 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiddleGAN: Generate Domain Agnostic Samples for Unsupervised Domain Adaptation
Nov 06, 2022In recent years, machine learning has achieved impressive results across different application areas. However, machine learning algorithms do not necessarily perform well on a new domain with a different distribution than its training set. Domain Adaptation (DA) is used to mitigate this problem. One approach of existing DA algorithms is to find domain invariant features whose distributions in the source domain are the same as their distribution in the target domain. In this paper, we propose to let the classifier that performs the final classification task on the target domain learn implicitly the invariant features to perform classification. It is achieved via feeding the classifier during training generated fake samples that are similar to samples from both the source and target domains. We call these generated samples domain-agnostic samples. To accomplish this we propose a novel variation of generative adversarial networks (GAN), called the MiddleGAN, that generates fake samples that are similar to samples from both the source and target domains, using two discriminators and one generator. We extend the theory of GAN to show that there exist optimal solutions for the parameters of the two discriminators and one generator in MiddleGAN, and empirically show that the samples generated by the MiddleGAN are similar to both samples from the source domain and samples from the target domain. We conducted extensive evaluations using 24 benchmarks; on the 24 benchmarks, we compare MiddleGAN against various state-of-the-art algorithms and outperform the state-of-the-art by up to 20.1\% on certain benchmarks.
Efficient Video Deblurring Guided by Motion Magnitude
Jul 27, 2022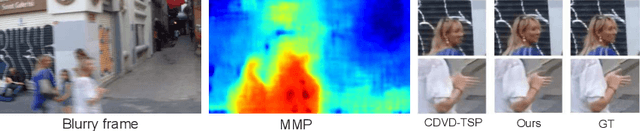


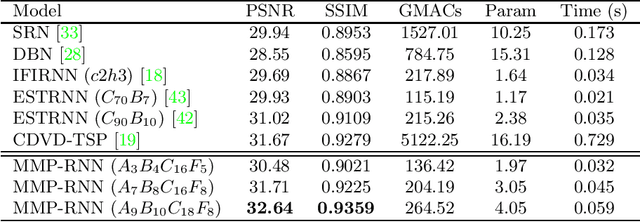
Video deblurring is a highly under-constrained problem due to the spatially and temporally varying blur. An intuitive approach for video deblurring includes two steps: a) detecting the blurry region in the current frame; b) utilizing the information from clear regions in adjacent frames for current frame deblurring. To realize this process, our idea is to detect the pixel-wise blur level of each frame and combine it with video deblurring. To this end, we propose a novel framework that utilizes the motion magnitude prior (MMP) as guidance for efficient deep video deblurring. Specifically, as the pixel movement along its trajectory during the exposure time is positively correlated to the level of motion blur, we first use the average magnitude of optical flow from the high-frequency sharp frames to generate the synthetic blurry frames and their corresponding pixel-wise motion magnitude maps. We then build a dataset including the blurry frame and MMP pairs. The MMP is then learned by a compact CNN by regression. The MMP consists of both spatial and temporal blur level information, which can be further integrated into an efficient recurrent neural network (RNN) for video deblurring. We conduct intensive experiments to validate the effectiveness of the proposed methods on the public datasets.
The Enforced Transfer: A Novel Domain Adaptation Algorithm
Jan 24, 2022
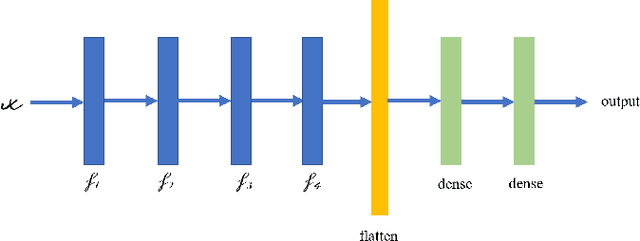
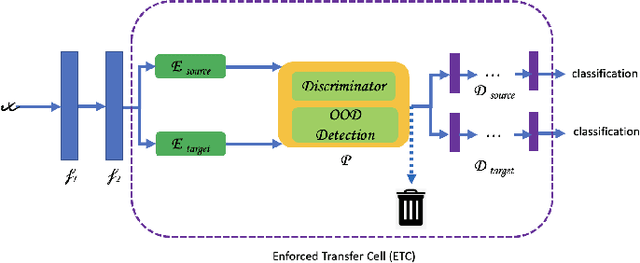
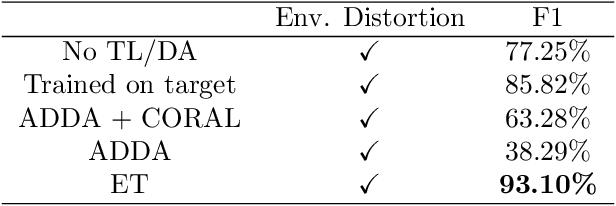
Existing Domain Adaptation (DA) algorithms train target models and then use the target models to classify all samples in the target dataset. While this approach attempts to address the problem that the source and the target data are from different distributions, it fails to recognize the possibility that, within the target domain, some samples are closer to the distribution of the source domain than the distribution of the target domain. In this paper, we develop a novel DA algorithm, the Enforced Transfer, that deals with this situation. A straightforward but effective idea to deal with this dilemma is to use an out-of-distribution detection algorithm to decide if, during the testing phase, a given sample is closer to the distribution of the source domain, the target domain, or neither. In the first case, this sample is given to a machine learning classifier trained on source samples. In the second case, this sample is given to a machine learning classifier trained on target samples. In the third case, this sample is discarded as neither an ML model trained on source nor an ML model trained on target is suitable to classify it. It is widely known that the first few layers in a neural network extract low-level features, so the aforementioned approach can be extended from classifying samples in three different scenarios to classifying the samples' activations after an empirically determined layer in three different scenarios. The Enforced Transfer implements the idea. On three types of DA tasks, we outperform the state-of-the-art algorithms that we compare against.
Efficient Spatio-Temporal Recurrent Neural Network for Video Deblurring
Jun 30, 2021



Real-time video deblurring still remains a challenging task due to the complexity of spatially and temporally varying blur itself and the requirement of low computational cost. To improve the network efficiency, we adopt residual dense blocks into RNN cells, so as to efficiently extract the spatial features of the current frame. Furthermore, a global spatio-temporal attention module is proposed to fuse the effective hierarchical features from past and future frames to help better deblur the current frame. Another issue needs to be addressed urgently is the lack of a real-world benchmark dataset. Thus, we contribute a novel dataset (BSD) to the community, by collecting paired blurry/sharp video clips using a co-axis beam splitter acquisition system. Experimental results show that the proposed method (ESTRNN) can achieve better deblurring performance both quantitatively and qualitatively with less computational cost against state-of-the-art video deblurring methods. In addition, cross-validation experiments between datasets illustrate the high generality of BSD over the synthetic datasets. The code and dataset are released at https://github.com/zzh-tech/ESTRNN.