01, 2021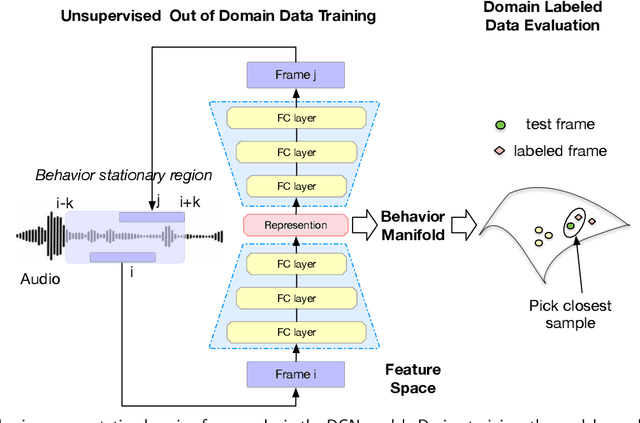

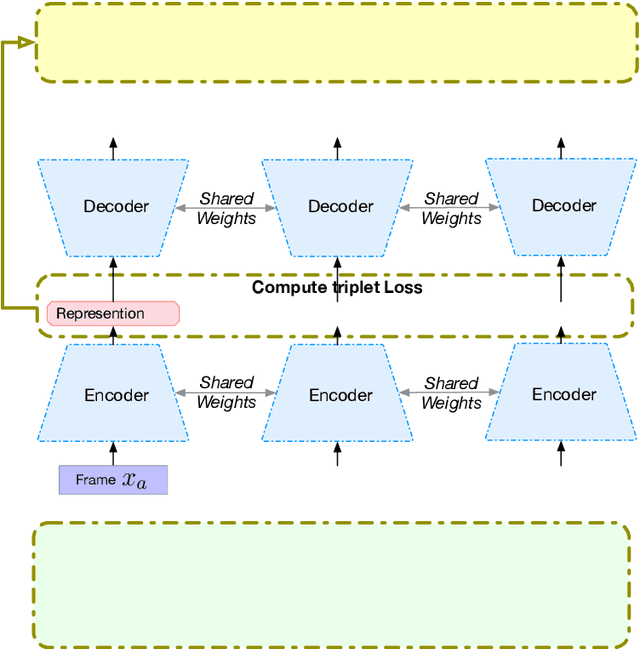
Speech encodes a wealth of information related to human behavior and has been used in a variety of automated behavior recognition tasks. However, extracting behavioral information from speech remains challenging including due to inadequate training data resources stemming from the often low occurrence frequencies of specific behavioral patterns. Moreover, supervised behavioral modeling typically relies on domain-specific construct definitions and corresponding manually-annotated data, rendering generalizing across domains challenging. In this paper, we exploit the stationary properties of human behavior within an interaction and present a representation learning method to capture behavioral information from speech in an unsupervised way. We hypothesize that nearby segments of speech share the same behavioral context and hence map onto similar underlying behavioral representations. We present an encoder-decoder based Deep Contextualized Network (DCN) as well as a Triplet-Enhanced DCN (TE-DCN) framework to capture the behavioral context and derive a manifold representation, where speech frames with similar behaviors are closer while frames of different behaviors maintain larger distances. The models are trained on movie audio data and validated on diverse domains including on a couples therapy corpus and other publicly collected data (e.g., stand-up comedy). With encouraging results, our proposed framework shows the feasibility of unsupervised learning within cross-domain behavioral modeling.
