 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Enforced Transfer: A Novel Domain Adaptation Algorithm
Jan 24, 2022
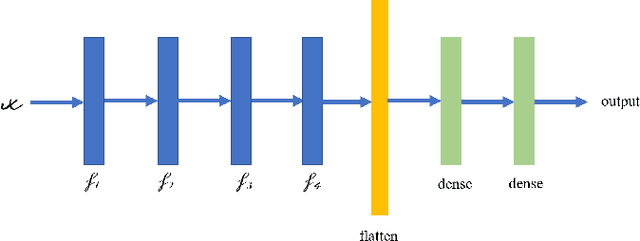
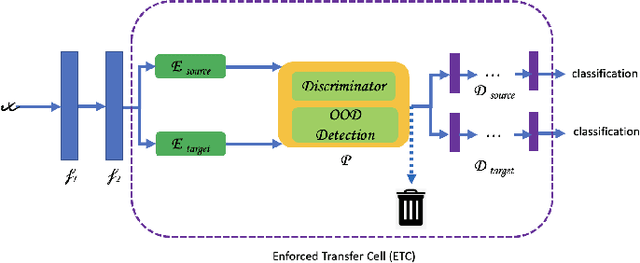
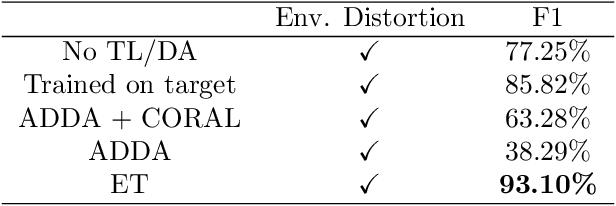
Existing Domain Adaptation (DA) algorithms train target models and then use the target models to classify all samples in the target dataset. While this approach attempts to address the problem that the source and the target data are from different distributions, it fails to recognize the possibility that, within the target domain, some samples are closer to the distribution of the source domain than the distribution of the target domain. In this paper, we develop a novel DA algorithm, the Enforced Transfer, that deals with this situation. A straightforward but effective idea to deal with this dilemma is to use an out-of-distribution detection algorithm to decide if, during the testing phase, a given sample is closer to the distribution of the source domain, the target domain, or neither. In the first case, this sample is given to a machine learning classifier trained on source samples. In the second case, this sample is given to a machine learning classifier trained on target samples. In the third case, this sample is discarded as neither an ML model trained on source nor an ML model trained on target is suitable to classify it. It is widely known that the first few layers in a neural network extract low-level features, so the aforementioned approach can be extended from classifying samples in three different scenarios to classifying the samples' activations after an empirically determined layer in three different scenarios. The Enforced Transfer implements the idea. On three types of DA tasks, we outperform the state-of-the-art algorithms that we compare against.
Unsupervised Speech Representation Learning for Behavior Modeling using Triplet Enhanced Contextualized Networks
Apr 01, 2021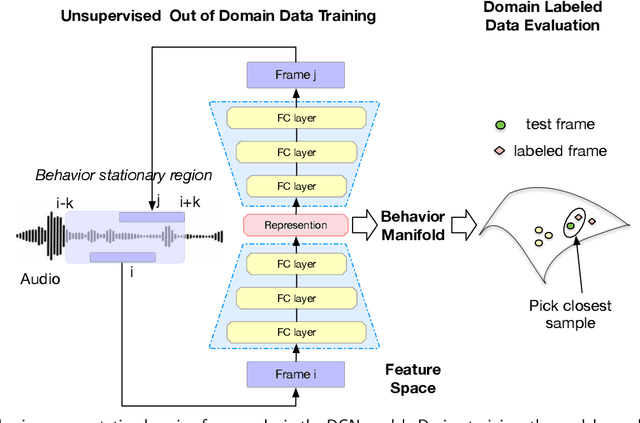

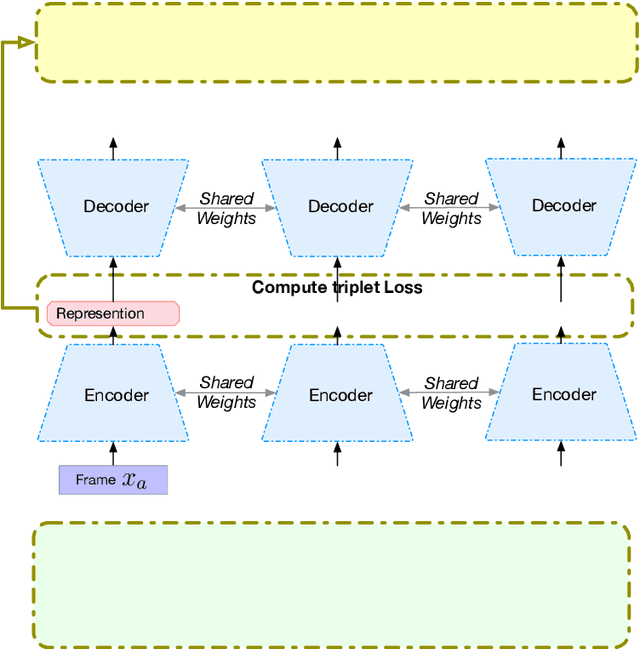
Speech encodes a wealth of information related to human behavior and has been used in a variety of automated behavior recognition tasks. However, extracting behavioral information from speech remains challenging including due to inadequate training data resources stemming from the often low occurrence frequencies of specific behavioral patterns. Moreover, supervised behavioral modeling typically relies on domain-specific construct definitions and corresponding manually-annotated data, rendering generalizing across domains challenging. In this paper, we exploit the stationary properties of human behavior within an interaction and present a representation learning method to capture behavioral information from speech in an unsupervised way. We hypothesize that nearby segments of speech share