 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Latent Behavior Manifold Learning from Acoustic Features: audio2behavior
Paper and Code
Jan 12, 2017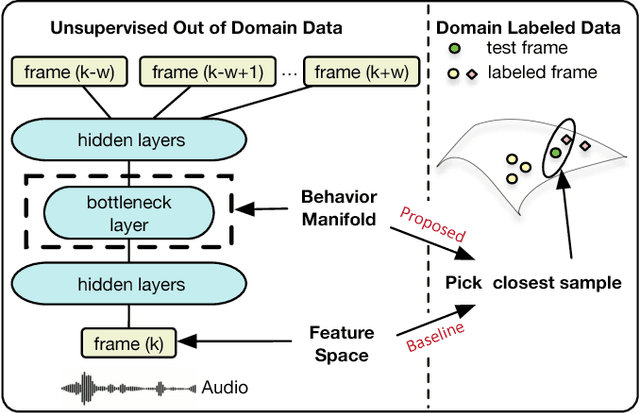

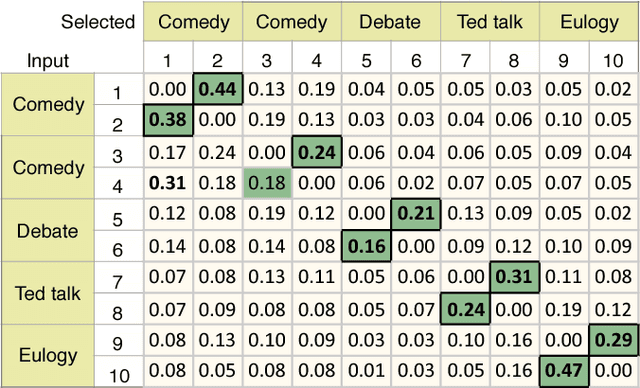
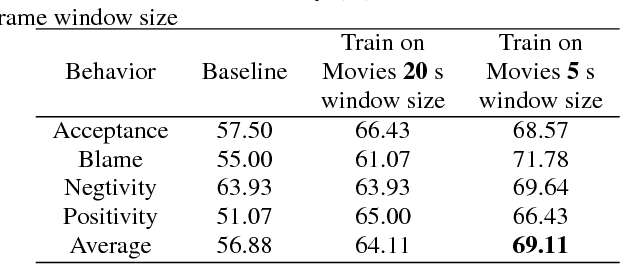
Behavioral annotation using signal processing and machine learning is highly dependent on training data and manual annotations of behavioral labels. Previous studies have shown that speech information encodes significant behavioral information and be used in a variety of automated behavior recognition tasks. However, extracting behavior information from speech is still a difficult task due to the sparseness of training data coupled with the complex, high-dimensionality of speech, and the complex and multiple information streams it encodes. In this work we exploit the slow varying properties of human behavior. We hypothesize that nearby segments of speech share the same behavioral context and hence share a similar underlying representation in a latent space. Specifically, we propose a Deep Neural Network (DNN) model to connect behavioral context and derive the behavioral manifold in an unsupervised manner. We evaluate the proposed manifold in the couples therapy domain and also provide examples from publicly available data (e.g. stand-up comedy). We further investigate training within the couples' therapy domain and from movie data. The results are extremely encouraging and promise improved behavioral quantification in an unsupervised manner and warrants further investigation in a range of applications.