"Am I A Good Therapist?" Automated Evaluation Of Psychotherapy Skills Using Speech And Language Technologies
Feb 22, 2021
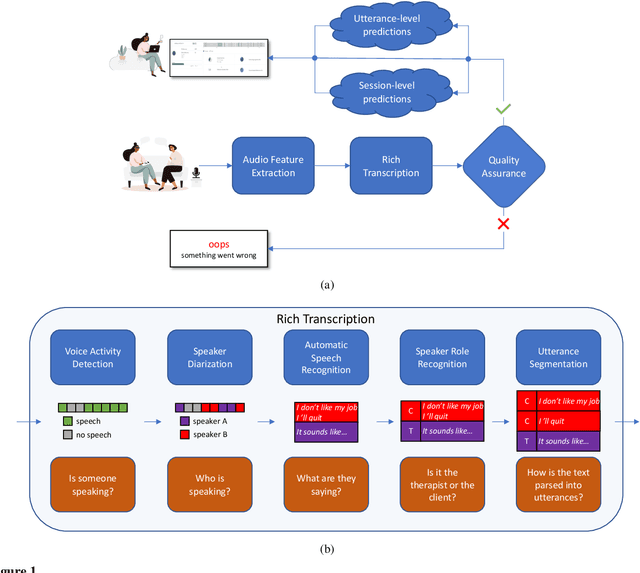
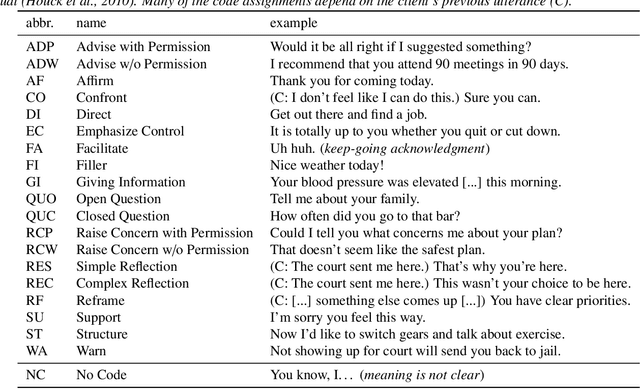
With the growing prevalence of psychological interventions, it is vital to have measures which rate the effectiveness of psychological care, in order to assist in training, supervision, and quality assurance of services. Traditionally, quality assessment is addressed by human raters who evaluate recorded sessions along specific dimensions, often codified through constructs relevant to the approach and domain. This is however a cost-prohibitive and time-consuming method which leads to poor feasibility and limited use in real-world settings. To facilitate this process, we have developed an automated competency rating tool able to process the raw recorded audio of a session, analyzing who spoke when, what they said, and how the health professional used language to provide therapy. Focusing on a use case of a specific type of psychotherapy called Motivational Interviewing, our system gives comprehensive feedback to the therapist, including information about the dynamics of the session (e.g., therapist's vs. client's talking time), low-level psychological language descriptors (e.g., type of questions asked), as well as other high-level behavioral constructs (e.g., the extent to which the therapist understands the clients' perspective). We describe our platform and its performance, using a dataset of more than 5,000 recordings drawn from its deployment in a real-world clinical setting used to assist training of new therapists. We are confident that a widespread use of automated psychotherapy rating tools in the near future will augment experts' capabilities by providing an avenue for more effective training and skill improvement and will eventually lead to more positive clinical outcomes.
Confusion2vec 2.0: Enriching Ambiguous Spoken Language Representations with Subwords
Feb 19, 2021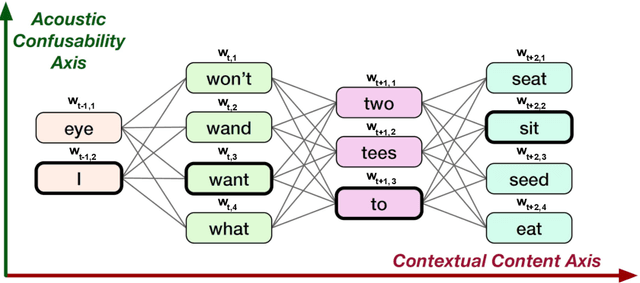
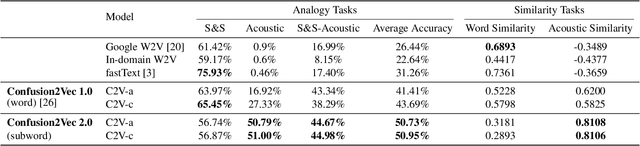
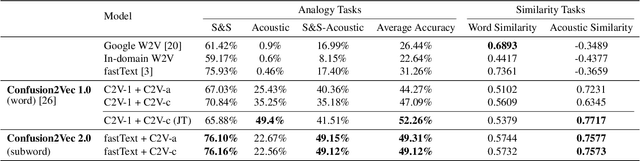
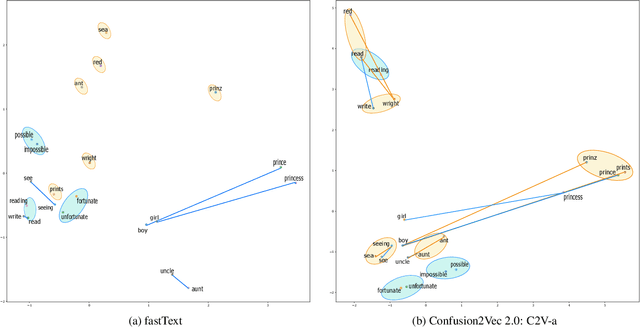