the same behavioral context and hence map onto similar underlying behavioral representations. We present an encoder-decoder based Deep Contextualized Network (DCN) as well as a Triplet-Enhanced DCN (TE-DCN) framework to capture the behavioral context and derive a manifold representation, where speech frames with similar behaviors are closer while frames of different behaviors maintain larger distances. The models are trained on movie audio data and validated on diverse domains including on a couples therapy corpus and other publicly collected data (e.g., stand-up comedy). With encouraging results, our proposed framework shows the feasibility of unsupervised learning within cross-domain behavioral modeling.
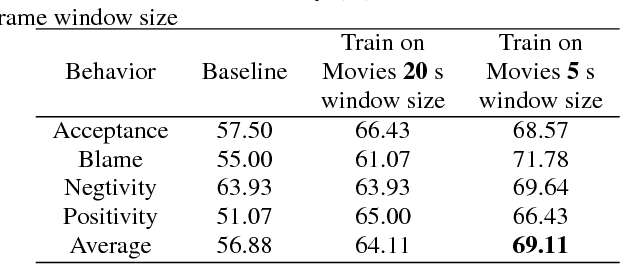
An analysis of observation length requirements for machine understanding of human behaviors in spoken language
Nov 29, 2019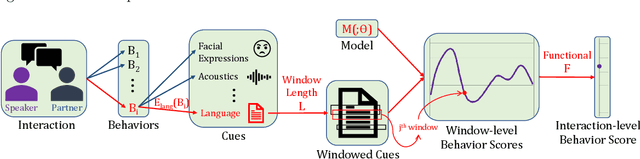


Machine learning-based human behavior modeling, often at the level of characterizing an entire clinical encounter such as a therapy session, has been shown to be useful across a range of domains in psychological research and practice from relationship and family studies to cancer care. Existing approaches typically first quantify the target behavior construct based on cues in an observation window, such as a fixed number of words, and then aggregate it over all the windows in that session. During this process, a sufficiently long window is employed so that adequate information is gathered to accurately estimate the construct. The link between behavior modeling and the observation length, however, has not been well studied, especially for spoken language. In this paper, we analyze the effect of observation window length on the quality of behavior quantification and present a framework for determining appropriate windows for a wide range of behaviors. Our analysis method employs two levels of evaluations: (a) extrinsic similarity between machine predictions and human expert annotations, and (b) intrinsic consistency between intra-machine and intra-human behavior relations. We apply our analysis on a dataset of real-life married couple interactions that are annotated for a large and diverse set of behavior codes and test the robustness of our findings to different machine learning models. We find that negative constructs such as blame can be accurately identified from short expressions while those pertaining to positive affect such as satisfaction tend to require slightly longer observation windows. Behaviors that describe more complex personality traits such as negotiation and avoidance are found to require very long observations and are difficult to quantify from language alone. Our findings are in agreement with similar work on acoustic cues, thin slices and human emotion perception.