Word vector representations enable machines to encode human language for spoken language understanding and processing. Confusion2vec, motivated from human speech production and perception, is a word vector representation which encodes ambiguities present in human spoken language in addition to semantics and syntactic information. Confusion2vec provides a robust spoken language representation by considering inherent human language ambiguities. In this paper, we propose a novel word vector space estimation by unsupervised learning on lattices output by an automatic speech recognition (ASR) system. We encode each word in confusion2vec vector space by its constituent subword character n-grams. We show the subword encoding helps better represent the acoustic perceptual ambiguities in human spoken language via information modeled on lattice structured ASR output. The usefulness of the proposed Confusion2vec representation is evaluated using semantic, syntactic and acoustic analogy and word similarity tasks. We also show the benefits of subword modeling for acoustic ambiguity representation on the task of spoken language intent detection. The results significantly outperform existing word vector representations when evaluated on erroneous ASR outputs. We demonstrate that Confusion2vec subword modeling eliminates the need for retraining/adapting the natural language understanding models on ASR transcripts.
Speaker Diarization with Lexical Information
Apr 13, 2020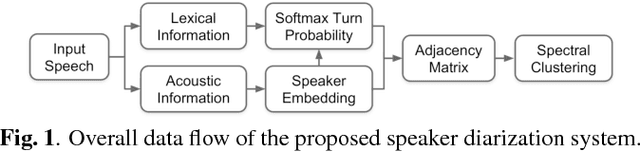
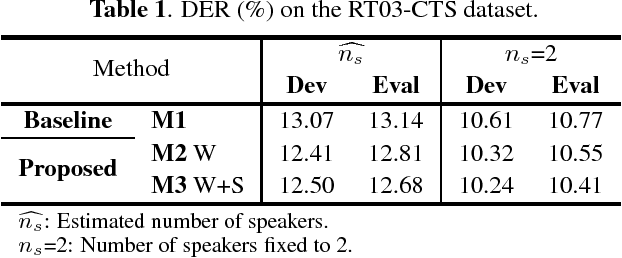
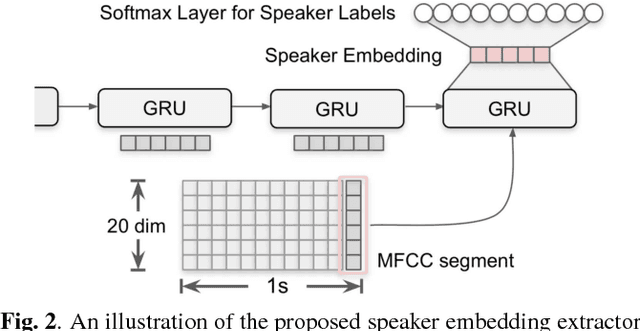
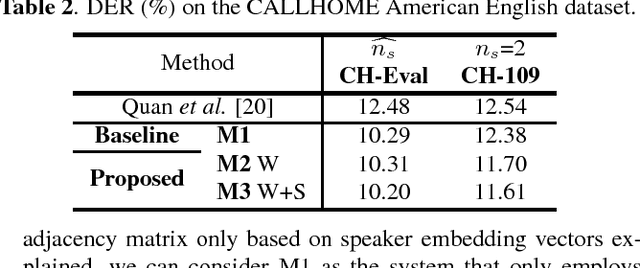
This work presents a novel approach for speaker diarization to leverage lexical information provided by automatic speech recognition. We propose a speaker diarization system that can incorporate word-level speaker turn probabilities with speaker embeddings into a speaker clustering process to improve the overall diarization accuracy. To integrate lexical and acoustic information in a comprehensive way during clustering, we introduce an adjacency matrix integration for spectral clustering. Since words and word boundary information for word-level speaker turn probability estimation are provided by a speech recognition system, our proposed method works without any human intervention for manual transcriptions. We show that the proposed method improves diarization performance on various evaluation datasets compared to the baseline diarization system using acoustic information only in speaker embeddings.