Linking emotions to behaviors through deep transfer learning
Oct 08, 2019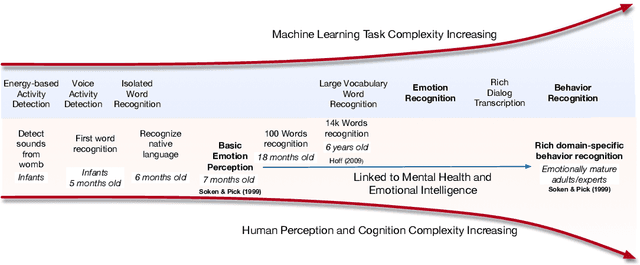

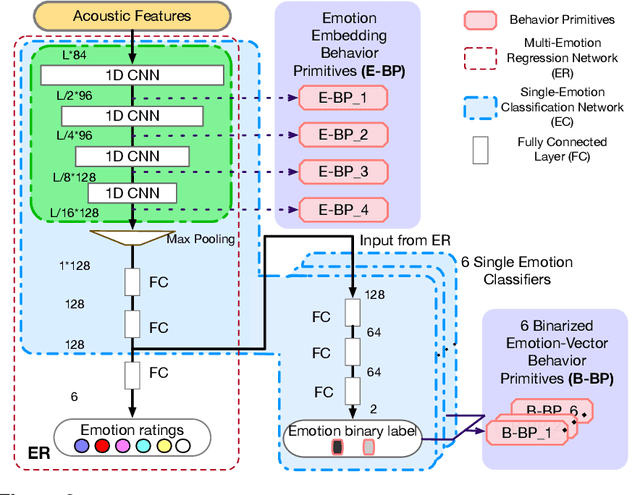
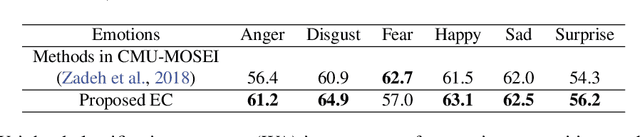
Human behavior refers to the way humans act and interact. Understanding human behavior is a cornerstone of observational practice, especially in psychotherapy. An important cue of behavior analysis is the dynamical changes of emotions during the conversation. Domain experts integrate emotional information in a highly nonlinear manner, thus, it is challenging to explicitly quantify the relationship between emotions and behaviors. In this work, we employ deep transfer learning to analyze their inferential capacity and contextual importance. We first train a network to quantify emotions from acoustic signals and then use information from the emotion recognition network as features for behavior recognition. We treat this emotion-related information as behavioral primitives and further train higher level layers towards behavior quantification. Through our analysis, we find that emotion-related information is an important cue for behavior recognition. Further, we investigate the importance of emotional-context in the expression of behavior by constraining (or not) the neural networks' contextual view of the data. This demonstrates that the sequence of emotions is critical in behavior expression. To achieve these frameworks we employ hybrid architectures of convolutional networks and recurrent networks to extract emotion-related behavior primitives and facilitate automatic behavior recognition from speech.
Modeling Interpersonal Linguistic Coordination in Conversations using Word Mover's Distance
Apr 12, 2019
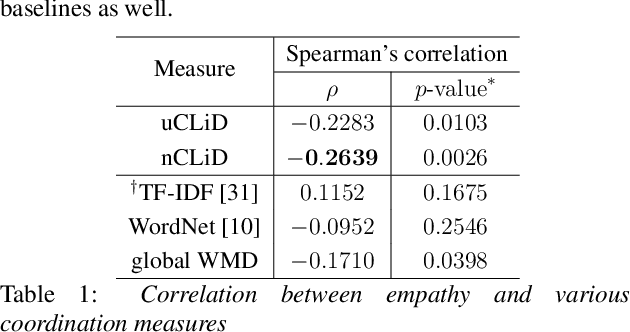
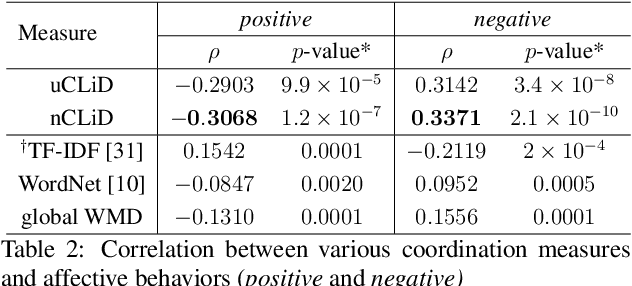
Linguistic coordination is a well-established phenomenon in spoken conversations and often associated with positive social behaviors and outcomes. While there have been many attempts to measure lexical coordination or entrainment in literature, only a few have explored coordination in syntactic or semantic space. In this work, we attempt to combine these different aspects of coordination into a single measure by leveraging distances in a neural word representation space. In particular, we adopt the recently proposed Word Mover's Distance with word2vec embeddings and extend it to measure the dissimilarity in language used in multiple consecutive speaker turns. To validate our approach, we apply this measure for two case studies in the clinical psychology domain. We find that our proposed measure is correlated with the therapist's empathy towards their patient in Motivational Interviewing and with affective behaviors in Couples Therapy. In both case studies, our proposed metric exhibits higher correlation than previously proposed measures. When applied to the couples with relationship improvement, we also notice a significant decrease in the proposed measure over the course of therapy, indicating higher linguistic coordination.
Unsupervised Online Multitask Learning of Behavioral Sentence Embeddings
Nov 01, 2018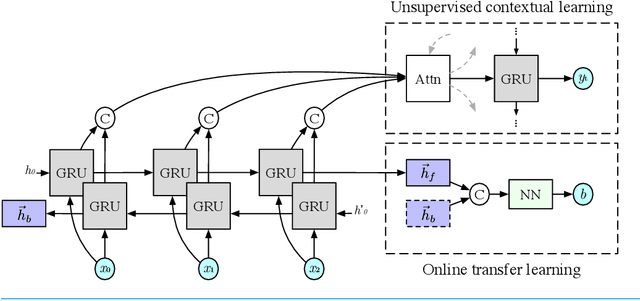

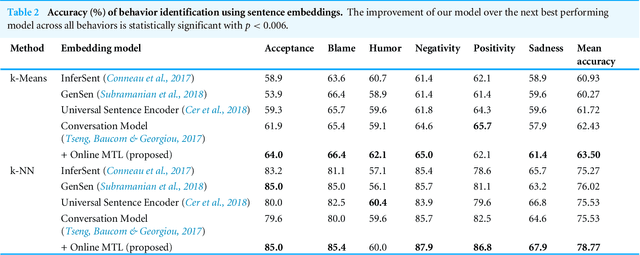
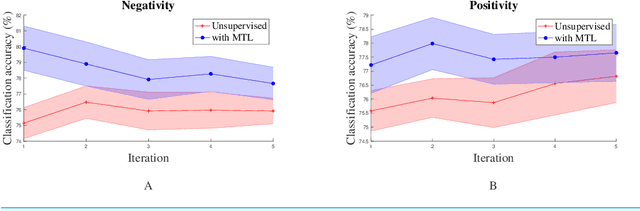
Unsupervised learning has been an attractive method for easily deriving meaningful data representations from vast amounts of unlabeled data. These representations, or embeddings, often yield superior results in many tasks, whether used directly or as features in subsequent training stages. However, the quality of the embeddings is highly dependent on the assumed knowledge in the unlabeled data and how the system extracts information without supervision. Domain portability is also very limited in unsupervised learning, often requiring re-training on other in-domain corpora to achieve robustness. In this work we present a multitask paradigm for unsupervised contextual learning of behavioral interactions which addresses unsupervised domain adaption. We introduce an online multitask objective into unsupervised learning and show that sentence embeddings generated through this process increases performance of affective tasks.