An analysis of observation length requirements for machine understanding of human behaviors in spoken language
Nov 29, 2019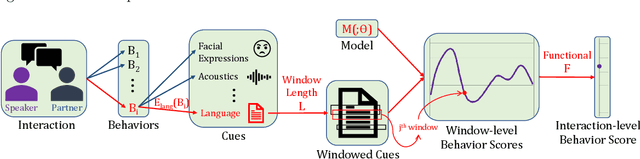


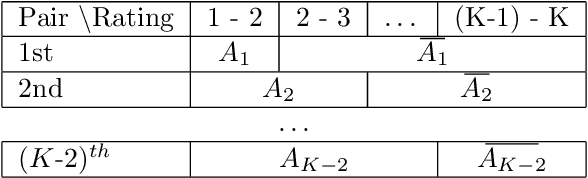
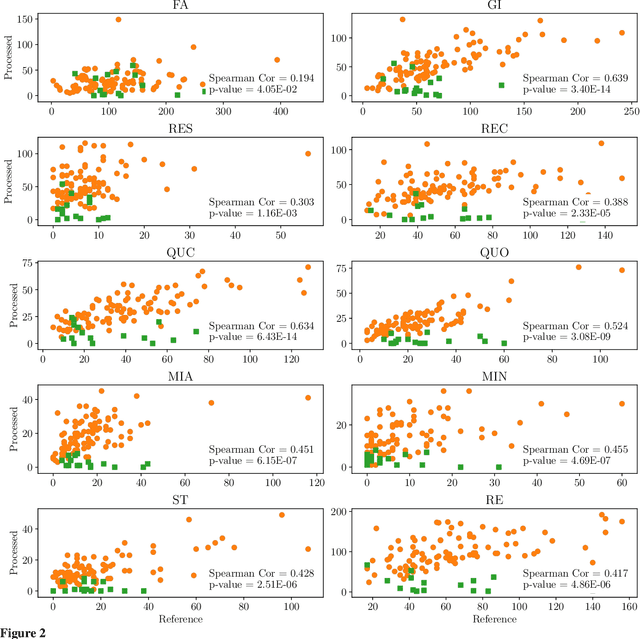
Machine learning-based human behavior modeling, often at the level of characterizing an entire clinical encounter such as a therapy session, has been shown to be useful across a range of domains in psychological research and practice from relationship and family studies to cancer care. Existing approaches typically first quantify the target behavior construct based on cues in an observation window, such as a fixed number of words, and then aggregate it over all the windows in that session. During this process, a sufficiently long window is employed so that adequate information is gathered to accurately estimate the construct. The link between behavior modeling and the observation length, however, has not been well studied, especially for spoken language. In this paper, we analyze the effect of observation window length on the quality of behavior quantification and present a framework for determining appropriate windows for a wide range of behaviors. Our analysis method employs two levels of evaluations: (a) extrinsic similarity between machine predictions and human expert annotations, and (b) intrinsic consistency between intra-machine and intra-human behavior relations. We apply our analysis on a dataset of real-life married couple interactions that are annotated for a large and diverse set of behavior codes and test the robustness of our findings to different machine learning models. We find that negative constructs such as blame can be accurately identified from short expressions while those pertaining to positive affect such as satisfaction tend to require slightly longer observation windows. Behaviors that describe more complex personality traits such as negotiation and avoidance are found to require very long observations and are difficult to quantify from language alone. Our findings are in agreement with similar work on acoustic cues, thin slices and human emotion perception.