Modeling Interpersonal Influence of Verbal Behavior in Couples Therapy Dyadic Interactions
May 23, 2018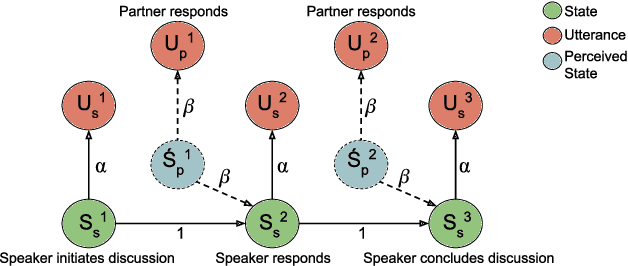

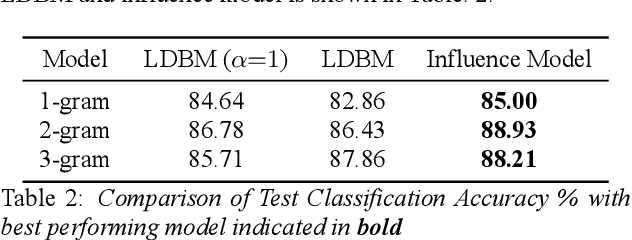
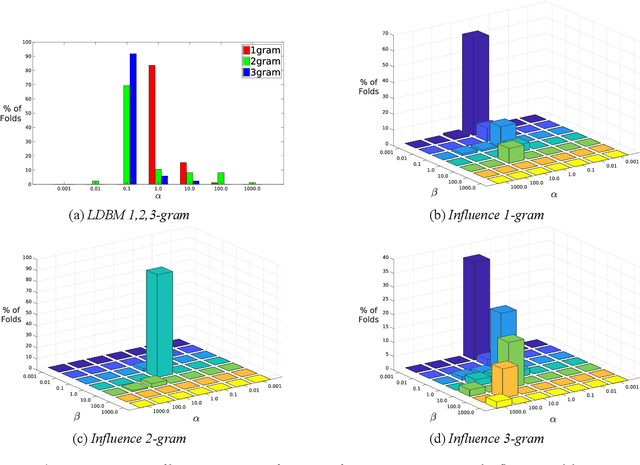
Dyadic interactions among humans are marked by speakers continuously influencing and reacting to each other in terms of responses and behaviors, among others. Understanding how interpersonal dynamics affect behavior is important for successful treatment in psychotherapy domains. Traditional schemes that automatically identify behavior for this purpose have often looked at only the target speaker. In this work, we propose a Markov model of how a target speaker's behavior is influenced by their own past behavior as well as their perception of their partner's behavior, based on lexical features. Apart from incorporating additional potentially useful information, our model can also control the degree to which the partner affects the target speaker. We evaluate our proposed model on the task of classifying Negative behavior in Couples Therapy and show that it is more accurate than the single-speaker model. Furthermore, we investigate the degree to which the optimal influence relates to how well a couple does on the long-term, via relating to relationship outcomes
Towards an Unsupervised Entrainment Distance in Conversational Speech using Deep Neural Networks
Apr 23, 2018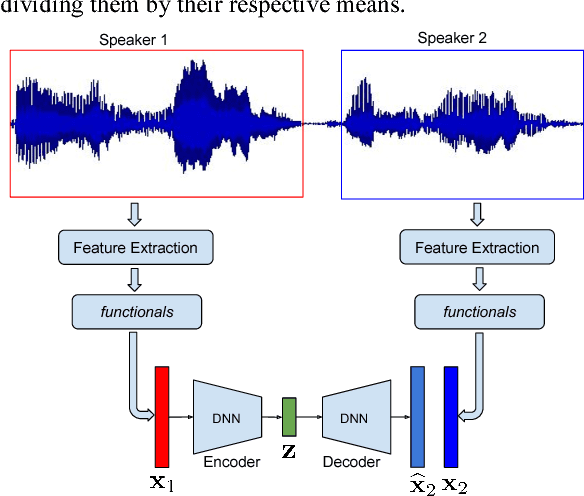
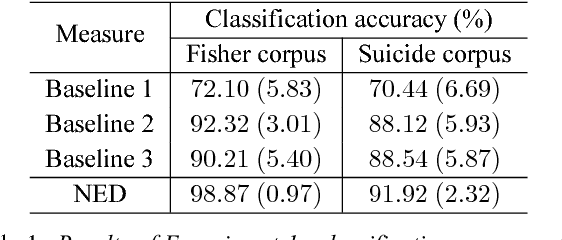
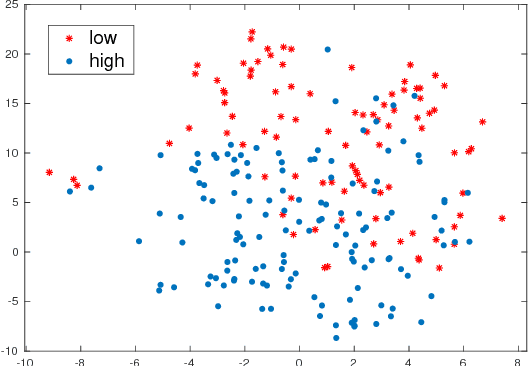
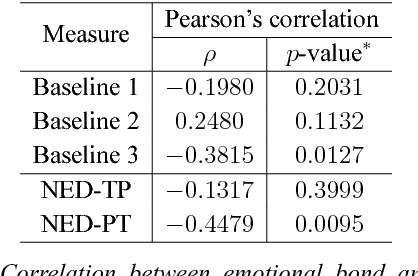
Entrainment is a known adaptation mechanism that causes interaction participants to adapt or synchronize their acoustic characteristics. Understanding how interlocutors tend to adapt to each other's speaking style through entrainment involves measuring a range of acoustic features and comparing those via multiple signal comparison methods. In this work, we present a turn-level distance measure obtained in an unsupervised manner using a Deep Neural Network (DNN) model, which we call Neural Entrainment Distance (NED). This metric establishes a framework that learns an embedding from the population-wide entrainment in an unlabeled training corpus. We use the framework for a set of acoustic features and validate the measure experimentally by showing its efficacy in distinguishing real conversations from fake ones created by randomly shuffling speaker turns. Moreover, we show real world evidence of the validity of the proposed measure. We find that high value of NED is associated with high ratings of emotional bond in suicide assessment interviews, which is consistent with prior studies.
Unsupervised Latent Behavior Manifold Learning from Acoustic Features: audio2behavior
Jan 12, 2017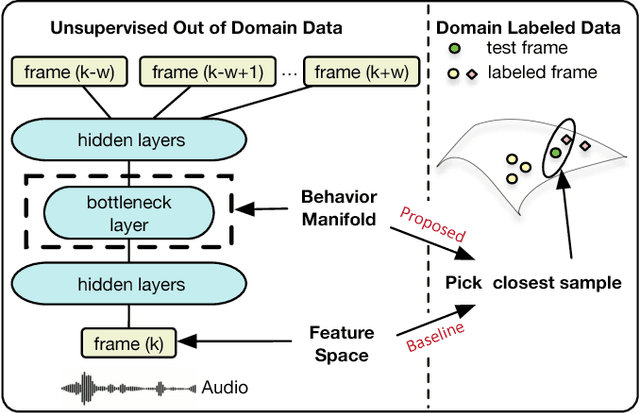

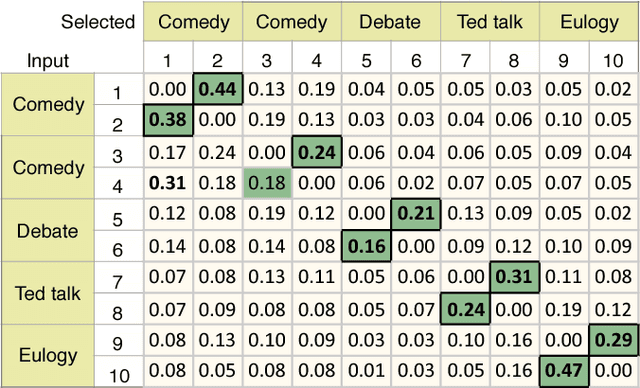
Behavioral annotation using signal processing and machine learning is highly dependent on training data and manual annotations of behavioral labels. Previous studies have shown that speech information encodes significant behavioral information and be used in a variety of automated behavior recognition tasks. However, extracting behavior information from speech is still a difficult task due to the sparseness of training data coupled with the complex, high-dimensionality of speech, and the complex and multiple information streams it encodes. In this work we exploit the slow varying properties of human behavior. We hypothesize that nearby segments of speech share the same behavioral context and hence share a similar underlying representation in a latent space. Specifically, we propose a Deep Neural Network (DNN) model to connect behavioral context and derive the behavioral manifold in an unsupervised manner. We evaluate the proposed manifold in the couples therapy domain and also provide examples from publicly