Speaker-invariant Affective Representation Learning via Adversarial Training
Nov 04, 2019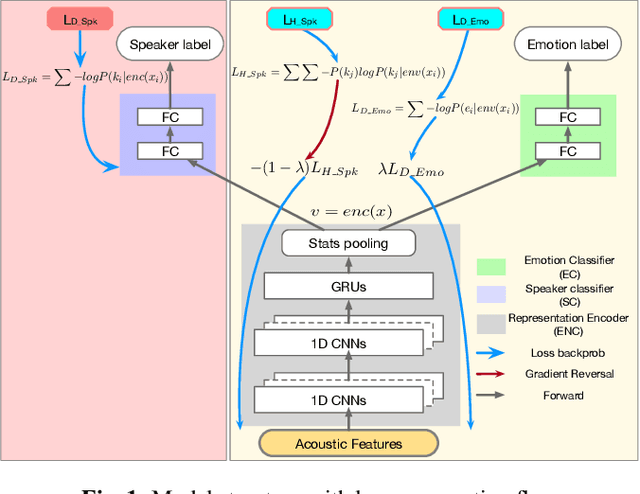
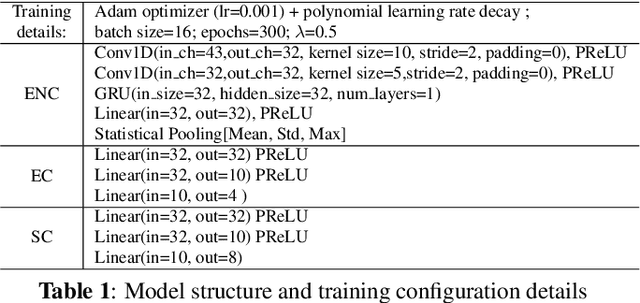
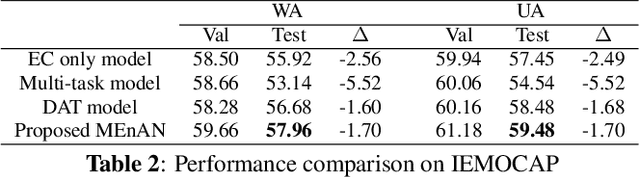
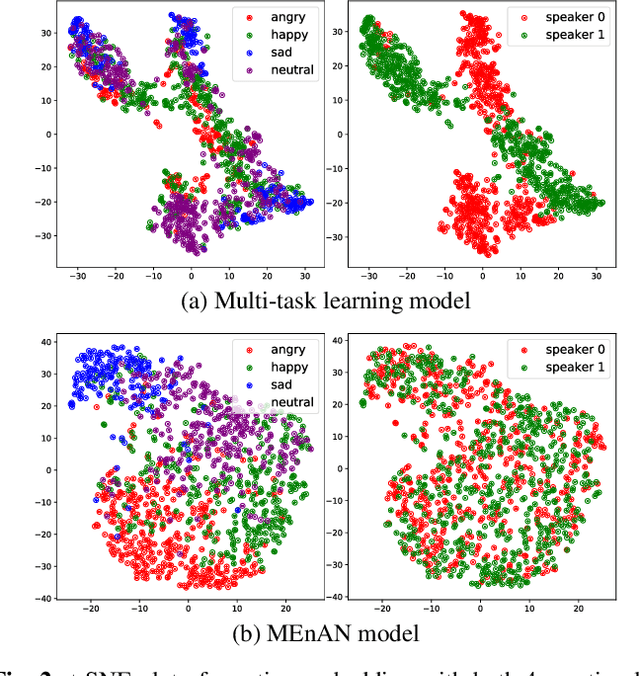
Representation learning for speech emotion recognition is challenging due to labeled data sparsity issue and lack of gold standard references. In addition, there is much variability from input speech signals, human subjective perception of the signals and emotion label ambiguity. In this paper, we propose a machine learning framework to obtain speech emotion representations by limiting the effect of speaker variability in the speech signals. Specifically, we propose to disentangle the speaker characteristics from emotion through an adversarial training network in order to better represent emotion. Our method combines the gradient reversal technique with an entropy loss function to remove such speaker information. Our approach is evaluated on both IEMOCAP and CMU-MOSEI datasets. We show that our method improves speech emotion classification and increases generalization to unseen speakers.