available data (e.g. stand-up comedy). We further investigate training within the couples' therapy domain and from movie data. The results are extremely encouraging and promise improved behavioral quantification in an unsupervised manner and warrants further investigation in a range of applications.
Sparsely Connected and Disjointly Trained Deep Neural Networks for Low Resource Behavioral Annotation: Acoustic Classification in Couples' Therapy
Jun 14, 2016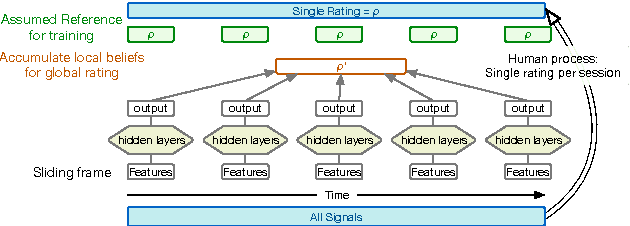
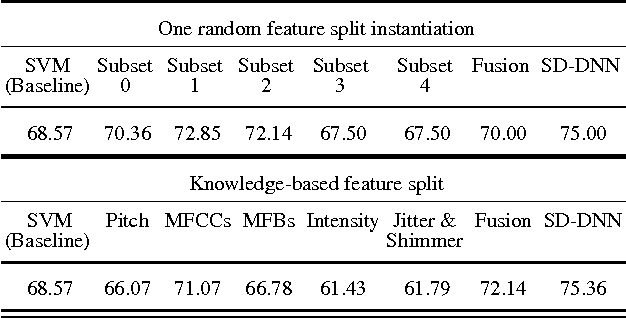
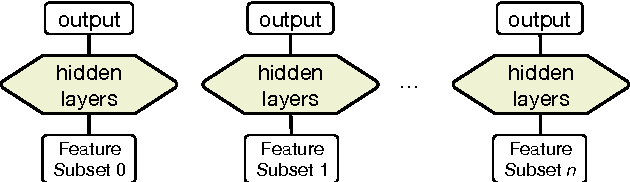

Observational studies are based on accurate assessment of human state. A behavior recognition system that models interlocutors' state in real-time can significantly aid the mental health domain. However, behavior recognition from speech remains a challenging task since it is difficult to find generalizable and representative features because of noisy and high-dimensional data, especially when data is limited and annotated coarsely and subjectively. Deep Neural Networks (DNN) have shown promise in a wide range of machine learning tasks, but for Behavioral Signal Processing (BSP) tasks their application has been constrained due to limited quantity of data. We propose a Sparsely-Connected and Disjointly-Trained DNN (SD-DNN) framework to deal with limited data. First, we break the acoustic feature set into subsets and train multiple distinct classifiers. Then, the hidden layers of these classifiers become parts of a deeper network that integrates all feature streams. The overall system allows for full connectivity while limiting the number of parameters trained at any time and allows convergence possible with even limited data. We present results on multiple behavior codes in the couples' therapy domain and demonstrate the benefits in behavior classification accuracy. We also show the viability of this system towards live behavior annotations.